Nachdem in Deutschland und vielen anderen Ländern über Wochen hinweg die Zahl der bestätigten Corona-Fälle exponentiell gestiegen ist und sich in zwei bis drei Tagen verdoppelt hat, zeigen die Maßnahmen inzwischen deutliche Wirkung: das exponentielle Wachstum konnte auf ein lineares heruntergebremst werden.
Wir sehen uns für ausgewählte Länder den verfügbaren Datensatz an:
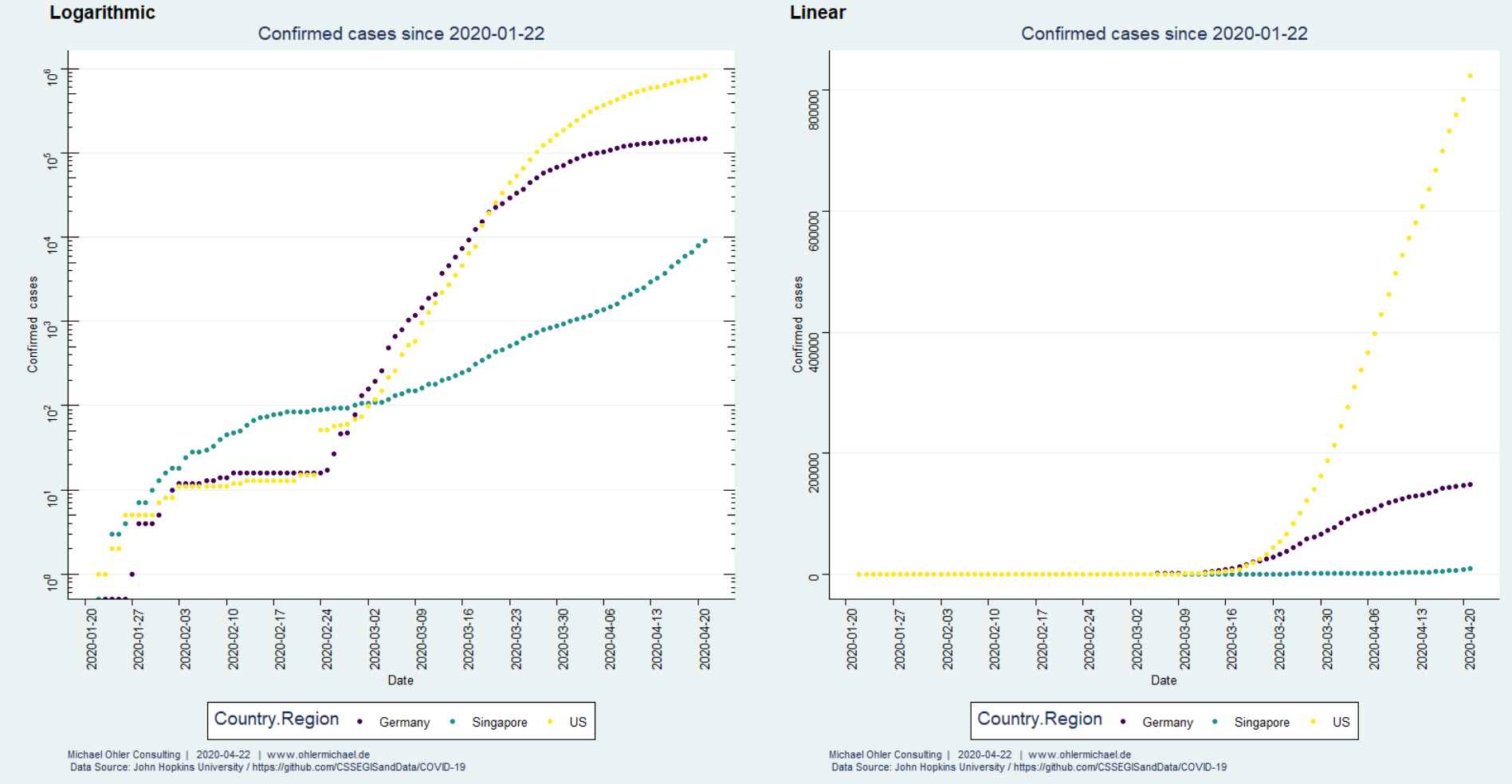
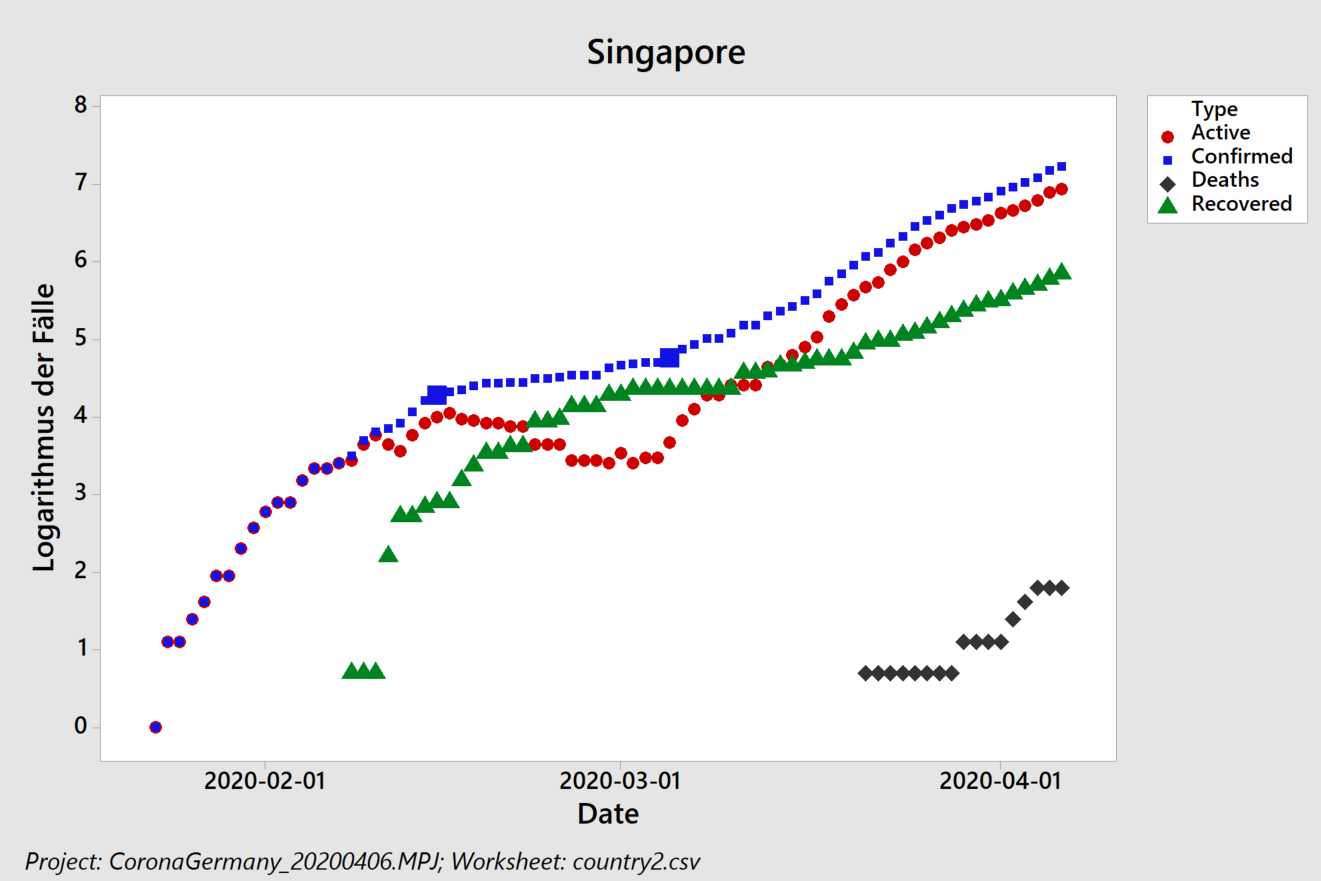
Zunächst fällt auf, dass die Lage in Singapur sich verschlimmert hat – wir hatten den Stadtstaat als „Ausnahmefall“ diskutiert und empfohlen, sich von dort Ideen zu holen. Wie deutsche Zeitungen berichten, ist allerdings inzwischen unter eng zusammenlebenden ausländischen Arbeitskräften Corona erneut ausgebrochen und gelangt von dort auch zur übrigen Bevölkerung.
Am anderen Ende der Skala fällt auf, dass in den USA die bestätigten Fälle ab ca. dem 3. Februar exponentiell angestiegen sind (was in logarithmischer Auftragung zu einer Geraden führt) aber seit ca. dem 27. März linear wachsen.
Wir wollen nun die Ausbreitung von Corona in diesen Ländern miteinander vergleichen. Dazu betrachten wir den Zeitraum ab dem 300sten bestätigten Fall.
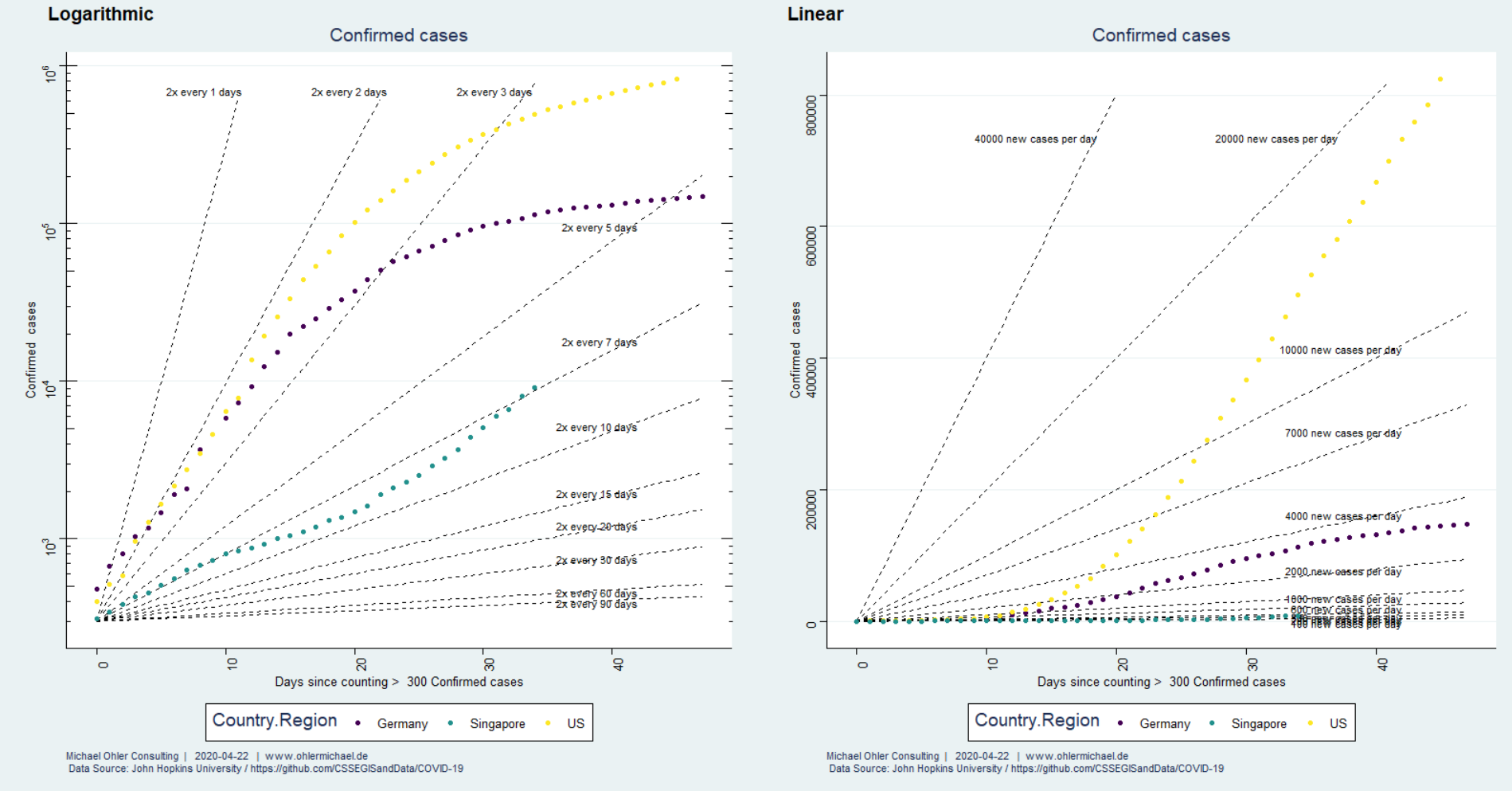
So fällt auf, dass das exponentielle Wachstum in Deutschland und den USA zunächst sehr ähnlich verlief (wie auch in Spanien, Italien und vielen anderen Länder, wir haben das in früheren Beiträgen diskutiert). In Deutschland gelingt es dann jedoch, dieses Wachstum nach ca. 2 Wochen sichtbar zu bremsen. Der Vergleich der rechten und der linken Darstellung erlaubt zu erkennen, über welche Zeiträume hinweg das Wachstum eher exponentiell und wann es linear verläuft. Wir schauen uns diese Dinge unten genauer an.
Vorteile eines linearen Anstiegs der bestätigten Fälle
Bei einem exponentiellen Wachstum mit einer Verdopplungszeit von 3 Tagen haben wir nach 3 Tagen doppelt so viele Fälle, nach 6 Tagen schon viermal so viele, nach neun Tagen achtmal – und so weiter, bis das Gesundheitssystem zusammenbricht.
Für ein lineares Wachstum kommt dagegen jeden Tag in etwa die gleiche Anzahl neuer Fälle hinzu. Die Situation wird dadurch handhabbar, wie man über das Gesetz von Little erkennt: bei 2000 neuen Fällen Tag für Tag und falls Menschen im Mittel 30 Tage lang krank bleiben, dann muss das Gesundheitssystem einen mehr oder weniger konstanten Krankenstand von etwa 2000*30 = 60000 bewältigen. Bei bekanntem Prozentsatz schwerer Fälle lässt sich so nicht zuletzt der Bedarf an Beatmungsgeräten planen. Für ein exponentielles Wachstum steigt dieser Bedarf dagegen exponentiell an.
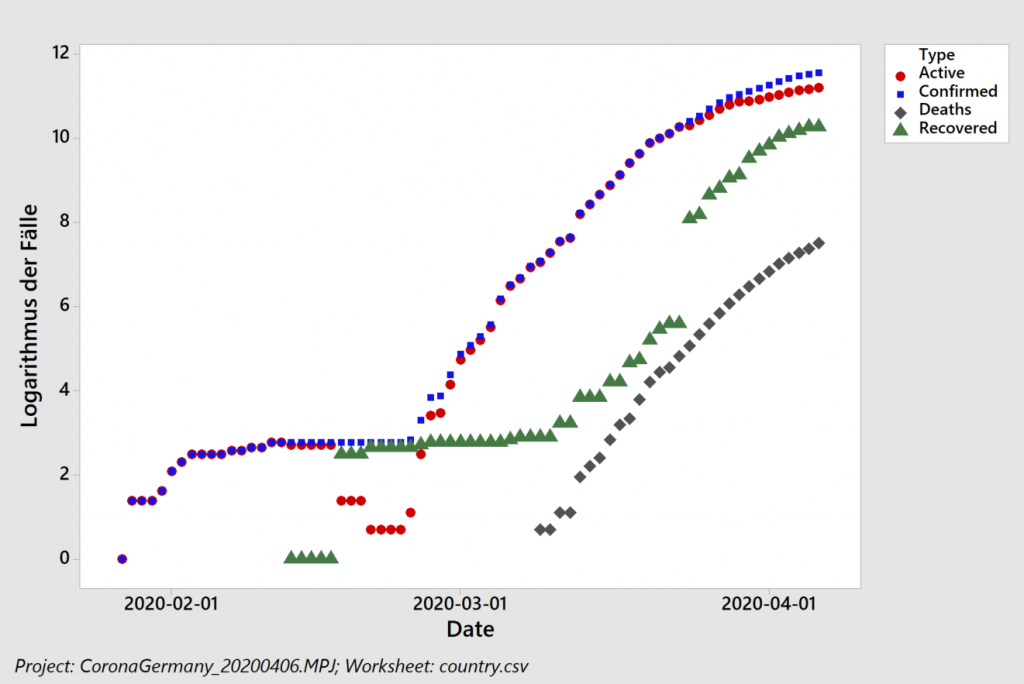
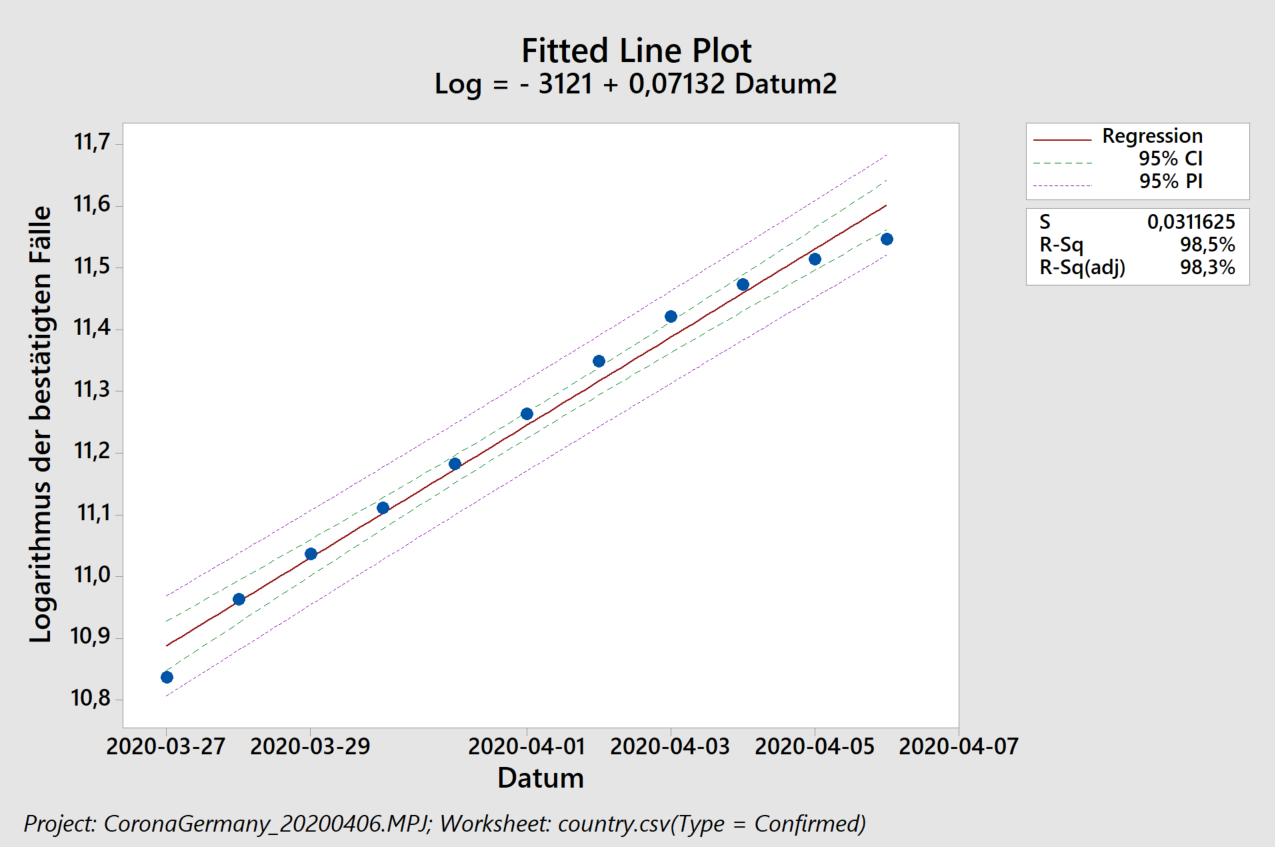
Wie sieht die Lage in Deutschland aus?
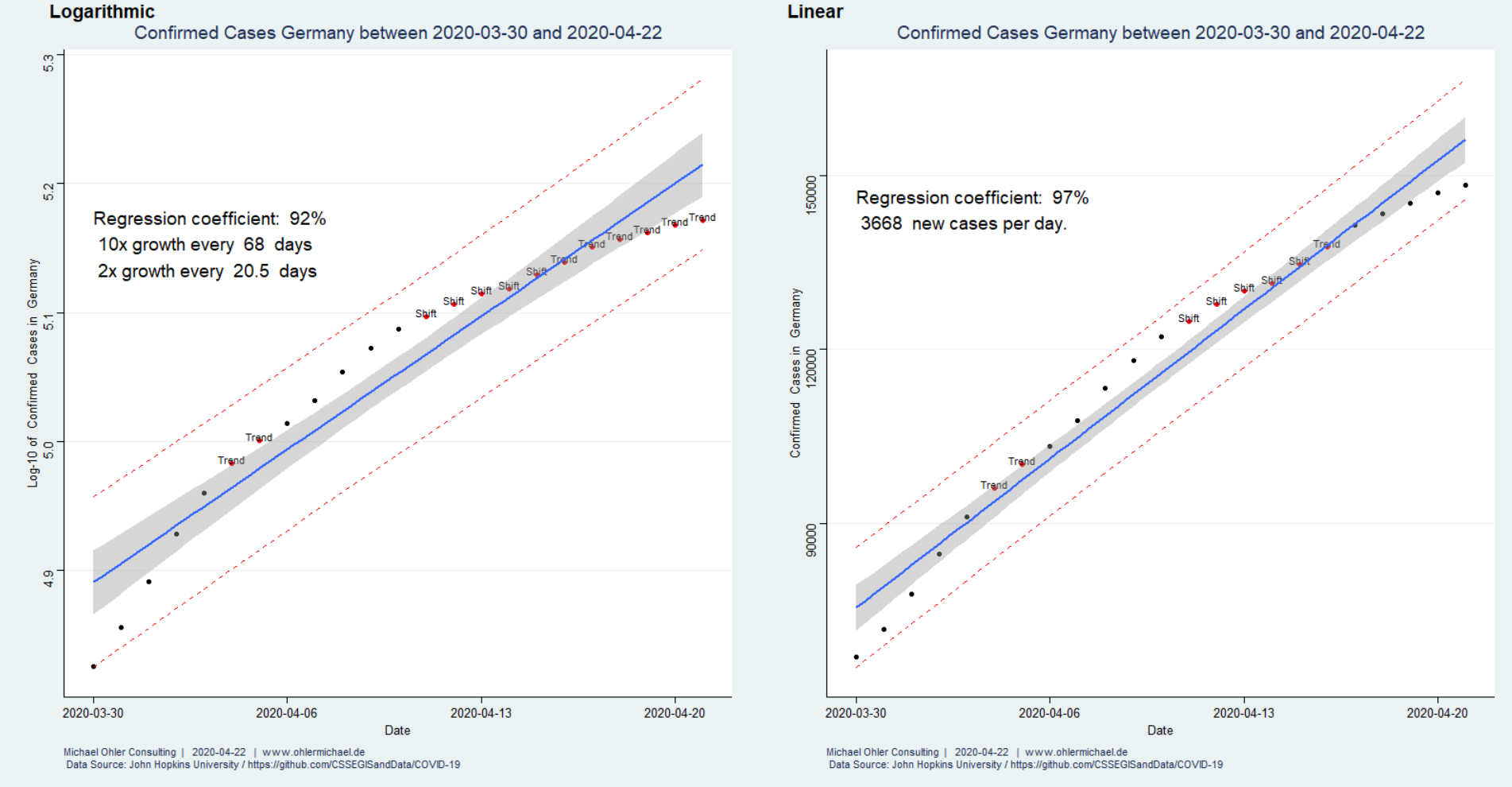
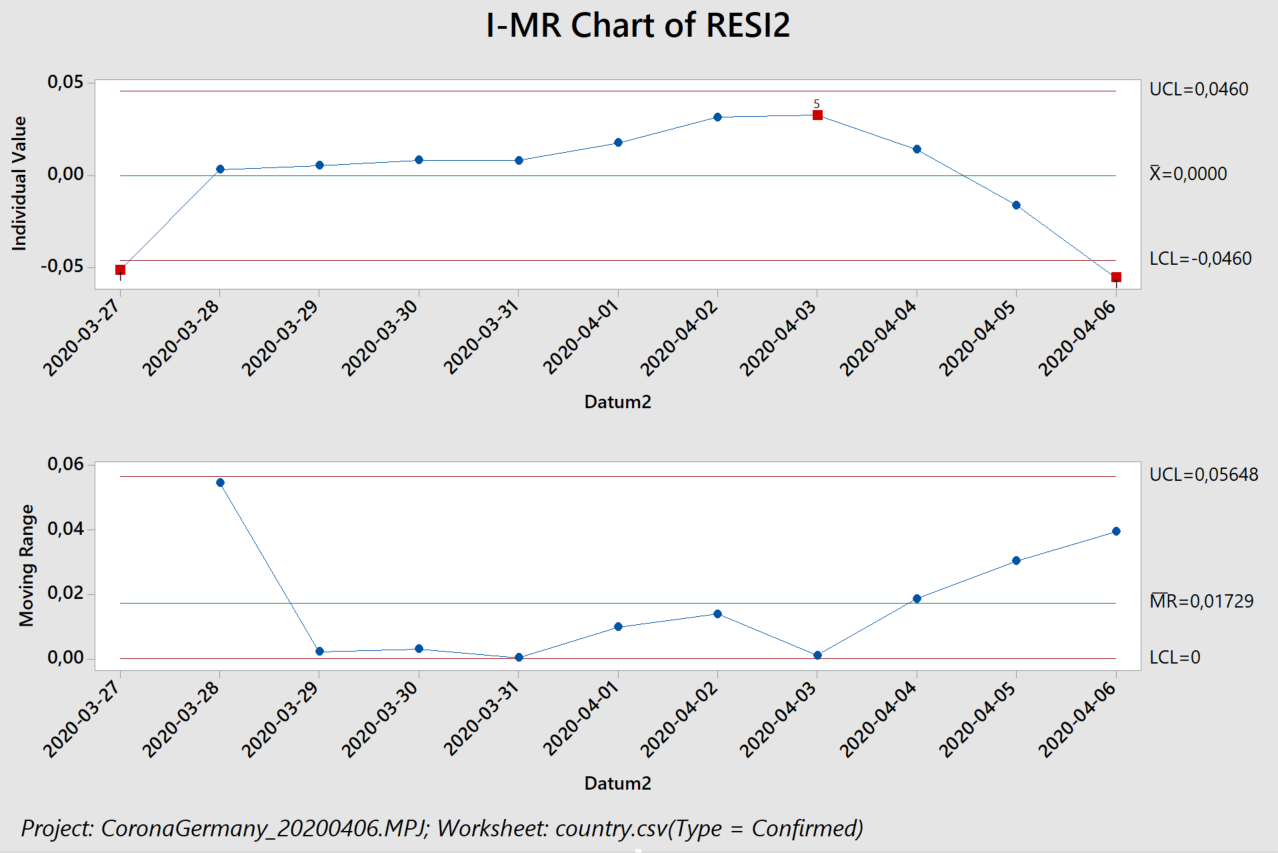
Wir haben die „Western Electric“ oder „Nelson“ Regeln, die wir im letzten Beitrag noch in Minitab verwendet haben, inzwischen in unser R-Programm übertragen (Ayush aus Indien sei Dank dafür, den Fehler in meinem Code gefunden zu haben).
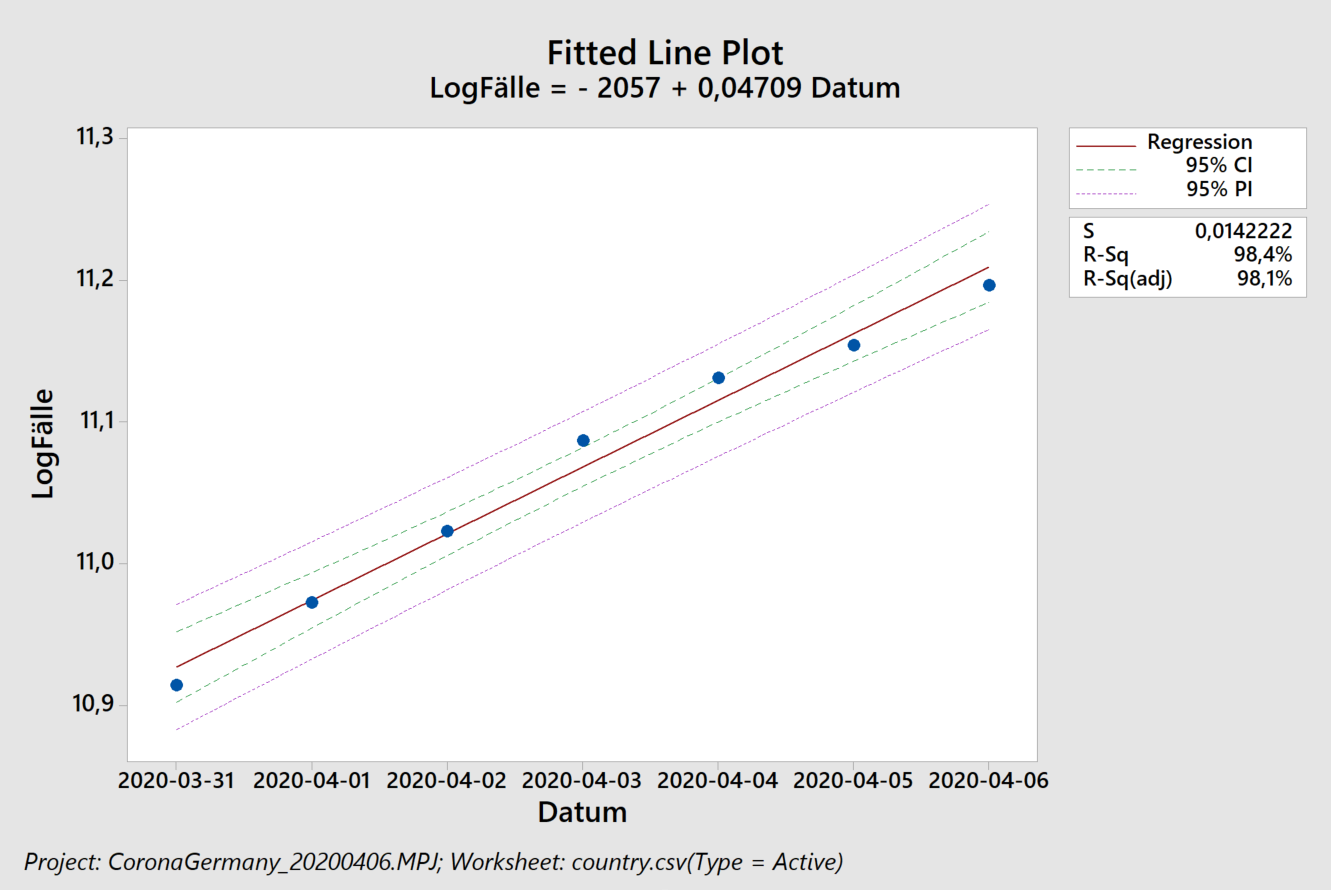
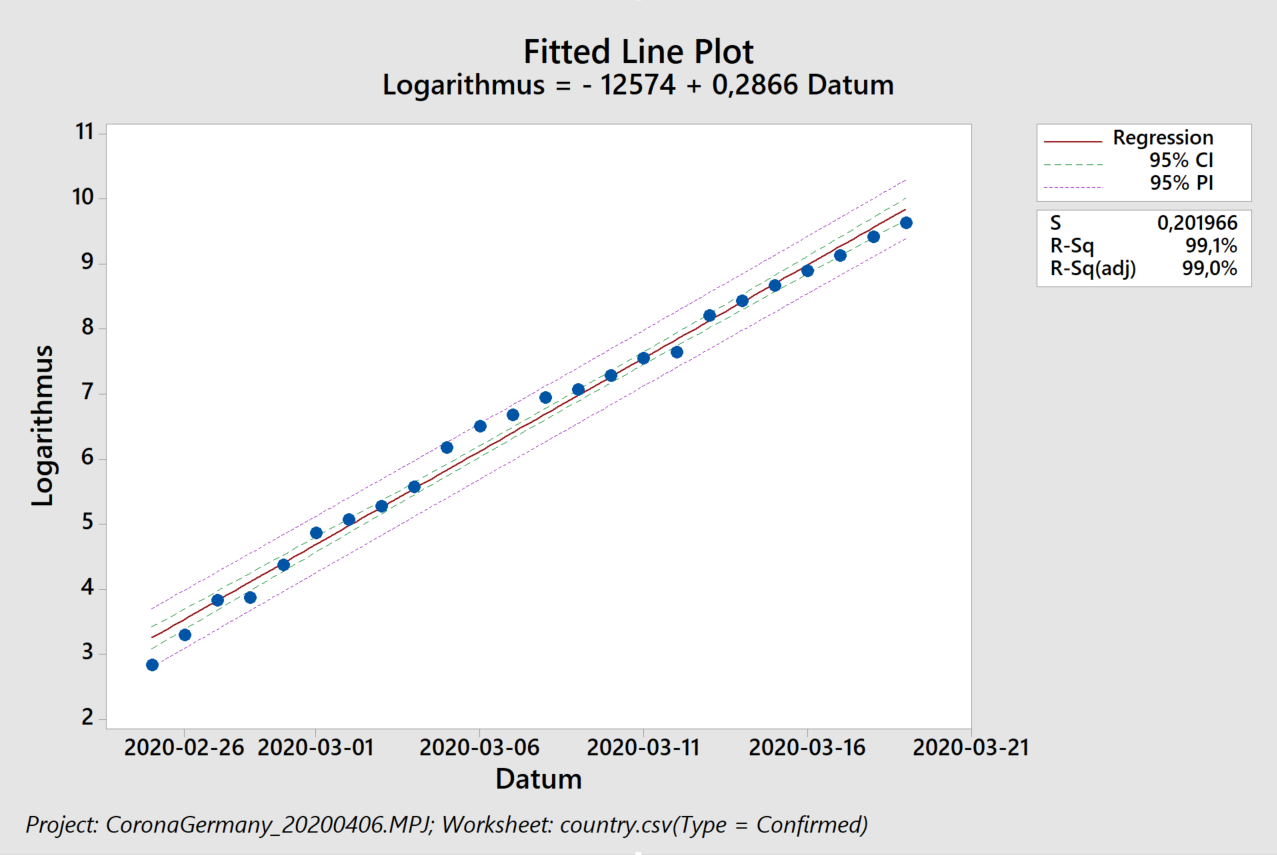
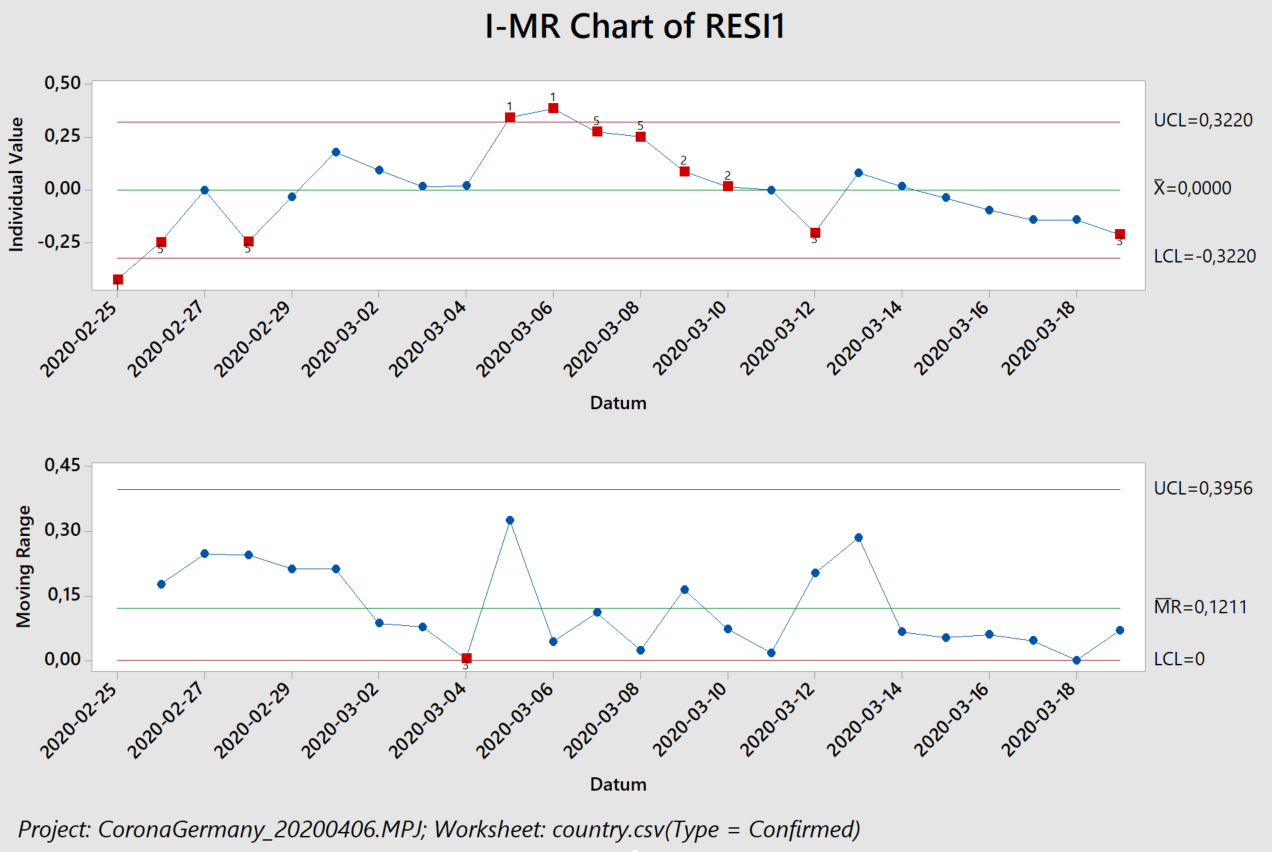
Der Algorithmus erkennt in logarithmischer Auftragung, links, zunächst einen ansteigenden Trend in den Residuen (Abstand zwischen den schwarzen Punkten und der blauen Ausgleichsgeraden). Dieser Trend führ auch zu einer eindeutigen Verschiebung („Shift“) und dann zu einem abfallenden Trend. Das exponentielle Modell beschreibt die Daten also schlecht, was wir auch an einem Regressionskoeffizienten von 92% erkennen. Rein rechnerisch erhält man zwar weiterhin eine Verdopplungszeit (von 20,5 Tagen), sollte diese jedoch nicht für Vorhersagen verwenden, da das zugrunde liegende Modell nicht angemessen ist.
Das lineare Modell, rechts, beschreibt die Daten dagegen besser: nur drei Prozent (100% minus 97%) der beobachteten Streuung stammen nicht von dem linearen Anstieg. Wir erkennen hier jedoch auch ein ähnliches Verhalten der Residuen: selbst das lineare Wachstum ist abgebremst. Die vorhergesagten 3668 neuen Fälle pro Tag stellen also eine Abschätzung nach oben dar. Wenn wir die Zahlen lediglich ab dem 10. April herausgreifen erkennen die Western Electric / Nelson Regeln keine Besonderheiten – und wir erhalten ca. 2500 neue Fälle pro Tag (2474, um genau zu sein – wir haben im Rahmen der Fehlertoleranz gerundet).
Unter Verwendung von Littles Gesetz und einer durchschnittlichen Krankheitsdauer von 30 Tagen schätzen wir für die nähere Zukunft also einen zu erwartenden, mehr oder minder konstanten, Krankenstand von 75000 Menschen in Deutschland ab. Bei den derzeitigen Diskussionen um Lockerungen der Maßnahmen wird diese Zahl mit der Kapazität des Gesundheitssystems verglichen.
Singapur: zurück zu exponentiellem Wachstum
Werfen wir für den gleichen Zeitraum einen Blick nach Singapur:
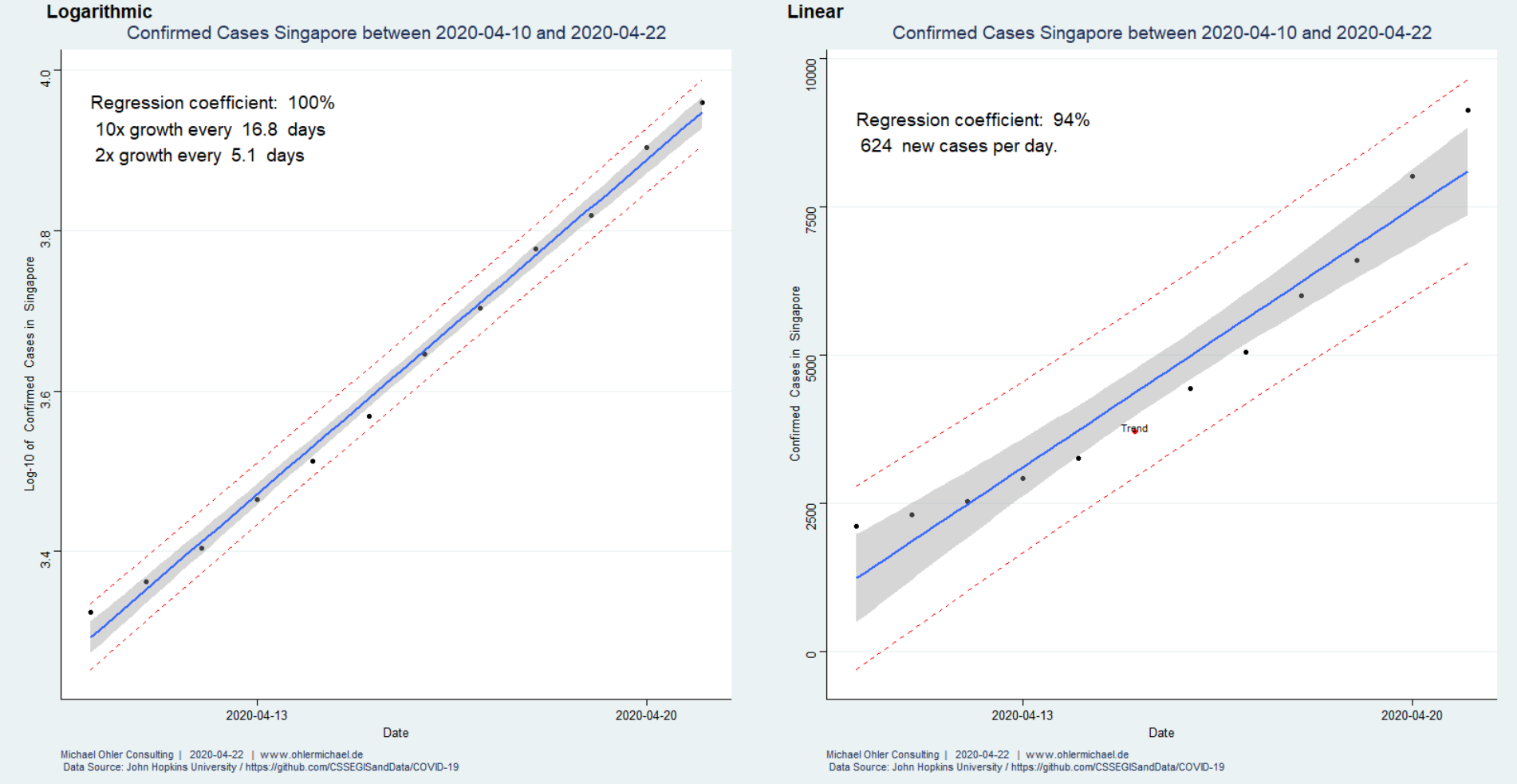
Ein lineares Wachstumsmodell (rechts) führt zu einer „Biegung“ der Residuen, die auch als Trend erkannt wird und somit signifikant ist. Das lineare Modell hat eine Güte von 94% – wohingegen ein logarithmisches Modell links die Zahlen fast perfekt beschreibt (Regressionskoeffizient nahe 100%): Singapur hat derzeit mit einer „zweiten Welle“ und einer Verdopplungszeit von 5,1 Tagen zu tun (wenn auch auf niedrigem Niveau, wie man an den 624 neuen Fällen pro Tag abliest, die das lineare Modell ermittelt). Wenn diese Welle jedoch nicht eingedämmt werden kann, dann ist im Laufe eines Monats (2*16,8) mit hundert Mal so vielen Fällen zu rechnen (Verzehnfachung der Verzehnfachung).
Automatisierte Erkennung von Infektionsherden
Auch in Deutschland wird man die Zahlen im Auge behalten müssen, um solch eine „zweite Welle“ schnell zu erkennen. Untersuchungen, die wir hier für ganze Länder durchführen, können auch regional angewendet werden und so frühzeitig warnen. Mit unserem R-Programm sind wir auch in der Lage, Länder und Regionen nicht nur schnell manuell zu betrachten – es genügt die Änderung eines Eintrages im Quellcode, was in wenigen Sekunden getan ist. Wir können auch Schleifen über mehrere Regionen und Länder durchlaufen, automatisiert modellieren und nach Verletzungen der Nelson-Regeln suchen. Man stelle sich dies vor für alle Postleitzahlen in Deutschland: Infektionsherde lassen sich so sehr schnell erkennen.
Wir sind überzeugt, dass genau dies oder ähnliches derzeit aufgebaut wird: entscheidend dafür sind nämlich gute Zahlen und es gilt, flächendeckend zu testen.
USA: lineares Wachstum mit erschreckend hoher Rate
Für die USA betrachten wir zunächst den Gesamtverlauf:
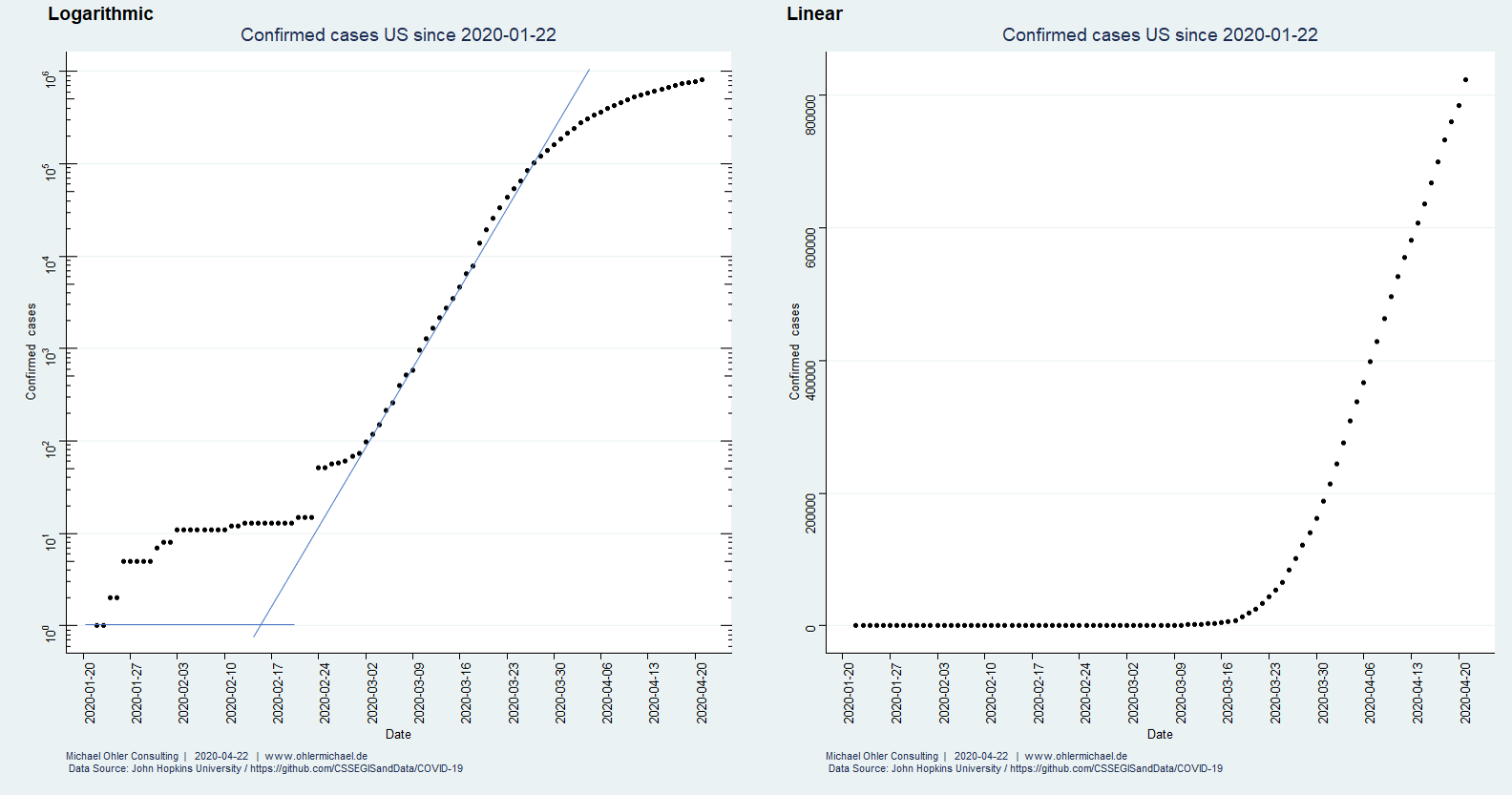
Wir erkennen deutlich den „Weckruf-Knick“ um den 24. Februar herum, ab dem Daten systematisch erfasst werden. Wenn man möchte, dann kann man in der linken, logarithmischen Darstellung das sich anschließende exponentielle Wachstum rückwärts extrapolieren, um den Zeitpunkt der Infektion des „Patienten Null“ zu bestimmen. Wir machen das freihändig (die beiden hinzugefügten Linien) und ermitteln somit den 15. Februar als Datum für den Beginn der Epidemie in den USA.
Ab ca. dem 30. März erscheint das Wachstum nahezu perfekt linear (rechts) und wir schauen uns die Entwicklung mit den nun hinreichend bekannten Statistik-Werkzeugen genauer an:
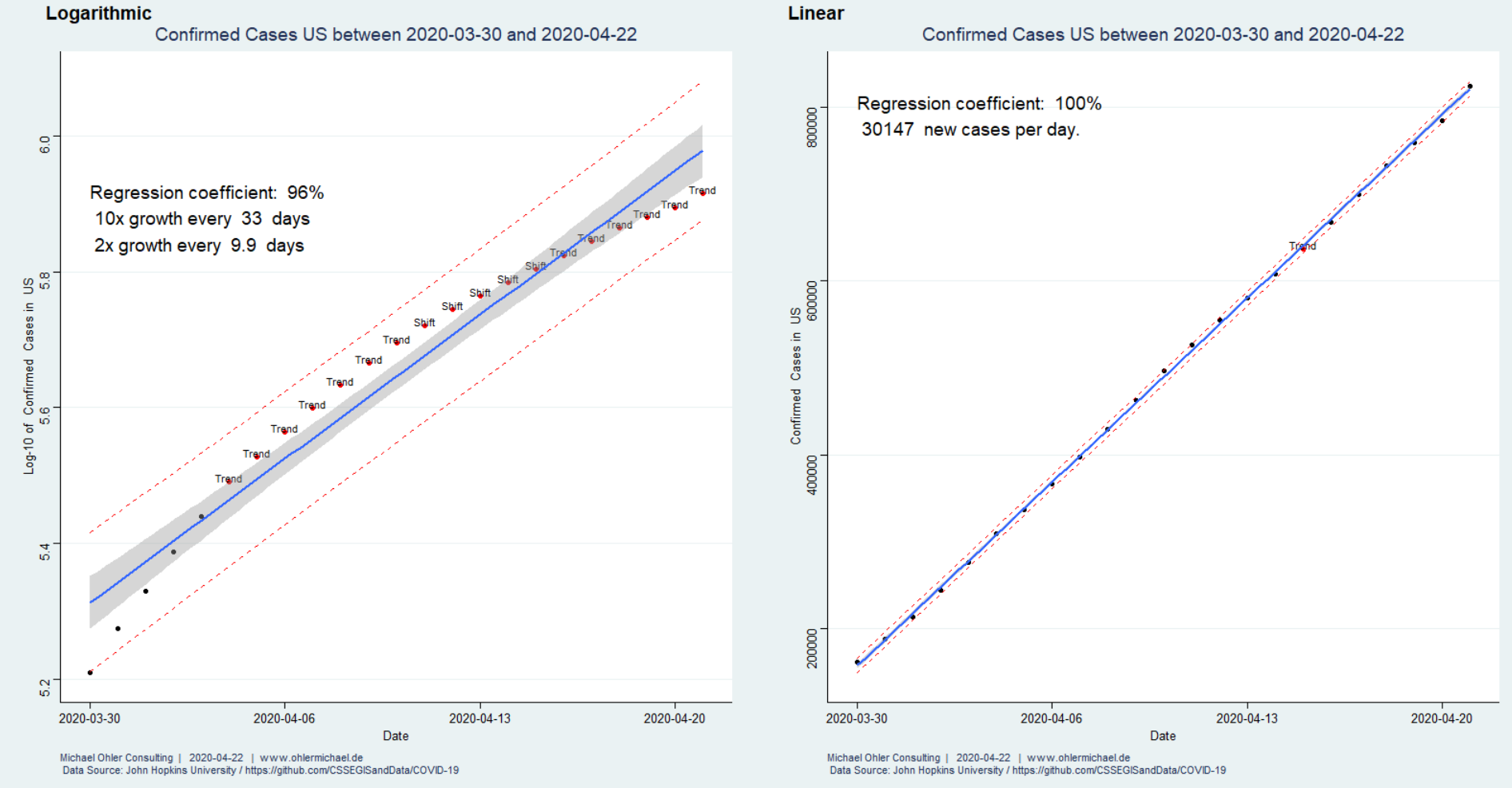
Das exponentielle Modell beschreibt das Wachstum nur unzureichend, was wir nicht nur am Regressionskoeffizienten sondern auch an dem deutlichen Trend in den Residuen erkennen. Das lineare Modell ist hingegen nahezu perfekt. Wir rechnen vorerst weiterhin mit 30000 neuen bestätigten Fällen pro Tag – die Auswirkungen auf das Gesundheitswesen, das Land und die Menschen sind für mich nicht vorstellbar.