
„Deutschland holt viel aus seinem CO2-Ausstoß“
So lautet die Überschrift eines Artikels in der FAZ vom 26. Januar 2023. Zitiert wird eine Auswertung des Instituts für angewandte Arbeitswissenschaften (ifaa). Die Aussagen des Artikels erscheinen so wichtig, dass ich mir das selbst anschauen möchte. Dank der umfangreichen und öffentlich zugänglichen Daten der Weltbank ist das auch Dir leicht möglich. Was mir am Herzen liegt:
Lerne, öffentlich verfügbare Daten „anzuzapfen“
und zu nutzen.
Wenn Du bei Fridays for Future bist, dann werden Leute Deine Aussagen in Frage stellen. Und Du kannst anderleuts Behauptungen überprüfen.
Und wenn Du in der Planungsabteilung Deines Unternehmens sitzt, dann kannst Du, gerade über die Daten der Weltbank, spannende und wichtige Einsichten gewinnen.
Es lohnt sich also. Aber genug gepredigt. Los geht’s.
Wir beschaffen uns die Daten
Es gibt die Möglichkeit, die Weltbank-Daten zu sehr vielen Kennzahlen jeweils einzeln als csv- oder Excel-Datei herunterzuladen und dann „zusammenzukopieren“. Dazu gehst Du auf den jeweiligen Index. Wenn Du allerdings mehrere Indizes miteinander in Beziehung setzen willst, dann ist das mühsam und nicht zuletzt auch fehleranfällig. Wir schreiben uns deshalb eine Routine in R:
# Zugang zu allen Daten der Weltbank
library(WDI)
# Indizes, die uns hier interessieren:
indicators <-
c("EN.ATM.CO2E.PC",
"EN.ATM.CO2E.KT",
"NY.GDP.MKTP.CD",
"NY.GDP.PCAP.PP.CD",
"NY.GDP.MKTP.PP.CD",
"SP.POP.TOTL")
# Indizes laden:
indicatortable <- WDI(indicator = indicators,
extra = TRUE)
Das war’s!
Wenn Du Deine Daten bequem herunterladen möchtest, dann brauchst Du nur diese wenigen Zeilen soweit zu verstehen, dass Du sie für Deine Zwecke anpassen kannst. Die Daten der Tabelle indicatortable kannst Du auch in eine csv-Datei schreiben und von dort aus mit der Software Deiner Wahl weiter arbeiten. Wir halten fest:
Mit drei Befehlen hast Du Zugriff auf sämtliche Weltbankdaten.
Die Datensind je Land und Jahr abgelegt. Das vorhergehende Skript lädt folgende Indizes herunter (hier mit der Original-Bezeichnungen der Weltbank):
- CO2 emissions (metric tons per capita)
- CO2 emissions (kt)
- GDP (current US$)
- GDP per capita, PPP (current international $)
- GDP, PPP (current international $)
- Population, total.
Datenaufbereitung
Mit meiner Abfrage erhalte ich eine indicatortable im Umfang von 16492 Zeilen und 18 Spalten für Daten der Jahre von 1960 bis 2021. Diese gilt es nun zu „säubern“, denn es fehlen einige Einträge. Ich zähle diese „missing values“ und stelle fest, dass für die Jahre 2020 und 2021 die Daten mancher Länder noch nicht vorliegen. Auch im Jahr 2019 liegen manche Einträge von Ländern mit insgesamt ca. 2% der Weltbevölkerung ebenfalls nur unvollständig vor. Die Details erspare ich Dir hier. Diese Länder nehme ich jedenfalls aus meinen weiteren Betrachtungen heraus. Letztlich läuft meine Datenaufbereitung also auf folgende Zeilen hinaus. Ich füge dabei auch die „CO2-Effizienz“ der Volkswirtschaften als neue Spalten an:
y2019 <- indicatortable %>%
filter(year == 2019)
y2019 <- y2019[complete.cases(y2019), ]
# Wir berechnen die Wirtschaftsleistung je Tonne CO2.
# In Kaufkraftparität (PPP) und in aktuellem Dollar (CD):
y2019 <- y2019 %>%
mutate(GDP.PP.per.CO2E.T =
y2019$NY.GDP.MKTP.PP.CD/y2019$EN.ATM.CO2E.KT/1000, # PPP
GDP.CD.per.CO2E.T =
y2019$NY.GDP.MKTP.CD/y2019$EN.ATM.CO2E.KT/1000) # CD
Anders als der Artikel in der FAZ möchte ich die Wirtschaftsleistung (gemessen über das Bruttosozialprodukt) auch kaufkraftparitätisch betrachten können. Das erlaubt die Frage, wie gut eine Volkswirtschaft ihre CO2-Emissionen mit Blick auf die Kaufkraft der eigenen Bevölkerung einsetzt.
Die größten CO2-Emittenten im Jahr 2019
Wir sortieren nun die Tabelle y2019 nun nach den CO2-Emissionen, wählen die ersten 10 Länder aus und fügen eine Zeile an mit der Summe aller anderen Länder. So entsteht folgende Graphik:
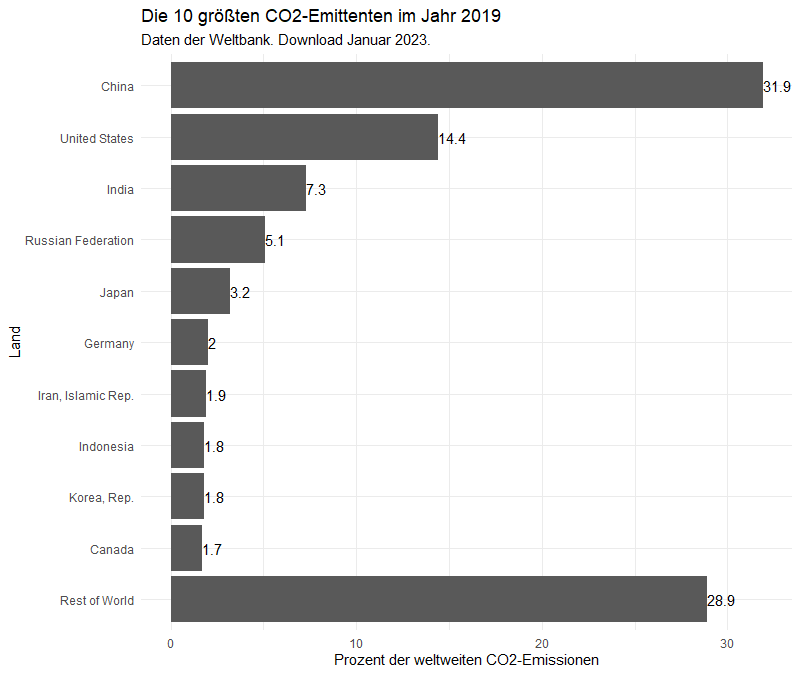
Im Vergleich zu der im FAZ-Artikel weist diese Graphik kleine Unterschiede auf – vermutlich, weil dem ifaa aktuellere und deshalb andere Daten vorliegen. Die Aussagen des Artikels kann ich jedoch reproduzieren:
- Allein China ist für ca. 30% der weltweiten CO2-Emissionen verantwortlich
- Die zehn größten Emittenten weltweit tragen über 70% bei
- Die deutschen Emissionen schlagen mit ca. 2% zu Buche.
Größte Emittenten, nach CO2-Emissionen pro Kopf
Nun wirst Du zurecht sagen, dass in China viele Menschen leben. Kein Wunder sozusagen, das Monaco in dieser Liste nicht auftaucht. So gesehen stößt Du tatsächlich auf Länder mit sehr hohen pro-Kopf-Emissionen. Die entsprechende Übersicht kannst Du Dir bei Interesse leicht selbst erstellen. Ich möchte meine Untersuchung auf die größten 30 Emittenten beschränken. Dafür verwende ich folgenden Code:
plotdat <- y2019 %>%
arrange(desc(EN.ATM.CO2E.KT)) %>%
slice(1:30) %>%
arrange(desc(EN.ATM.CO2E.PC))
ggplot(data = plotdat,
aes(x = EN.ATM.CO2E.PC, y = country)) +
geom_bar(stat = "identity")
In diesem „Snippet“ siehst Du lediglich die wesentlichen Zeilen: wir sortieren zunächst absteigend nach den CO2-Emissionen, entnehmen dann die ersten 30 Einträge und sortieren diese nach den CO2-Emissionen pro Kopf. Diese Ergebnisse werden in einem Balkendiagramm zusammengetragen. Zur „Verschönerung“ habe ich noch einige Formatierungsanweisungen hinzugefügt. Ein aussagekräftige Graphik erhältst Du aber auch schon mit den obigen Zeilen.
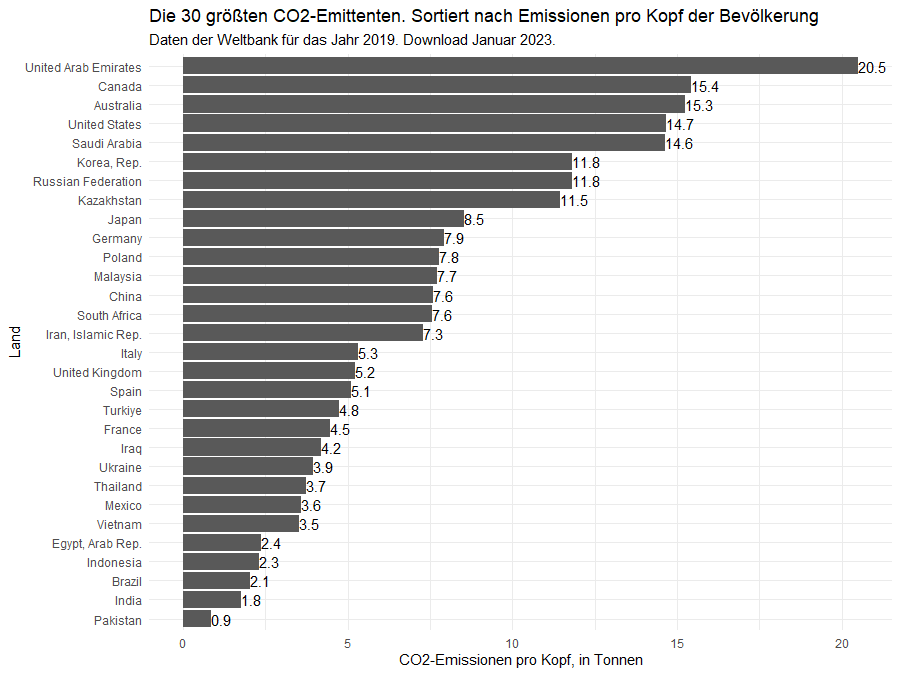
Wir sehen große Diskrepanzen zwischen den Ländern. So emittiert zum Beispiel Indien, das immerhin auf Platz drei der weltweiten Emissionen liegt, pro Kopf der Bevölkerung 1,8 Tonnen CO2. Für die Vereinigten Arabischen Emirate hingegen liegt der Wert mehr als zehn mal so hoch.
„Klimaeffizienz“ der Wirtschaft
Es liegt deshalb nahe, die CO2-Emissionen nicht nur auf die Bevölkerungszahl sondern auch auf die Wirtschaftsleistung zu beziehen. Der Ansatz des ifaa besteht nun darin, das Bruttosozialprodukt durch die CO2-Emissionen zu teilen. Das ermöglicht eine Aussage darüber, welche Wirtschaftsleistung je eingesetzte Tonne CO2 erbracht wurde.
Wir sortieren dafür zunächst alle Länder nach dieser „Klimaeffizienz“ und greifen die ersten 30 Einträge heraus. Die Skriptzeilen sehen analog zu denen oben aus und ich lasse sie deshalb hier weg. So erhalten wir folgende Graphik:
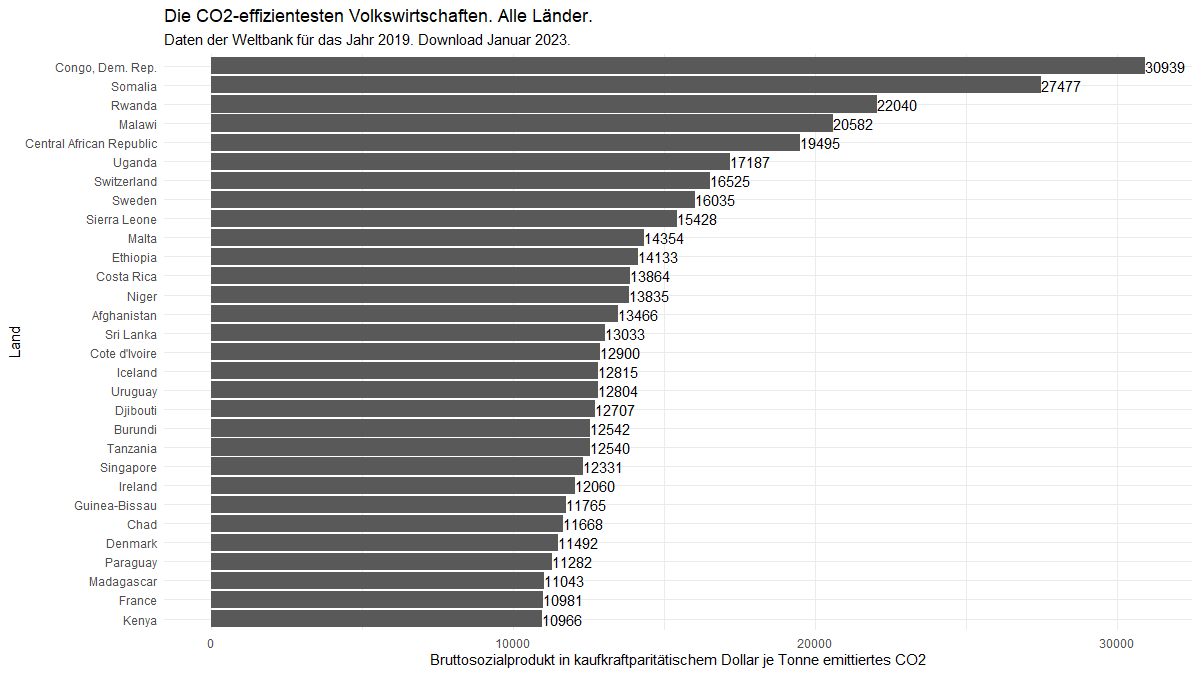
Das Ergebnis ist bedrückend: die Demokratische Republik Kongo hat sich bestimmt nicht „absichtlich“ so aufgestellt, dass wenig CO2 eingesetzt wird, um ihr Bruttosozialprodukt zu erwirtschaften. In Anlehnung an den Artikel aus der FAZ wiederhole ich deshalb diese Betrachtung für die 10 größten Emittenten (siehe oben). Hierfür passe ich die oben gezeigten Skriptzeilen an und erhalten folgende Graphik:
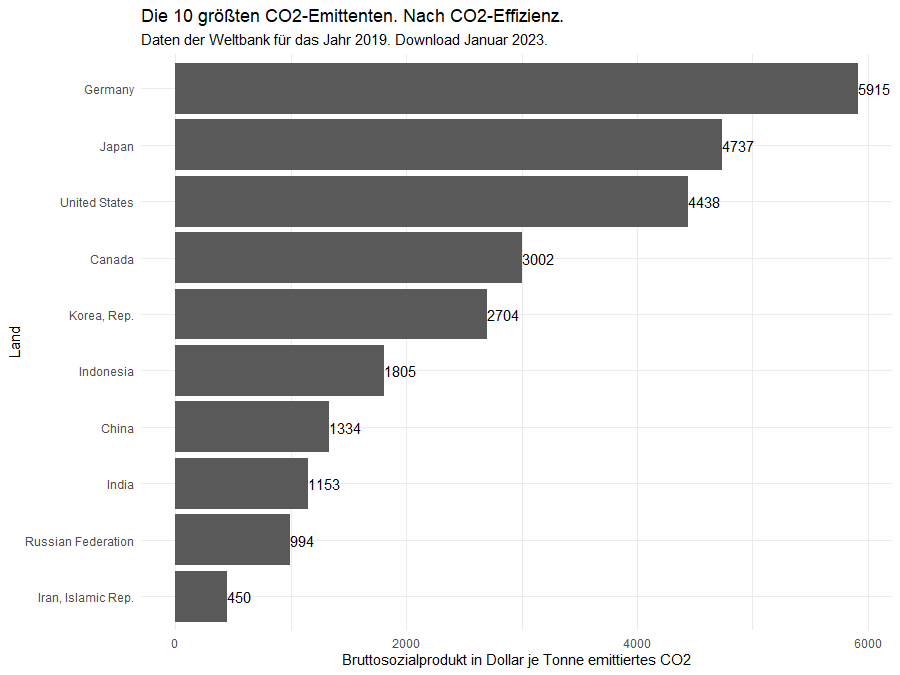
Wir finden hier eine Kernaussage aus dem FAZ-Artikel (die Rangfolge und die Werte hier unterscheiden sich dabei aus genannten Gründen leicht von denen des FAZ-Artikels):
Unter den zehn größten CO2-Emittenten produziert die deutsche Wirtschaft das höchste Bruttosozialprodukt je eingesetzte Tonne CO2.
Diese Aussage hängt allerdings auch davon ab, wie viele der größten Emittenten ausgewählt werden. Solange wir die größten 16 oder weniger wählen steht Deutschland tatsächlich an der Spitze. Das Bild sieht jedoch anders aus, wenn man die ersten 20 betrachtet:
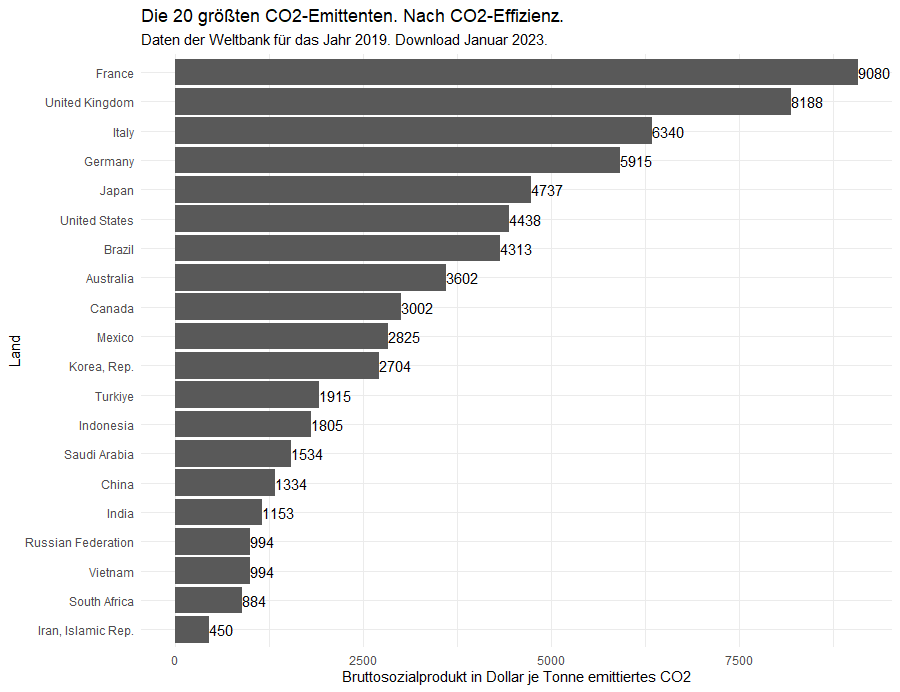
Nun rückt Frankreich auf Platz 1, dank des Einsatzes von Atomkraft, und Deutschland liegt abgeschlagen auf Platz 4 hinter dem Vereinigten Königreich und Italien.
Du erkennst eine Tatsache, die im Unternehmensalltag hinreichend bekannt ist – und hoffentlich entsprechend berücksichtigt wird:
Beim Vergleich von Ländern, Geschäftseinheiten und vor allem von Menschen anhand von Kennzahlen ist große Vorsicht geboten.
Kaufkraftparitätische Klimaeffizienz
So vorsichtig geworden könntest Du nun auch sagen:
„Warte mal: Man darf doch nicht all diese Wirtschaften über den gleichen Kamm scheren!“
Und das ist richtig: Ein Dollar in Indien hat eine andere Kaufkraft als ein Dollar in den USA. Wir wiederholen also die vorherige Auswertung für die 10 größten Emittenten mit Blick auf das kaufkraftparitätische Bruttosozialprodukt:
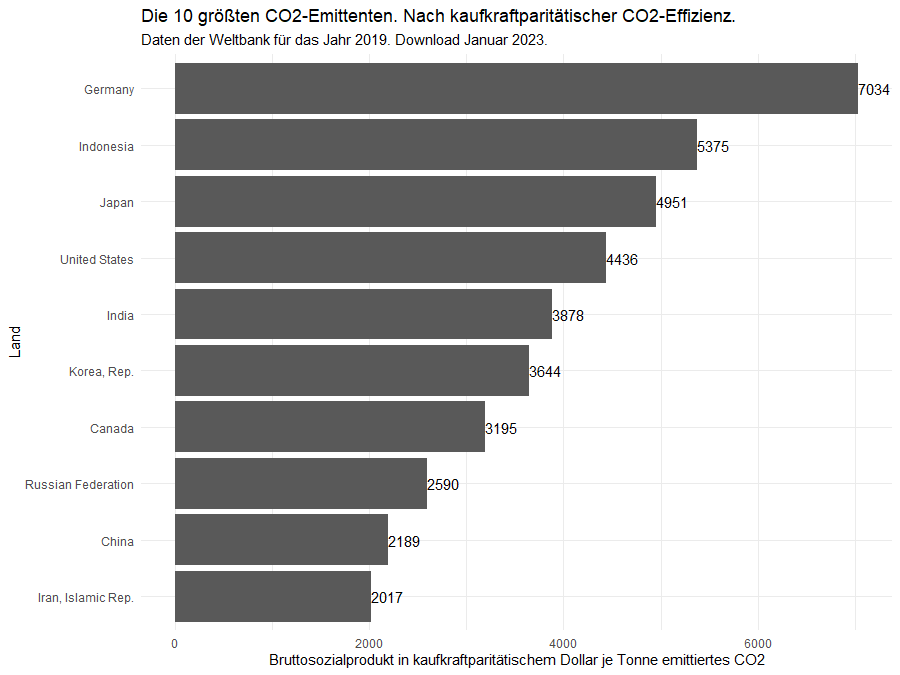
Deutschland bleibt hier auf Platz 1, gefolgt nun allerdings von Indonesien. Japan und die USA rücken jeweils um einen Platz nach hinten und Indien schließt um drei Plätze nach vorne auf.
Meine Botschaft für Dich
- „Daten sind das neue Öl“ heißt es. Das stimmt nicht ganz, denn Öl gibt es nicht umsonst. Daten dagegen sind häufig frei verfügbar oder zumindest „günstig zu haben“: Im Internet oder in Deinem Unternehmen. Diese „freie Ressource“ nicht zu nutzen ist zunehmend nicht nur schade sondern, je nach Deiner Rolle, fast schon „sträflich“.
- Bekannt ist auch der Spruch: „Glaube keiner Statistik, die du nicht selbst gefälscht hast“. Das ist sarkastisch und letztlich schädlich, denn Du würdest Deine Augen vor wichtigen Erkenntnissen verschließen. Entscheidend ist vielmehr, dass Du selbst mit den Daten „spielen“ und die „Stabilität“ von Aussagen überprüfen kannst. So wie die Auswahl der 10 oder 20 größten CO2-Emittenten oben.
- Du hast hier auch ein Beispiel gesehen, welchen Einfluss Du mit Daten gewinnen kannst. Mit Graphiken kannst Du Deinen Daten Einsichten entlocken und so wichtige und manchmal überraschende Botschaften vermitteln. Du kannst auch anderleuts Botschaften relativieren oder in einen größeren Zusammenhang stellen.
- Die Zeiten von „Excel & Co“ sind meiner Ansicht nach vorbei. Für die Datengewinnung, -aufbereitung und -darstellung brauchst Du, behaupte ich, zunehmend Skripte. Sonst kommst Du einfach nicht mehr hinterher. Deine Produktivität bleibt niedrig, da Du alles „per Hand“ manchen musst. Das macht Deine Auswertungen fehleranfälliger. An manche Daten kommst Du zudem ohne Skript auch nur schwer heran. Daten kommen auch in vielen Strukturen daher. Skripte sind flexibel. Lerne also R oder Python.
- Das ist kein Hexenwerk. Siehe die Beispiele oben. Natürlich steckt der Teufel im Detail. Aber für das Debugging gibt es zunehmend richtig gute Hilfe. Ich verwende inzwischen fast ausschließlich ChatGPT. Stackoverflow tritt in den Hintergrund. Und das ist nur der Anfang einer langen, vermutlich wirklich langen Geschichte…
Ich habe übrigens versucht, mein R-Skript in die „Medienbibliothek“ einzubinden, sodass ich es Dir hier zur Verfügung stellen kann. Aus Sicherheitsgründen verhindert WordPress das jedoch: kennen die die Extension .R nicht? Wie auch immer: wenn Du das Skript haben möchtest, dann schreibe mich einfach über LinkedIn an. Meinen Kontakt findest Du auch mit einer einfache Internetsuche. Da ich meinen Spamfilter nicht ständig neu trainieren möchte, will ich hier meine Emailadresse nicht den neugierigen Augen der Crawler preisgeben.