
Warum Du diesen Blog lesen solltest
Wenige Themen werden in der letzten Zeit so heiß diskutiert, wie das Klima. Das ist gut: als Gesellschaft müssen wir über die wichtigen Themen sprechen und brauchen eine Kultur der Debatten. Dabei lohnt es sich, auch einmal andere Länder unter die Lupe zu nehmen und zu schauen, was dort schon erreicht wurde.
In diesem Blog erfährst Du, wie Du selbst solche Vergleiche anstellen und danach gezielt nach Ländern suchen kannst, die Dich interessieren.
„Traue nur den Statistiken, die Du verstehst“
Ich möchte noch einmal auf meinen Beitrag vom Januar zurückkommen. Wir hatten damals gesehen:
- Ein interessantes Maß für die Klimaeffizienz einer Volkswirtschaft ist das Bruttosozialprodukt, das je Kilogramm eingesetztes CO2 erwirtschaftet wird.
- Es ist dabei sinnvoll, sowohl das absolute als auch das kaufkraftparitätische Bruttosozialprodukt zu betrachten.
- Welches Land als „Sieger“ abschneidet hängt davon ab, wie viele der größten CO2-Emittenten in die Untersuchung einbezogen werden.
- Wenn wir die 10 größten Emittenten betrachten, dann steht Deutschland vorn, unter den 20 größten schneidet Frankreich am besten ab.
Solche Ergebnisse erscheinen zwar interessant, laufen aber auf ein „es kommt halt darauf an“ hinaus und sind somit letztlich unbefriedigend. Vor allem möchte ich die Schlussfolgerung vermeiden, man solle keiner Statistik trauen, „die man nicht selbst gefälscht hat“. Denn worauf wollen wir uns bei wichtigen Themen sonst verlassen, wenn nicht auf wissenschaftliche Erkenntnisse und Statistiken?
Deshalb heute ein neuer Anlauf – mit einigen, so finde ich, interessanten Einsichten.
Um die Ergebnisse vorweg zu nehmen
- Wenn Ihr mich fragt, dann ist die Schweiz Klimaweltmeister.
- Dänemark hat über die letzten 30 Jahre seine Klimaeffizienz am meisten, nämlich um 440% gesteigert.
- Es lohnt sich auch, in Frankreich, England und den nordischen Ländern (Schweden, Norwegen, Island, Irland) zu schauen, was sich dort über Klimaeffizienz lernen lässt
- Ein Blick nach Singapur kann wichtige Einsichten geben, wenn es darum geht, Großstädte klimaeffizient zu gestalten und
- der Stimme Brasiliens sollte im Klimakonzert das Gehör gegeben werden, das das Land sich als einer der „Gruppensieger“ verdient hat.
Wenn Du das nachprüfen möchtest, dann findest Du am Ende die wesentlichen Code-Zeilen dafür.
Wir verwenden R für unsere OSAN-Analysen
Wir betreiben „Open Source Analytics“ (OSAN) und verwenden dafür frei verfügbare Datenquellen und die Skript-, Berichts- und Webapplikationssprache R, die speziell für die Handhabung von Daten, Texten und Bildern entwickelt wurde. Du kannst Sie kostenfrei installieren. Sprachen wie R und auch Python bieten Dir viele Vorteile, zum Beispiel diese:
- Du hast auf einen Schlag Zugang zu den neuesten und besten Analysewerkzeugen inklusive Dokumentation. Du kannst Dich auch bequem von „generativer“ künstlicher Intelligenz wie ChatGPT bei der Erstellung Deines Skripts coachen lassen.
- Du kannst Deine Analysen ständig aktuell halten: Einmal „Run“ gedrückt und schon lädt Dein Skript wieder die neuesten Daten herunter und wertet sie für Dich aus.
- Als Team ist Eure Lernkurve steiler: Anders als bei „Klicksoftware“ kannst Du Dein Vorgehen inklusive aller „Tricks und Kniffe“ in Deinem Skript festhalten. So könnt Ihr beste Praktiken leicht untereinander teilen.
- Eventuelle Fehler in Deiner Analyse können von Dir oder anderen aufgespürt und korrigiert werden: Denn anhand des Skriptes können alle Dein Vorgehen genau nachvollziehen.
Heute möchte ich eine weitere Möglichkeit von R nutzen und aus mehreren Graphiken einen „Film“ erstellen. So lassen sich Daten Einsichten entlocken, die sonst vielleicht verborgen geblieben wären.
Unsere heutige Fragestellung und unser Vorgehen
Wenn nun davon abhängt, wie viele Länder in unsere Untersuchung einbezogen werden – vom größten bis zum kleinsten Emittenten, dann wollen wir jetzt wissen: Wer ist „Sieger“, wenn wir die größten 3, 5, 10, 30 oder 100 Emittenten einbeziehen? Wir gehen deshalb wie folgt vor:
- Wir besorgen uns den neuesten derzeit von der Weltbank zur Verfügung gestellten Datensatz. Das sind die Daten für das Jahr 2019 und zwar für 181 Länder.
- Wir sortieren diesen Datensatz absteigend nach den CO2-Emissionen je Land.
- Mit einer Variablen i durchlaufen wir dann eine Schleife über alle Länder.
- In jeder Schleife wählen wir die größten i CO2-Emittenten aus und sortieren diese absteigend nach ihrem Bruttosozialprodukt je kg CO2-Emission.
So können wir für die jeweilige Auswahl von Ländern
- den jeweiligen „Klimaeffizienz-Gruppensieger“ innerhalb der i größten Emittenten ermitteln und
- das dazugehörige „Siegertreppchen“ (erster Platz, zweiter Platz, …) graphisch darstellen.
Welches Land hält sich am längsten auf dem Siegerpodest?
Beim Durchlaufen dieser Schleifen fällt auf, dass manche Länder bei Hinzunahme von weiteren Ländern schnell vom „Siegerpodest gestoßen“ werden, andere sich länger halten. Diese jeweiligen „Gruppensieger“ unter den i = 1, 2, 3, … 181 größten Emittenten von CO2 können wir graphisch wie folgt darstellen. Die Schweiz ist nicht nur Siegerin, sie hält sich auch am längsten:
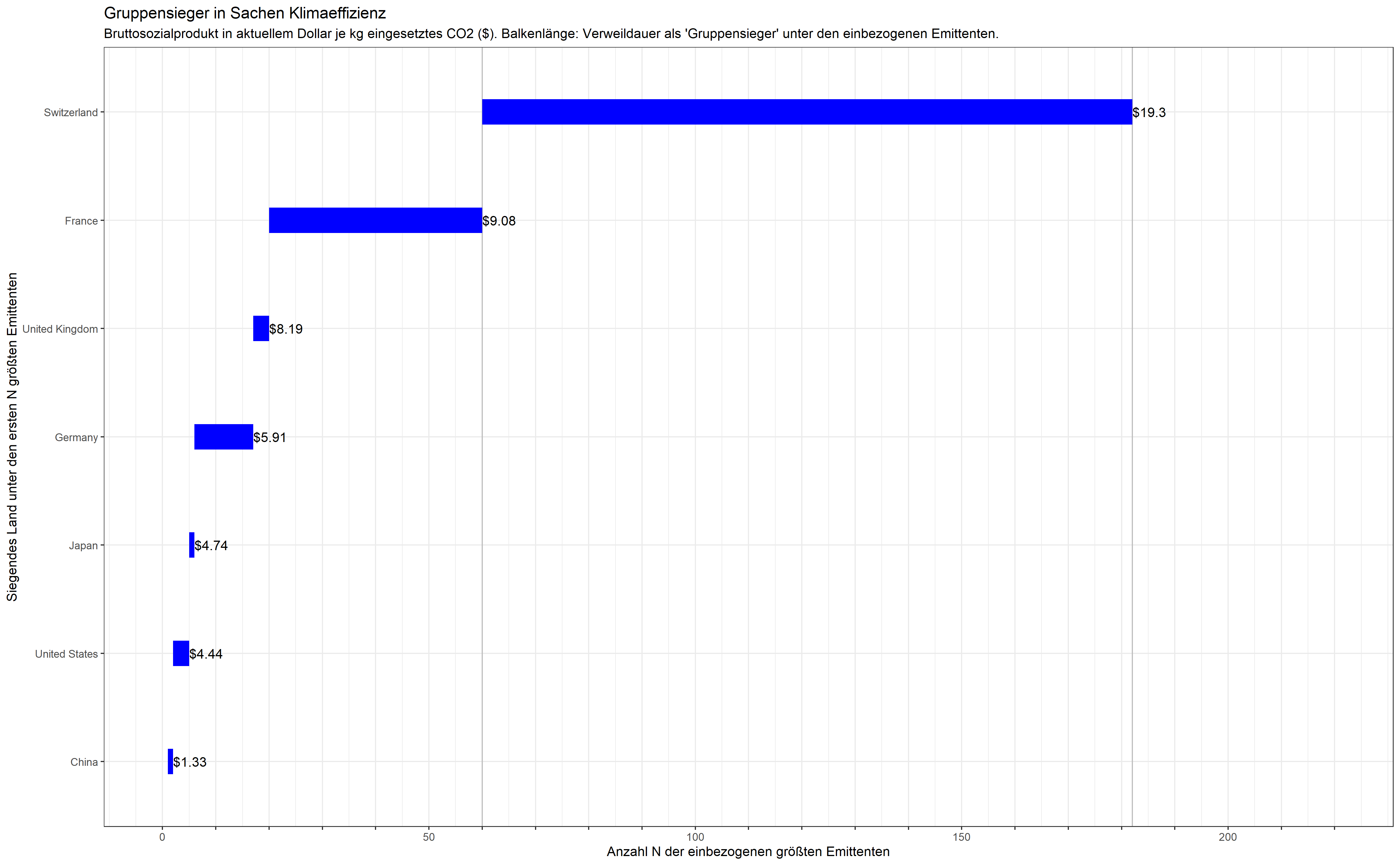
„Gruppensieger“ in Sachen Klimaeffizienz. Bruttosozialprodukt in Dollar.
Lesen wir diese Graphik einmal genauer: Wenn wir nur den größten Emittenten China einbeziehen, dann ist, trivialerweise, China mit einem Bruttosozialprodukt von $1.33 je kg CO2 der „einsame Sieger“. Unter den ersten zwei bis vier größten Emittenten schneiden zunächst die USA am besten ab, dann übernimmt kurzfristig Japan. Deutschland steht vorn, sobald die größten sechs Emittenten betrachtet werden und wird erst von dem Emittenten Nr. 17, dem Vereinigten Königreich abgelöst, das kurz darauf an Frankreich abgibt bis schließlich der Emittent Nr. 60, die Schweiz, die Nase vorn hat und behält: die Schweiz erwirtschaftet sagenhafte $19.30 je eingesetztes Kilogramm CO2.
Nun ist diese Betrachtung ein wenig „ungerecht“: die Kaufkraft eines Dollars ist von Land zu Land verschieden. Kaufkraftparitätisch betrachtet stellt sich die Lage tatsächlich mit interessanten Nuancen dar.
So übernimmt zwischenzeitlich Brasilien mit $4.76 je kg CO2 die Führung: angesichts der Kaufkraft eines Dollars in Brasilien setzt das Land seine CO2-Emissionen also im Sinne der eigenen Bevölkerung effizient für die Erwirtschaftung des Bruttosozialprodukts ein. Wenn Präsident Lula eine Führungsrolle im Kampf gegen den Klimawandel beansprucht, dann legt das Land dafür also durchaus eigene Leistungen in die Waagschale – was nicht zuletzt auch Deutschland neulich durch eine Einzahlung in Höhe von 35 Millionen Euro in den Amazonas-Fond honoriert hat.
Kurzfristig erscheint auch Singapur als „Gruppensieger“ zwischen Frankreich und der Schweiz: ein Pionier, wenn es darum geht, Großstädte grüner und klimaeffizienter zu gestalten. In dieser Betrachtung wird auch die Schweiz von Uganda und Uganda schließlich von der Demokratischen Republik Kongo abgelöst. Auch hier bleibt die Schweiz am längsten in der Pole-Position:
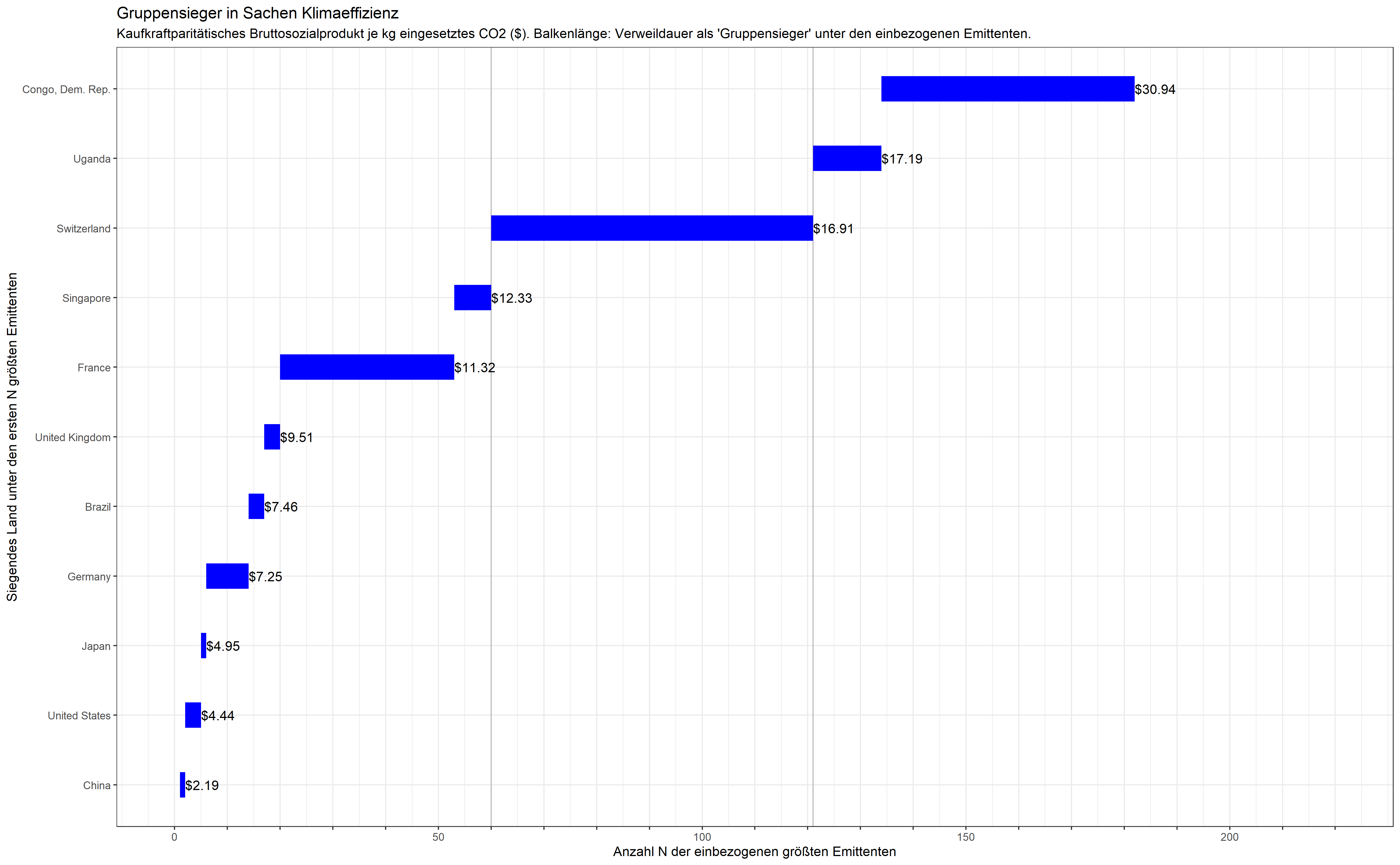
„Gruppensieger“ in Sachen Klimaeffizienz. Kaufkraftparitätisches Bruttosozialprodukt. Die Schweiz bleibt am längsten in der Pole-Position.
Wir halten fest:
Unter den derzeit 36 OECD-Ländern (Organisation for Economic Co-Operation and Development, laut Economist ein „Club zumeist reicher Länder„) ist die Schweiz der eindeutige Sieger. Sie hat auch am längsten „die Nase vorn“ und erwirtschaftet ca. 19 Dollar Bruttosozialprodukt je eingesetztes Kilogramm CO2.
Deutschland mag vielleicht nur wenige Inspirationsquellen in Uganda oder der demokratischen Republik Kongo finden, die in der kaufkraftparitätischen Betrachtung deutlich besser abschneiden. Ein Blick über die Grenze nach England, Frankreich oder in die Schweiz erscheint aber durchaus lohnenswert: diese Volkswirtschaften sind so unterschiedlich nicht. So kommen zum Beispiel der Schweizer Verwaltung zufolge 61,5% des eidgenössischen Stroms aus Wasserkraft, 28,9% aus Kernkraft und weitere 7,7% aus neuen erneuerbaren Energien. Die Liste der deutschen Wasserkraftwerke ist ebenfalls beachtlich. Wie könnten diese im Verbund mit Wind und Sonne am besten genutzt werden?
Oder – wir setzen uns jetzt den schwarzen Denkhut auf – ist die Schweizer Wasserkraft vielleicht durch sinkende Schneemengen in den Alpen bedroht? Und wo kommen die Brennstäbe für die Atomkraftwerke in Frankreich und der Schweiz her? Wo landen sie, wenn sie ausgebrannt sind? Wir könnten uns hier auf eine Diskussion um Atom, Wasser, Wind und Sonne nur insofern einlassen, als ein neugieriger Blick auf unsere Nachbarn bestimmt nicht schadet.
Und wie sieht das jeweilige Siegertreppchen aus?
Die vorherigen Graphiken zeigen, welches Land wie lange „die Nase vorn hat“. Aber welche Länder folgen darauf und wie dicht sind sie dem jeweiligen Sieger auf den Fersen? Vielleicht stoßen wir ja auf weitere Länder, von denen sich etwas lernen ließe.
Beim Durchlaufen der oben besprochenen Schleife habe ich deshalb das „Siegertreppchen“ auch graphisch dargestellt (z.B. die 10, 20 oder 30 größten Emittenten nach absteigender Klimaeffizienz angeordnet) und daraus einen „Film“ erstellt. Dank R ist das mit wenigen Zeilen Code getan:
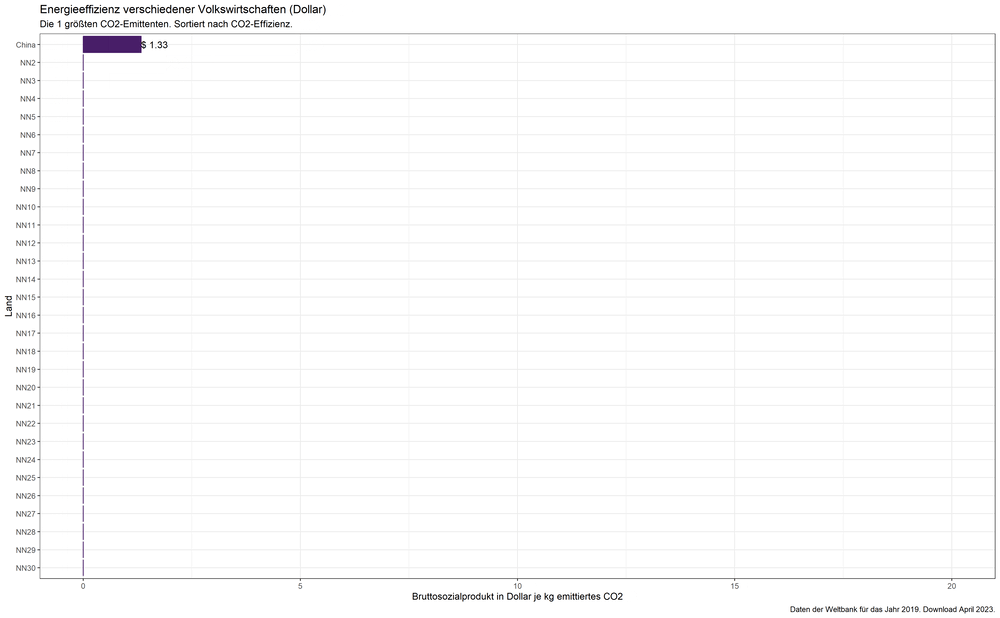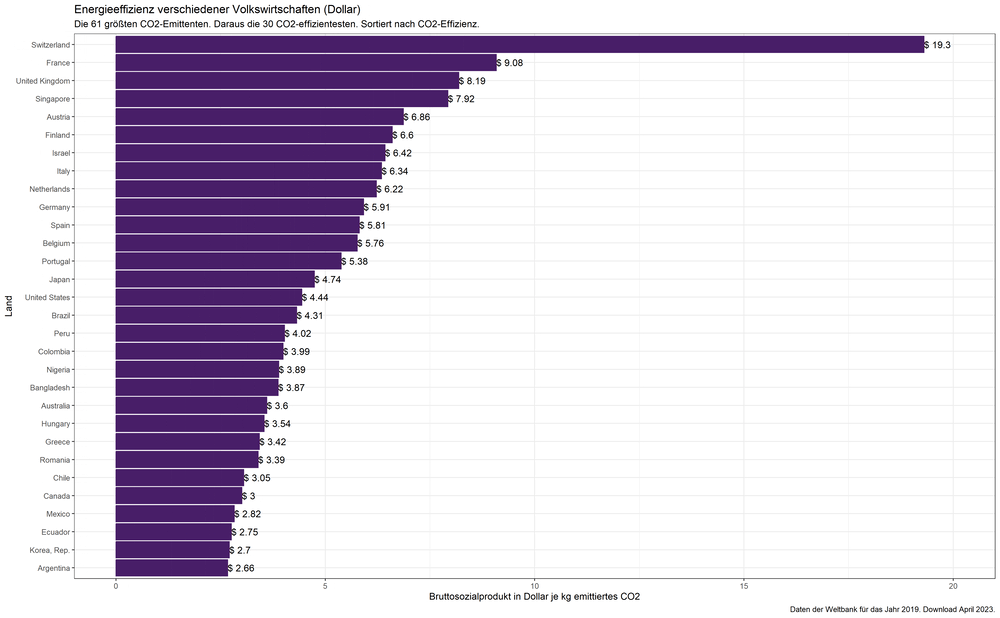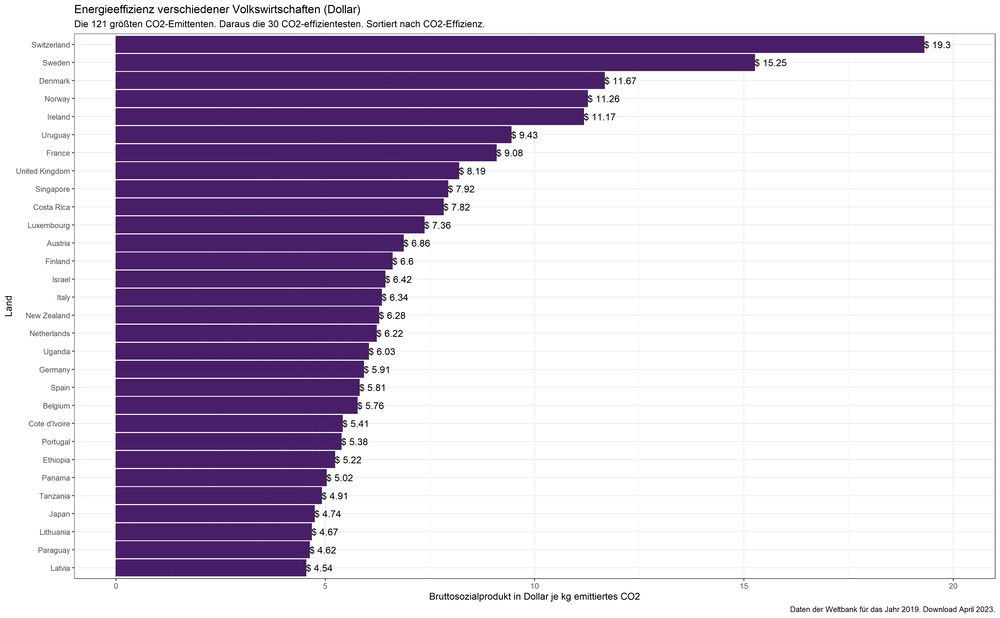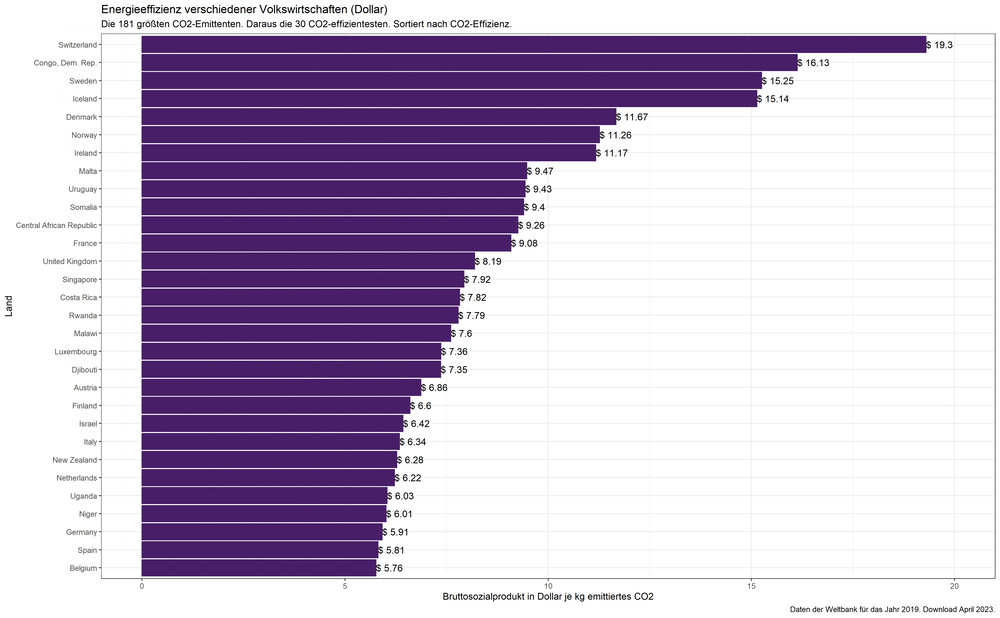
„Siegertreppchen“ in Sachen Klimaeffizienz der Volkswirtschaft – je nachdem wie viele der größten CO2-Emittenten betrachtet werden. Bruttosozialprodukt in Dollar.
Wir sparen uns hier den „Film“ in kaufkraftparitätischer Betrachtung und stellen vielmehr fest, dass die „nordischen Länder“ Schweden, Norwegen, Island, Irland und Dänemark in Sachen Klimaeffizienz ebenfalls weit vorne liegen.
Wie entwickelt sich die Klimaeffizienz der Länder über die Zeit?
Hier möchte ich die deutsche Perspektive einnehmen und deshalb die eher vergleichbaren Volkswirtschaften der „high income countries“ (blau in der Graphik) hervorheben. Die Entwicklung aller anderen Länder sollen jedoch (in grau) sichtbar bleiben. Unter den anderen Ländern wähle ich zudem die vier größten Emittenten aus, sodass wir auch diese verfolgen können. Da die Länder sehr verschieden groß sind, stelle ich die Emissionen auf der vertikalen Achse in logarithmischer Auftragung dar:
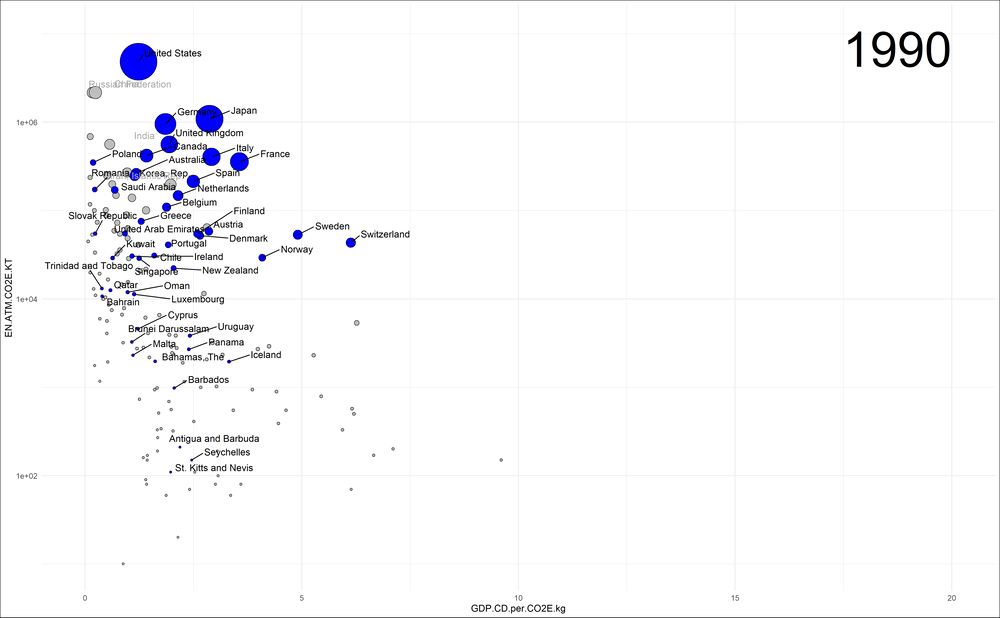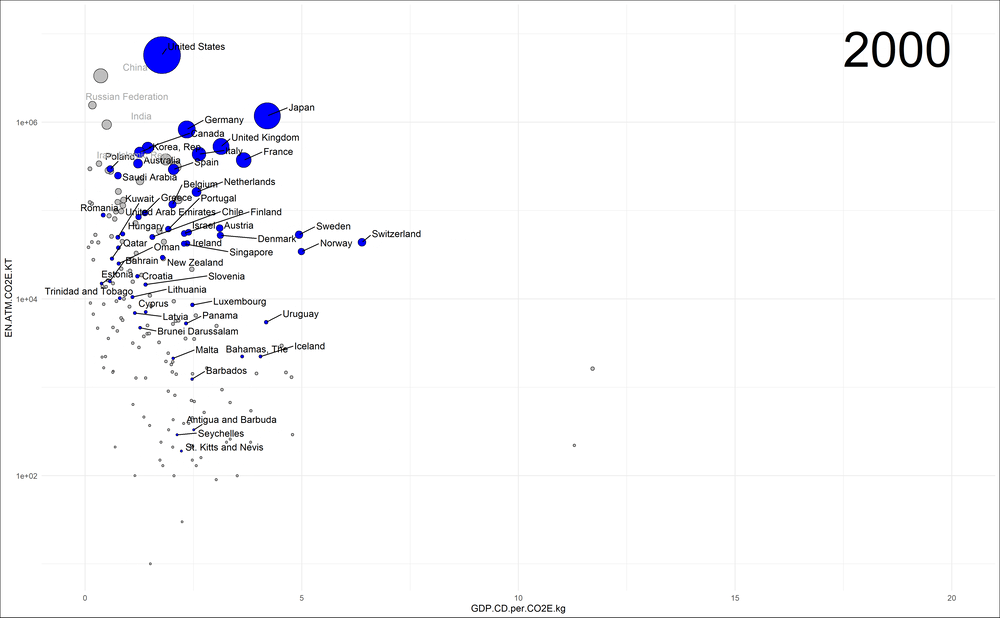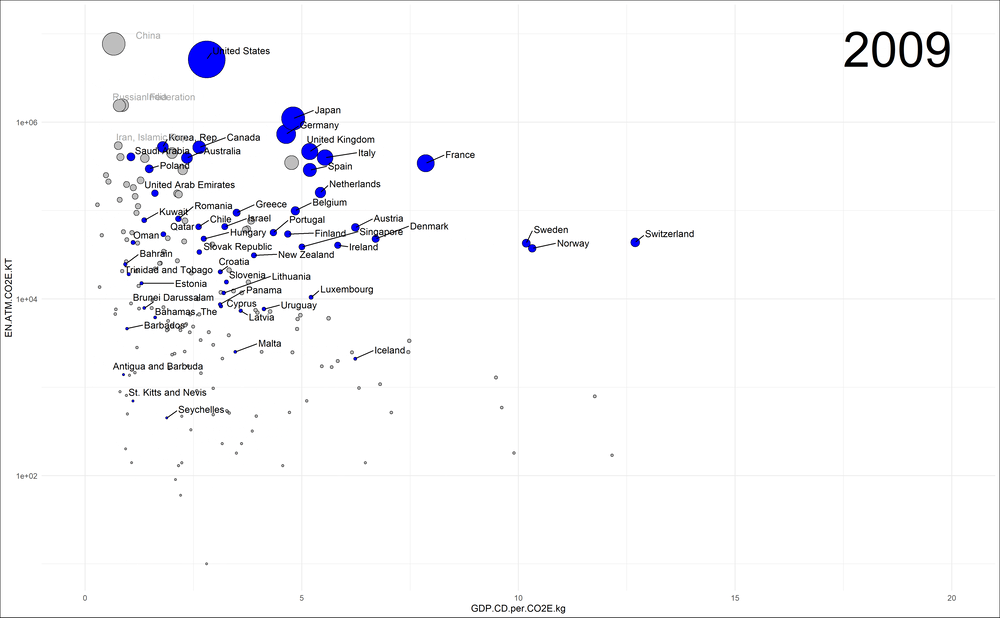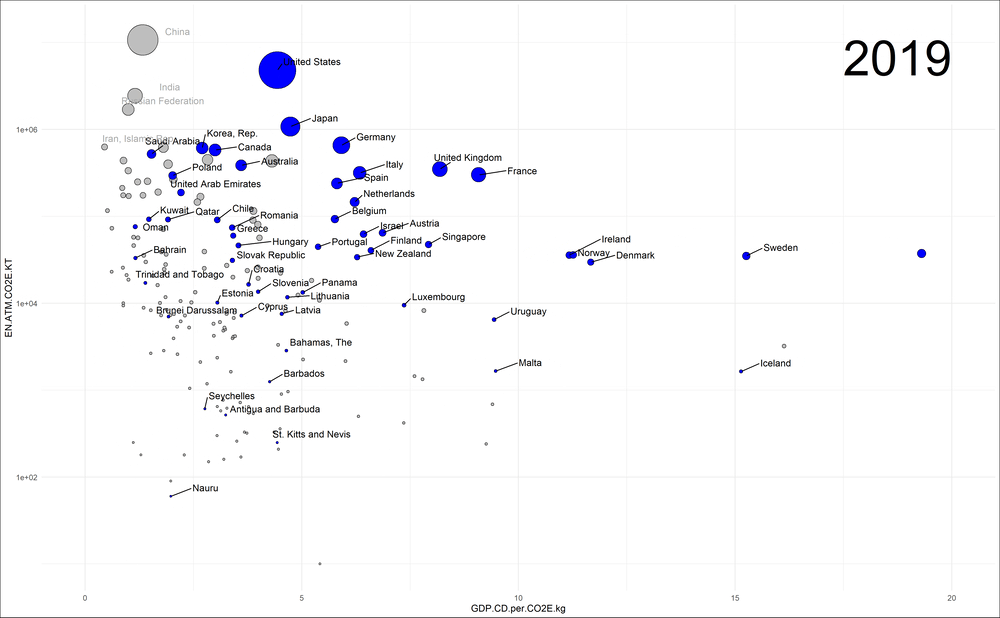
Emissionen der high-income Länder im Laufe der Zeit – aufgetragen gegen die Klimaeffizienz. Das Bruttosozialprodukt wird in „current dollars“ (CD) und nicht in kaufkraftparitätischen gemessen.
Ich finde erstaunlich, wie gut in dieser Darstellung das „Durchstarten“ in Sachen Klimaeffizienz der Länder Schweiz, Schweden, Norwegen und auch Dänemark sichtbar wird: bei nahezu konstanten Emissionen vergrößern sie signifikant ihre Volkswirtschaften und die Klimaeffizienz (GDP.CD.per.CO2E.kg) driftet folglich horizontal weg. Wir schauen uns deshalb den zeitlichen Verlauf gesondert an:
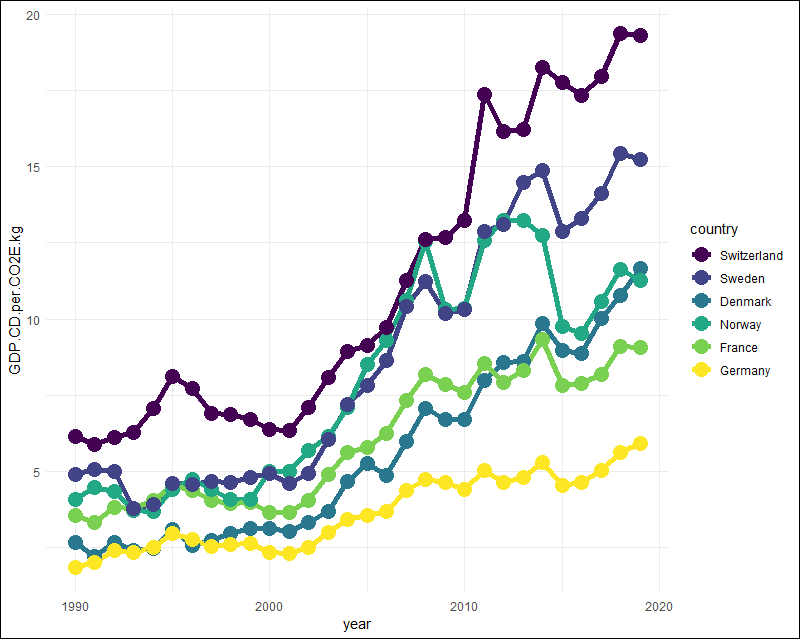
Zeitliche Entwicklung der Klimaeffizienz ausgewählter Volkswirtschaften.
Die Schweiz hat also die Klimaeffizienz ihrer Wirtschaft in dem Zeitraum von 1990 bis 2919 mehr als verdreifacht, von 6,13 Dollar Bruttosozialprodukt je eingesetztes Kilogramm CO2 auf 19,30 Dollar. Auch Deutschland hat solch eine Verdreifachung erreicht, und zwar von 1,80 Dollar/kg auf 5,91 Dollar/kg. Wir sind also im Jahr 2019 fast dort, wo die Schweiz im Jahr 1990 stand.
Nun magst Du diese absolute Betrachtung für „ungerecht“ halten: wenn Du am Anfang eines Fitnessprogramms zwei Klimmzüge geschafft hast und nachher sechs, dann ist bist Du vielleicht noch mehr stolz darauf als jemand, der sich von 10 auf 14 gesteigert hat. Wir schauen uns das deshalb genauer an und beziehen dafür die Werte für jedes Jahr und Land auf die jeweiligen Werte des Jahres 1990:
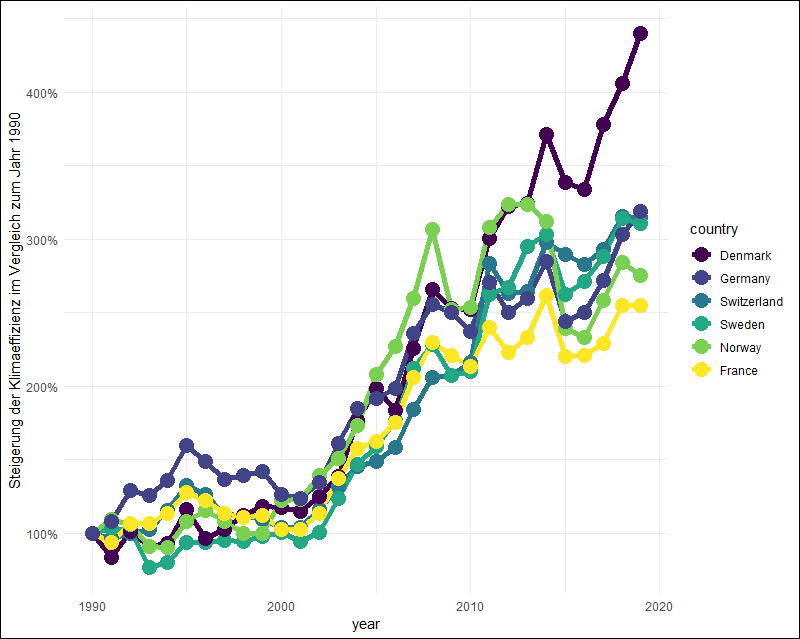
Klimaeffizienz im Vergleich zum Bezugsjahr 1990. Dänemark erreicht eine Steigerung um 440%.
Der Überraschungssieger in dieser Auftragung heißt
Dänemark.
Dänemark holt im Jahr 2019 im Vergleich zum Bezugsjahr 1990 fast viereinhalb mal soviel Bruttosozialprodukt aus jedem Kilogramm eingesetzten CO2 heraus.
Nun magst Du zu recht einwenden, dass wir unsere Betrachtungen auf die Werte eines einzigen Jahres beziehen: was wäre, wenn wir stattdessen die Werte des Jahres 1989 (die nicht vorliegen) oder die des Jahres 1991 zugrunde gelegt hätten? Anstatt das auszuprobieren, ziehen wir alle zur Verfügung stehenden Jahre heran und führen in einer Schleife, Land für Land, eine Regressionsanalyse durch und bestimmen so die durchschnittliche jährliche Änderung.
Lass mich hier – als Übergang zum folgenden DIY-Abschnitt – dafür den Code teilen und erläutern. Zunächst erstellen wir eine Tabelle t für die Jahre, die unsere Werte enthalten (1990 bis 2019). Wir nehmen Zeilen mit NA-Werten und solche Werte heraus, die durch Teilen durch Null erzeugt wurden und wählen die uns interessierenden Spalten aus. Wir ziehen uns daraus eine Liste der Länder und zählen diese:
t <- indicatortable %>%
filter(year >= 1990, year <= 2019) %>%
drop_na() %>%
filter(!is.infinite(GDP.CD.per.CO2E.kg)) %>%
select(year, country,
EN.ATM.CO2E.KT,
NY.GDP.MKTP.CD,
GDP.CD.per.CO2E.kg)
laender <- unique(t$country)
anz <- length(laender)
So können wir die gewünschte Ergebnistabelle erstellen, die wir dann in der folgenden Schleife mit Werten befüllen. „Puristen“ mag das hemdsärmelig erscheinen. Wenn Du eine elegantere Methode kennst, dann lass mich das gerne wissen!
res <- data.frame( Land = rep(NA, anz), Steigerung = rep(NA, anz), # jährl. Steigerung der Klimaeffizienz R2 = rep(NA, anz), # R2 dieser Steigerung PWert = rep(NA, anz), # Signifikanz der Steigung Emissionen = rep(NA, anz), # Emissionen in kt im letzten Jahr GDP = rep(NA, anz), # BSP in current dollar im letzten Jahr Effizienz = rep(NA, anz) # Klimaeffizienz im letzten Jahr )
Nun können wir die Tabelle befüllen. Dafür filtern wir aus t zunächst nur das jeweilige Land, führen eine Regressionsanalyse durch (lm, „linear model“), legen die Ergebnisse in der Variablen s ab und ziehen uns dann den Koeffizienten der Steigung, den Regressionskoeffizienten R2 und den P-Wert. Ein bisschen Debugging für fehlende Werte kommt noch hinzu:
for (i in 1:length(laender)) {
land <- laender[i]
dat <- t %>% filter(country == land)
model <- lm(data = dat,
GDP.CD.per.CO2E.kg ~ year)
s <- summary(model)
res[i, 1] <- land
res[i, 2] <- s$coefficients[2,1]
res[i, 3] <- s$r.squared
res[i, 4] <- round(s$coefficients[2,4], 3) # P-Wert linear
# Wir müssen noch einen Fehler abfangen,
# denn für manche Länder gibt es keine Daten.
if(2019 %in% dat$year) {
res[i, 5] <- dat$EN.ATM.CO2E.KT[dat$year == 2019]
res[i, 6] <- dat$NY.GDP.MKTP.CD[dat$year == 2019]
res[i, 7] <- dat$GDP.CD.per.CO2E.kg[dat$year == 2019]
}
}
Mit dieser Ergebnis-Liste res kannst Du viel anfangen. So finden wir zum Beispiel über
nochange <- res %>% filter(PWert > 0.05)
alle Länder, in denen sich die Klimaeffizienz in den fast 30 Jahren nicht signifikant geändert hat und mit
degradation <- res %>% filter(Land %notin% nochange$Land) %>% filter(Steigerung < 0)
einige Länder, in denen sich die Lage sogar verschlechtert hat. Anschauen möchten wir uns die Länder, in denen sich die Lage verbessert hat. Dafür sortieren wir absteigend um das Land in dieser Reihenfolge für die folgende Graphik als Faktor zu definieren:
improvement <- res %>%
filter(Land %notin% nochange$Land) %>%
filter(Land %notin% degradation$Land) %>%
arrange(desc(Steigerung))
improvementdata <- t %>%
filter(country %in% improvement$Land)
improvementdata$country <- factor(improvementdata$country,
levels = improvement$Land)
ggplot(data = improvementdata %>%
filter(country %in% improvement$Land[1:12]),
aes(x = year,
y = GDP.CD.per.CO2E.kg)) +
geom_line() +
geom_smooth(method = "lm",
formula = y ~ x,
se = T) +
facet_wrap(~ country, ncol = 3)
So erhalten wir folgende Graphik:
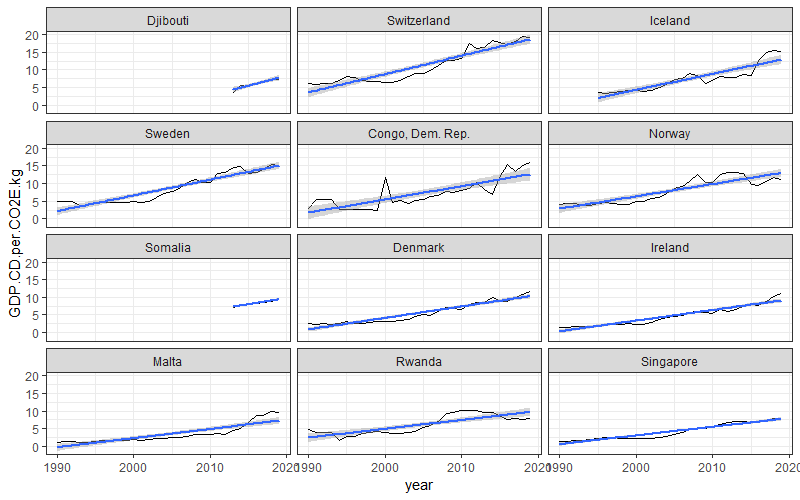
Länder mit der größten jährlichen Steigerung der Klimaeffizienz ihrer Volkswirtschaft
Wir stoßen auf alte Bekannte wie die Schweiz, die nordischen Länder und Singapur. Aber auch Ruanda hat seine Klimaeffizienz Jahr für Jahr um 25 Dollarcent je Kilogramm CO2 verbessert. Malta hat gerade in den letzten Jahren stark zugelegt: was ist da geschehen? Und seit Daten für diese Länder vorliegen sind auch Djibouti – sogar noch vor der Schweiz – und Somalia mit dabei. Uganda ist in dieser Betrachtung, in der es nicht um „Leistung“ sondern um Verbesserung geht, weit abgeschlagen.
Du magst Dich fragen: wo sind Länder wie die Niederlande, Belgien, Luxemburg oder auch Finnland? Die sind alle da. Sie haben sich nur nicht in unseren Algorithmen „verheddert“. In der letzten Untersuchung der Verbesserung finden wir für Luxemburg eine jährliche Steigerung von $0.24/kg (sehr konsistent bei einem R^2 = 94%), Finnland legt Jahr für Jahr um $0.17/kg (bei R^2 = 86%) zu, Belgien liefert $0.16/kg ab (R^2 = 88%) und die Niederlande $0.15/kg (R^2 = 87%).
Jede Auswahl ist ungerecht – egal welcher Algorithmus sie trifft. Deshalb also mein Tipp:
Do it yourself!
Ich teile im Folgenden die wichtigsten Codezeilen, sodass Du diese Überlegungen nachvollziehen, prüfen oder erweitern kannst.
Ich habe die folgenden Bibliotheken verwendet:
library(WDI) # Zugang zu den Weltbankdaten
library(ggrepel) # Daten ohne Überlapp beschriften
library(tidyverse) # Einfache Handhabung von Daten
library(ggthemes) # Schöne Graphiken
'%notin%' <- Negate('%in%') # Vereinfacht einige Code-Zeilen
So beschaffst Du Dir die Daten der Weltbank und bereitest sie auf:
# Wir wählen die uns interessierenden Indizes heraus.
# https://data.worldbank.org/, "browse by indicator").
indicators <- data.frame(
ID =
c("EN.ATM.CO2E.PC",
"EN.ATM.CO2E.KT",
"NY.GDP.MKTP.CD",
"NY.GDP.PCAP.PP.CD",
"NY.GDP.MKTP.PP.CD",
"SP.POP.TOTL"),
details =
c("CO2 emissions (metric tons per capita)",
"CO2 emissions (kt)",
"GDP (current US$)",
"GDP per capita, PPP (current international $)",
"GDP, PPP (current international $)",
"Population, total")
)
# Indizes laden:
indicatortable <- WDI(indicator = indicators$ID,
extra = TRUE)
# Klimaeffizienz berechnen, in
# - Kaufkraftparität (PP)
# - und in "Current Dollars" (CD):
indicatortable <- indicatortable %>%
mutate(GDP.PP.per.CO2E.kg = NY.GDP.MKTP.PP.CD/EN.ATM.CO2E.KT/1e6,
GDP.CD.per.CO2E.kg = NY.GDP.MKTP.CD/EN.ATM.CO2E.KT/1e6)
# Letztes verfügbares Jahr:
y2019 <- indicatortable %>%
filter(year == 2019)
So erstellst Du das „Siegertreppchen“:
# Anzahl der betrachteten größten CO2-Emittenten:
n <- 70
# Aus diesen: Anzahl der CO2-effizientesten Länder:
m <- 30
# Daten erstellen:
plotdat <- y2019 %>%
arrange(desc(EN.ATM.CO2E.KT)) %>%
slice(1:n) %>%
arrange(desc(GDP.CD.per.CO2E.kg))
# Reihenfolge in der Graphik über Faktor festlegen:
plotdat$country <-
factor(plotdat$country,
levels = rev(plotdat$country))
# Wesentliche Element des Plots.
# "Verschönerungen" habe ich der Einfachheit weggelassen:
ggplot(data = plotdat[1:m, ],
aes(x = GDP.CD.per.CO2E.kg,
y = country)) +
geom_bar(stat = "identity") +
geom_text(aes(label = paste("$",
round(GDP.CD.per.CO2E.kg,2),
sep = "")),
position = position_dodge(width = 1),
hjust = 0,
vjust = 0.5)
So erstellst Du die Graphik für die „high income“ Länder und speicherst in einer Schleife die Graphiken ab:
# Liste aller high-income Länder in 2019:
hic2019 <- y2019 %>%
filter(income == "High income") %>%
select(country) %>% pull()
# Große Emittenten, die wir auch namentlich benennen wollen:
special <- y2019 %>%
filter(country %notin% hic2019) %>%
arrange(desc(EN.ATM.CO2E.KT)) %>%
slice(1:4) %>%
pull(country)
# Graphik fest skalieren:
xmax_graph <- max(indicatortable$NY.GDP.MKTP.CD, na.rm = T)
ymax_graph <- max(indicatortable$EN.ATM.CO2E.KT, na.rm = T)
# Schleife:
for (my_year in 1990 : 2019) {
t <- indicatortable %>%
filter(year == my_year)
# Zwei Gruppen:
hic <- t %>%
filter(country %in% hic2019)
rest <- t %>%
filter(country %notin% hic2019)
# Grosse Emittenten:
grE <- t %>%
filter(country %in% special)
# Ein recht komplexer Plot mit vielen "Layers":
plot <- ggplot() +
geom_point(data = rest, # Rest soll unten liegen
aes(x = NY.GDP.MKTP.CD,
y = EN.ATM.CO2E.KT,
size = SP.POP.TOTL),
fill = "grey",
shape = 21) +
geom_point(data = hic, # Darüber hi-Länder
aes(x = NY.GDP.MKTP.CD,
y = EN.ATM.CO2E.KT,
size = SP.POP.TOTL),
fill = "blue",
shape = 21) +
geom_text_repel(data = hic, # Beschriftung hic
aes(x = NY.GDP.MKTP.CD,
y = EN.ATM.CO2E.KT,
label = country)) +
geom_text(aes(x = xmax_graph, # Jahreszahl der Graphik
y = 0,
label = my_year),
hjust = 1, vjust = 0, size = 20) +
geom_text(data = grE, # Beschriftung rest-Länder
aes(x = NY.GDP.MKTP.CD,
y = EN.ATM.CO2E.KT,
label = country),
color = "black") +
xlim(c(0,xmax_graph)) +
ylim(c(0,ymax_graph)) +
scale_y_continuous(trans='log10') +
scale_x_continuous(trans='log10')
name <- paste("graph", my_year, ".png", sep = "")
ggsave(name,
plot,
width = width, height = height)
print(my_year) # Damit uns nicht langweilig wird
}
So erstellst Du den „Film“ für diese Graphiken. Den „Treppchenfilm“ erstellst Du analog:
library(gifski)
imgs <- list.files(pattern="*.png")
imgwidth <- 1000
imgheight <- round(imgwidth/ratio, 0)
gifski(imgs,
gif_file = "name_der_animation.gif",
width = imgwidth,
height = imgheight,
delay = 0.5) # delay in Sekunden
Hier erstellen wir die Graphik für die Klimaeffizienz der ausgewählten Länder:
# Liste L, gleich in richtiger Reihenfolge für Faktor:
L <- c("Switzerland", "Sweden", "Denmark",
"Norway", "France", "Germany")
# Datentabelle erzeugen:
t <- indicatortable %>%
filter(country %in% L,
year >= 1990) %>%
select(year, country,
EN.ATM.CO2E.KT,
NY.GDP.MKTP.CD, GDP.CD.per.CO2E.kg) %>%
mutate(country = factor(country, levels = L))
# Graphik, ohne "Verschönerungen:
ggplot(data = t,
aes(x = year,
y = GDP.CD.per.CO2E.kg,
colour = country))
# So berechnen wir die Daten für die "relativ-Graphik":
trel <- t %>%
select(year, country, GDP.CD.per.CO2E.kg) %>%
arrange(country, year) %>%
group_by(country) %>%
mutate(Relativ = GDP.CD.per.CO2E.kg / GDP.CD.per.CO2E.kg[1])