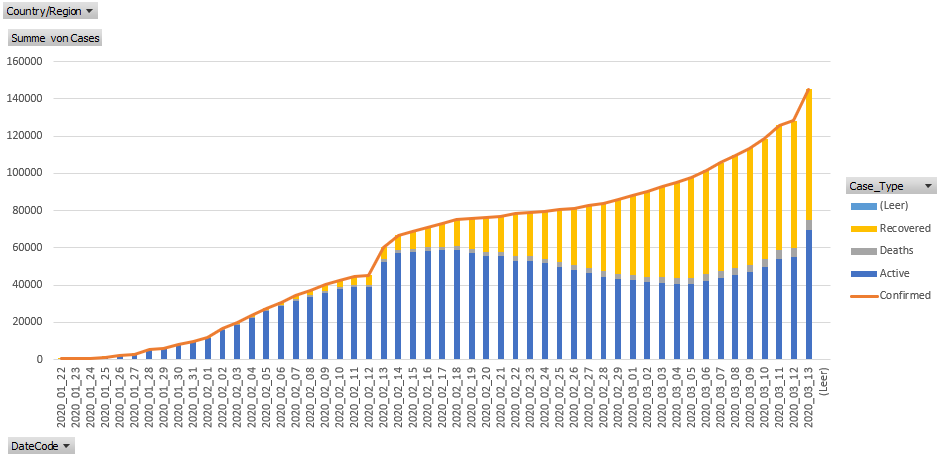
Ein Prozess zur Datenanalyse
Wir haben gestern die Daten und eine erste Analyse geteilt. Ohne groß Aufhebens darum zu machen haben wir sehr schnell (und zu nachlässig) wichtige Schritte professioneller Datenanalyse durchlaufen. Ein Modell für den zugrunde liegenden Prozess ist OSEMN, was man wohl wie „awesome“ (engl. für genial) aussprechen sollte:
OBTAIN: Daten aufzutreiben ist oft schon das erste ernst-zunehmende Problem. Wir haben mehrere Datenquellen betrachtet und uns dann für eine Google-Tabelle entschieden. Die herunterzuladen war dank R einfach. Auch in Unternehmen liegen Daten „auf SAP“ – doch dann muss eine Abfrage geschrieben werden, was nur wenige können. Oder es gibt einfach keine Daten zur Durchlaufzeit eines bestimmten Prozesses und ein Messsystem muss erst aufgebaut werden.
SCRUB: Als nächstes müssen Daten „gesäubert“ werden. Wer die Corona-Daten von Kaggle verwenden möchte muss die Jahreszahlen für das Datum vereinheitlichen und sich mit Regionen wie „Chicago, IL“ herumschlagen, die wegen des zusätzlichen Kommas das Einlesen der csv-Datei erschweren. Häufig fehlen auch Daten und man muss überlegen, wie man mit diesen Datensätzen umgeht. Oder ein Kundenname ist als „Audi“, „audi“ und „AUDI“ hinterlegt – und, und, und…
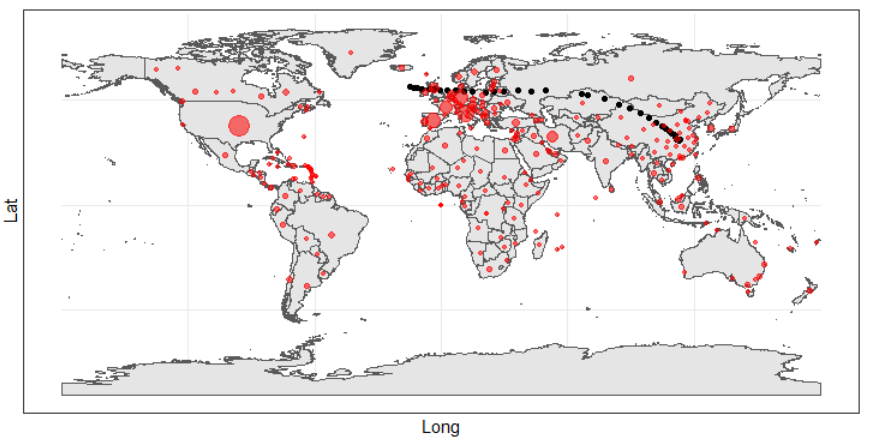
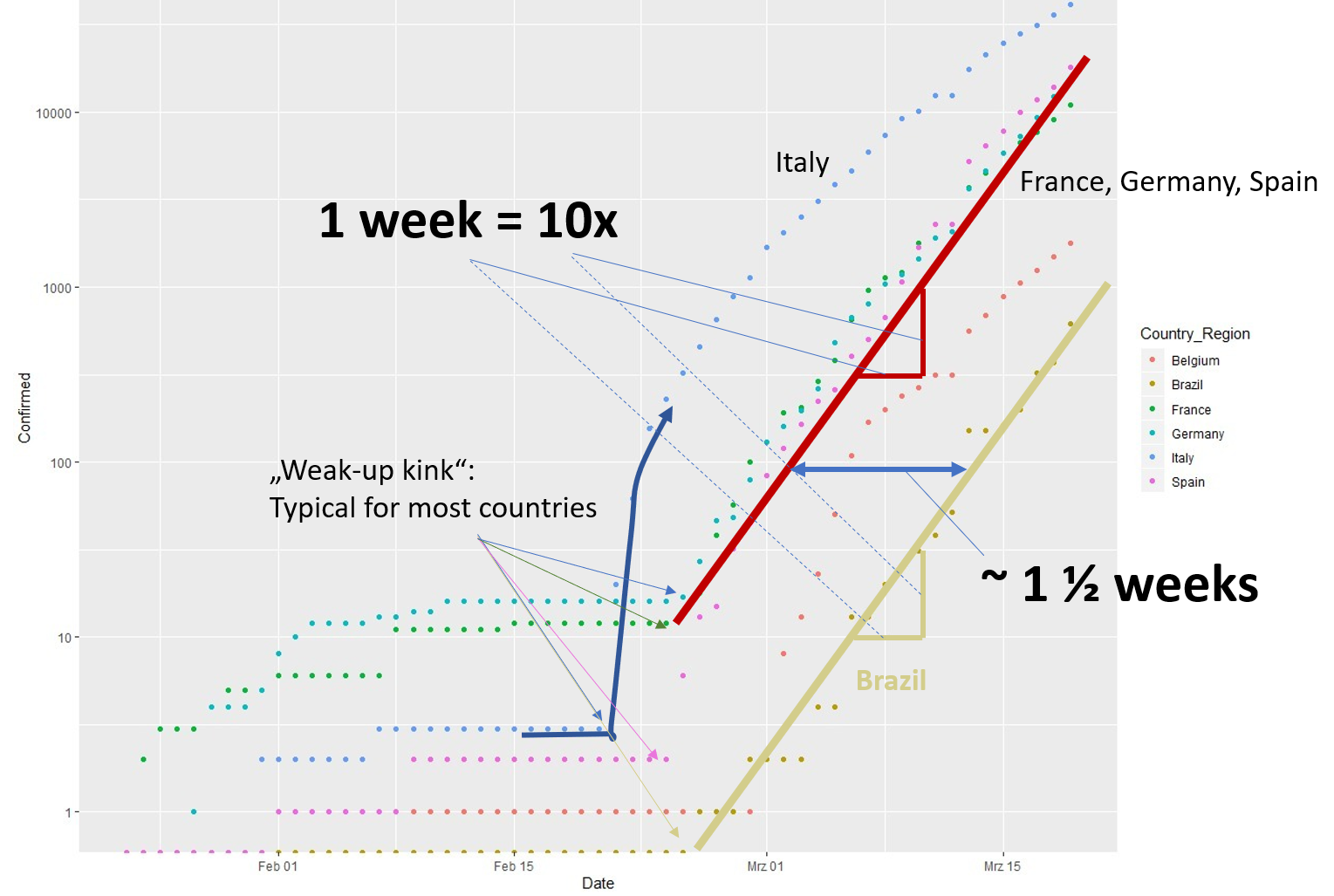
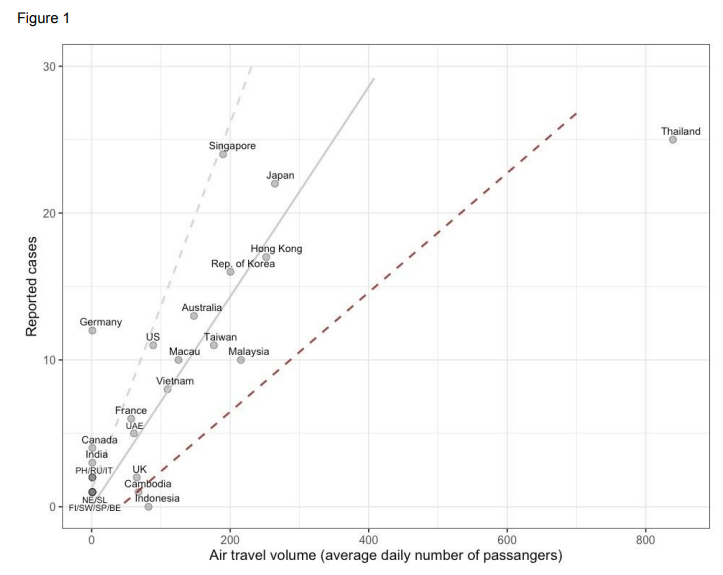
EXPLORE: Man schaut sich die Daten von allen Seiten her an: wie sieht die Wachstumskurve für Deutschland, Frankreich, China usw. aus? Wo sind die Hauptinfektionsherde? Dieses „Herumspielen“ ist vor allem wichtig, um neue Fragen aufzuwerfen. Ich hoffe, das haben Sie getan und dabei einige interessanten Aspekte gefunden, wie zum Beispiel: die Wachstumsrate ist für Singapur von Anfang an deutlich geringer als bei uns in Deutschland; Deutschland ist bei ähnlicher Infektionsrate 7-8 Tage hinter Italien, dicht gefolgt von den USA. Falls Sie es noch nicht getan haben, dann versuchen Sie sich daran: Sie sollten dafür die „Confirmed“ Fälle logarithmisch über die Zeit auftragen.
MODEL: Schließlich erstellt man Modelle – mit dem Ziel, Vorhersagen zu treffen. Das wollen wir heute tun, um der Frage aller Fragen nachzugehen: gibt es schon Licht am Ende des Tunnels? Zeichnet sich irgendwo ein Wendepunkt ab (der „inflection point“ aus dem gestern geteilten Video)?
iNTERPRET: Welche Belastung kommt auf das Gesundheitssystem voraussichtlich zu? Wie lange hat es bei anderen Ländern gedauert, um an den Wendepunkt zu kommen? Welche Maßnahmen waren dafür erforderlich? Was können wir lernen? – Usw. Das Ziel der Datenanalyse ist nicht die Analyse. Das Ziel sind die daraus abgeleiteten Maßnahmen.
Das Modell der logistischen Kurve
Wie so häufig in der Datenanalyse müssen wir uns auch hier in ein Modell einarbeiten, das vielen nicht geläufig sein wird. Das Modell wurde in dem Video gestern vorgestellt.
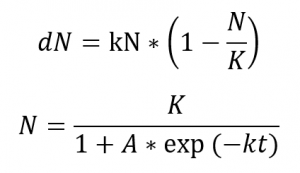
Für manche mögen diese Formeln zunächst erschreckender aussehen als sie es sind – und was ich zur Beruhigung vorzubringen habe mag auch nicht allen helfen: in den Augen eines Statistikers handelt es sich hier um ein leicht handhabbares Modell. Diese Aussage muss natürlich erklärt werden.
Zunächst einmal: was bedeuten die Symbole?
dN: Wachstumsrate; also die Anzahl der Neuinfektionen pro Tag
N: die Infektionen insgesamt – in unseren Daten die Spalte „Confirmed“
t: die Zeit gemessen in Tagen.
Bei K, k und A handelt es sich um Faktoren, die es zu bestimmen gilt.
Sehen wir uns die Gleichungen einmal genauer an: solange A*exp(-kt) >> 1 ergibt sich eine Exponentialfunktion – die Gleichung beschreibt dann exponentielles Wachstum – wie in dem Video beschrieben. Interessant ist auch, wie die erste Gleichung sich umformen lässt: dN/N = k – N*k/K. Man erwartet also, dass die Anzahl der neuen Infektionen dN, geteilt durch alle bestätigten Infektionen N linear mit N zusammenhängt. Das heißt, wir müssen in den Daten lediglich eine Spalte dN/N hinzufügen und dann eine Regressionsanalyse dieser Spalte gegen N fahren. Dabei ergeben sich zwei mögliche Situationen:
- dN/N hängt von N ab:
In diesem Fall zeigen die Daten den Effekt eines Wendepunktes und wir sind nicht mehr im Bereich des rein exponentiellen Wachstums.
- dN/N hängt nicht von N ab:
Wir sind noch im Bereich exponentiellen Wachstums und es gilt dieses zu bestimmen und z.B. Kapazitäten im Gesundheitssystem entsprechend (massiv) vorzuhalten.
Deutschland im Vergleich zu China
In der Datei COVID_Daten_20200316_ChinaVsDtld stelle ich die Daten für Deutschland und China bereit. Diese Daten sind aus der gestrigen Datei berechnet:
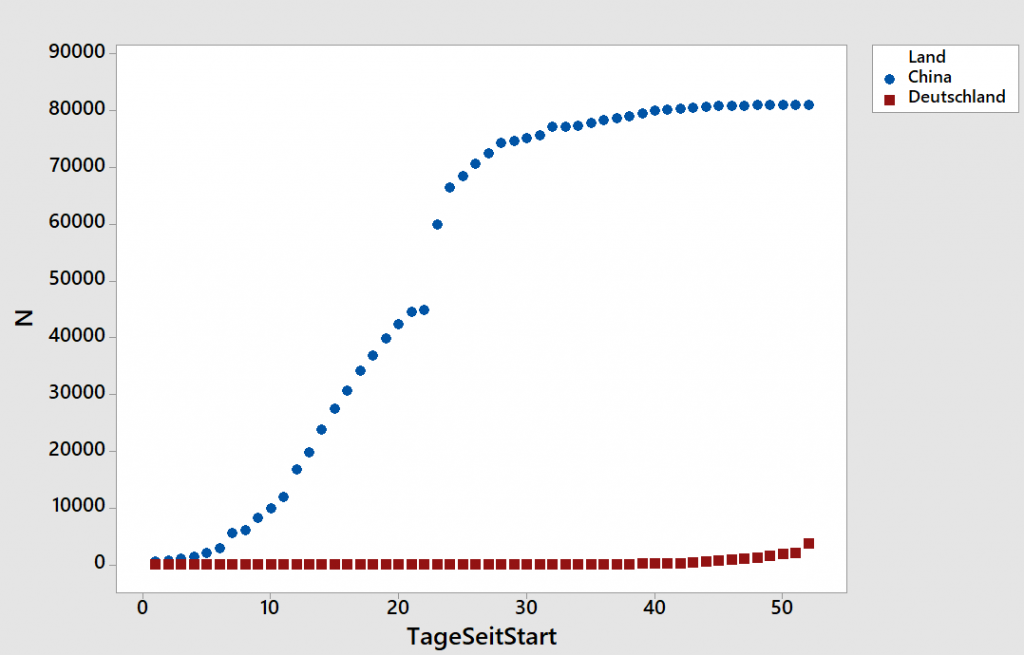
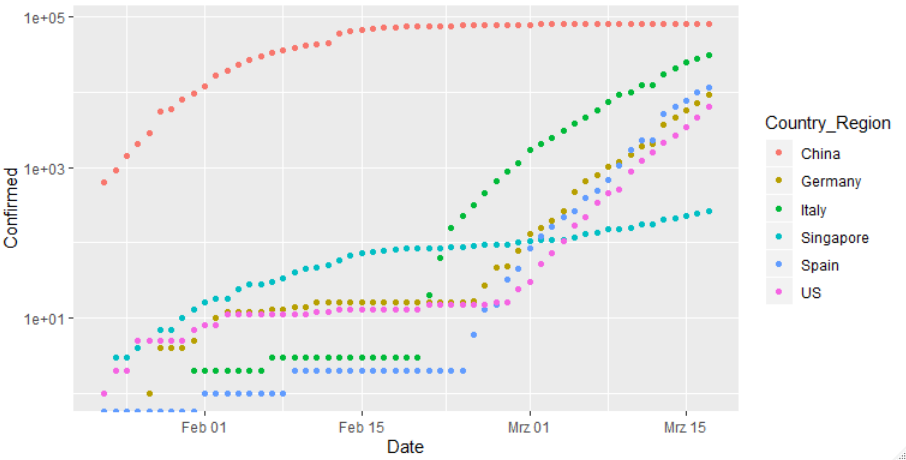
Wir betrachten hier zunächst in linearer Auftragung die Anzahl der Infektionen für Deutschland und China – und erkennen das Problem dieser Darstellung: man unterschätzt die Gefahr in Deutschland völlig. Der Fehlschluss ist: „Wir haben alles im Griff“.
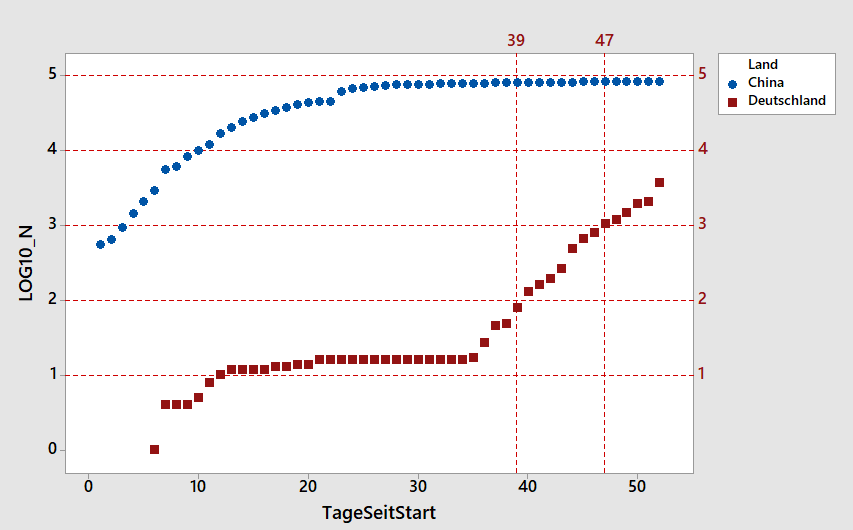
Die Dramatik wird in dieser Graphik deutlich, der die gleichen Daten zugrunde liegen: über mehrere Tage hinweg gab es knapp über 10 registrierte Fälle in Deutschland (der Log10 von 10 ist 1, von 100 ist er 2 usw.). Wie in dem nun schon oft zitierten Video gezeigt ist die Welt jedoch vernetzt. Am Tag 35 (dem 25. Februar) setzte man in Deutschland ein Messsystem auf und erkannte, was los war. Der Anstieg ist seither exponentiell (logarithmisch aufgetragen ergibt sich eine Gerade). In nur 8 Tagen, vom Tag 39 bis zum Tag 47 hat sich die Anzahl der Infektionen verzehnfacht – und ein Ende der Verzehnfachung alle 8 Tage ist vorerst nicht abzusehen – denn wir sehen keinen Hinweis auf einen Wendepunkt.
Lektion 3: Visualisierung ist alles.
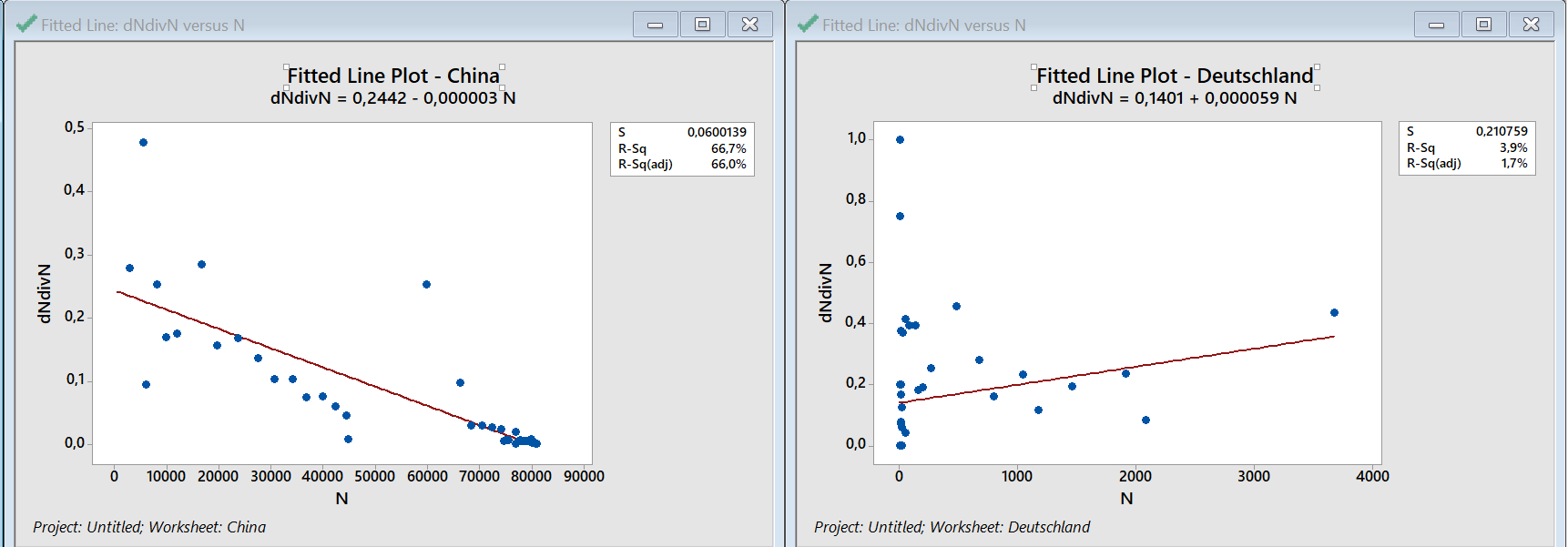
Hier sehen wir nun links, dass 60% der Änderung in dN/N für China zusammenhängen mit einer Änderung in N – und dies bei einem P-Wert (hier nicht gezeigt) von 0%. In anderen Worten: wir sind uns 100% sicher, dass der Zusammenhang, den wir hier sehen, echt ist (für Profis: dass er zumindest eine starke Korrelation darstellt). Für Deutschland ist die scheinbare Steigung statistisch nicht signifikant – und würde auch nur <2% der beobachteten Variation in den Werten erklären.
An dieser Stelle ein mir wichtiger Hinweis: es geht hier in erster Linie um Datenanalysen. Die Anzahl der Neuinfektionen ist in China inzwischen tatsächlich deutlich zurückgegangen. Das heißt jedoch nicht, dass die Gefahr gebannt wäre. Solange in anderen Gegenden der Welt die Pandemie andauert, besteht die sehr reale Möglichkeit eines erneuten Ausbruchs auch in China. Es bleibt abzuwarten, wie China mit dieser Situation umgehen wird.
Zurück zur Datenanalyse. Wer das Programm verwendet hat gesehen, dass ich hier Minitab eingesetzt habe. Diese Graphiken und auch die statistischen Analysen lassen sich auch mit Excel über Daten -> Werkzeuge für Datenanalyse erstellen. Gegebenenfalls müssen Sie diese Werkzeuge über Datei -> Optionen -> Add Ins noch aktivieren.
Ziel: alle Länder nach dem Stand der Dinge durchsuchen
Was wir nun für ein Land gemacht haben kann und sollte man auch für alle Länder durchführen. Ich gehe davon aus, dass eine globale Organisation wie die Weltgesundheitsorganisation diese Untersuchung täglich aktualisiert:
- Welche Länder zeigen inzwischen einen Wendepunkt?
- In welcher Phasen befindet sich jedes Land?
- Wie viele Neuinfektionen müssen deshalb je Land erwartet werden?
Es ist offensichtlich, dass es sich hierbei um eine Untersuchung handelt, die nicht mehr händisch sondern automatisiert durchgeführt werden muss. Das soll für die nächsten Tage auf dem Programm stehen und ist meine Hausaufgabe.
Ihre „Hausaufgaben“ für heute:
- Wählen Sie zwei Länder aus (z.B. Deutschland und Singapur)
- Tragen Sie die kumulierte Anzahl der Infektionen logarithmisch auf und vergleichen Sie graphisch und numerisch die Infektionsrate („Confirmed“) in den Daten
- Finden Sie andere Länder als China, in denen wir zumindest Anzeichen eines Wendepunktes sehen? Wie sieht die Lage in Singapur aus?