
Die Analyse von Umweltdaten ist mehr als eine Spielerei
Daten lassen mich einfach nicht los, solange noch eine nicht-erzählte Geschichte in ihnen steckt. Und so ist das auch mit den Temperaturdaten des Starnberger Sees, dem hier nun der dritte Eintrag gewidmet ist.
Ich halte das jedoch für mehr als einfach nur „Spielerei“:
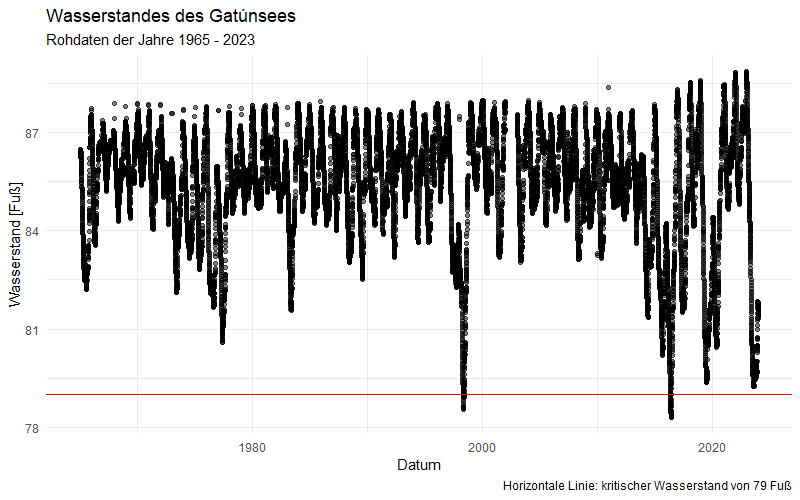
- Zu vielen Gewässern gibt es lange Zeitreihen mit Temperatur- und Wasserstandsdaten
- Diese Daten genau zu betrachten ist für unseren achtsamen Umgang mit der Natur wichtig
- Sie sind also wertvoll und zudem einfach zu analysieren: „Datum/Uhrzeit – Temperatur“ oder „Datum/Uhrzeit – Wasserstand“
- Wenn es gelänge, diese Analysen zu „demokratisieren“, sodass aufmerksame Bürgerinnen oder Anwohner eines Sees oder Flusses sie selbst unternehmen können, dann könnten sie, hoffentlich rechtzeitig, Trends erkennen und, falls nötig, Warnungen aussprechen. Denn bei der Vielzahl der Gewässer kann diese Aufgabe nicht einfach nur ein paar Spezialisten übertragen werden.
Ein simples, lineares Modell der Temperaturentwicklung
Ich habe mit verschiedenen Modellen experimentiert und es geschafft, deren Güte R2 auf über 99% zu bringen. Im Sinne der „Demokratisierung“ der Analyse von Umweltdaten geht es mir jedoch vor allem darum, ein einfach nachvollziehbares Modell aufzubauen.
Das heute verwendete Modell setzt deshalb einen linearen Verlauf der Temperatur voraus, dem eine jahreszeitliche Schwankung überlagert ist:
Temperatur = Linearer Anstieg + Jahreszeitliche Schwankung.
In R ist solch ein Modell mit einer Zeile Code erstellt:
model <- lm(Temp ~ Index + KW, data = df, na.action = na.omit)
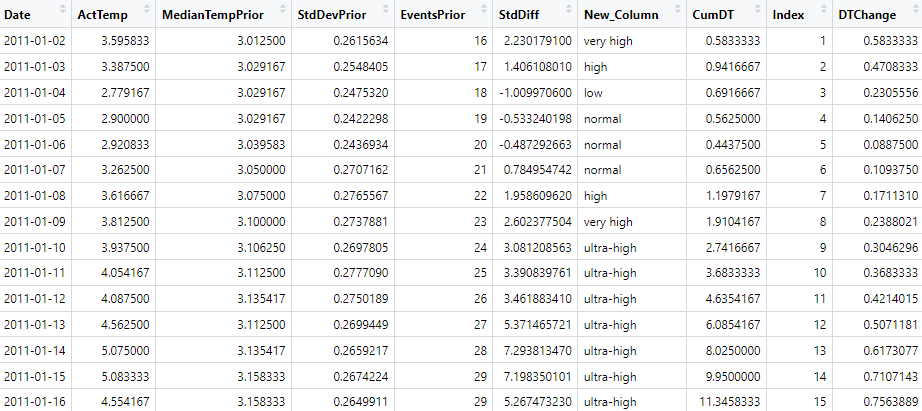
Hier steht „lm“ für „lineares Modell“, das den Datenrahmen df verwendet und die Temperatur gegen den laufenden Index der Tage sowie die Kalenderwoche des jeweiligen Jahres untersucht. Dabei werden Tage ohne Eintrag („NA“) weggelassen. So erhalte ich ein Modell mit einer Güte von immerhin 95% und einen mittleren Anpassungsfehler von 1.5°C. Das Modell sagt die tatsächliche Temperatur also mit dieser Genauigkeit (bei einem Sigma) voraus.
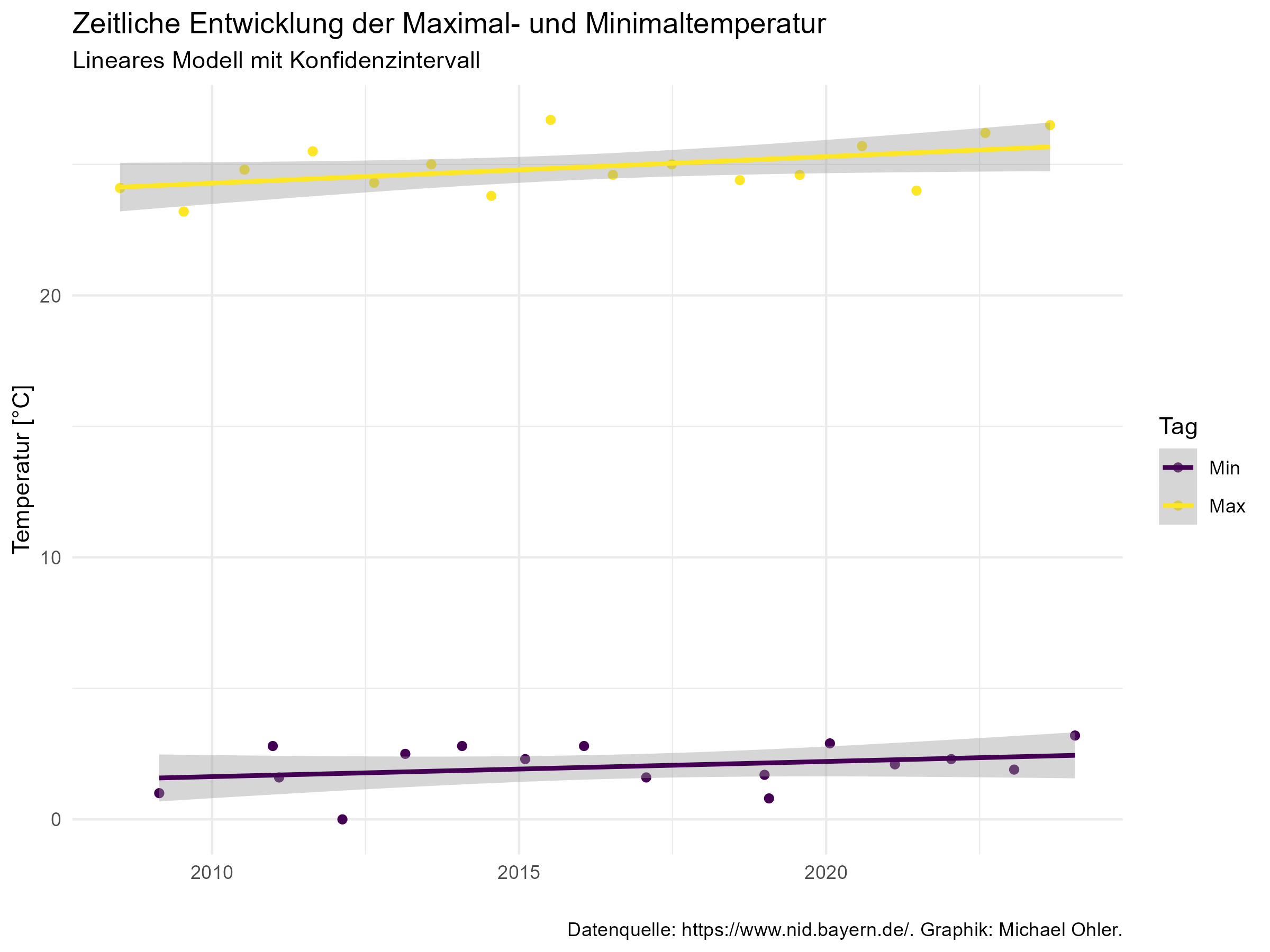
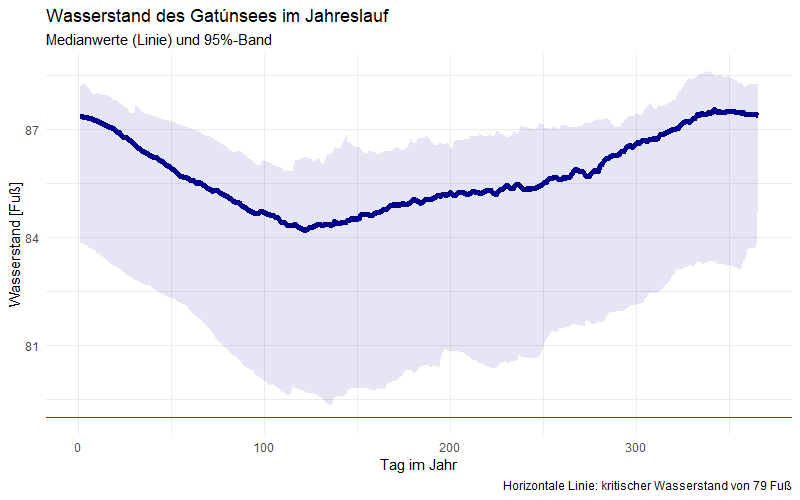
Aus dem „summary“ des Modells lese ich zudem heraus, dass wir es über den betrachteten Zeitraum mit einer Erwärmung von ca. 0,7 – 0,8°C pro 10 Jahre zu tun haben. Das Modell passt auch Woche für Woche den durchschnittlichen Temperaturhub an, sodass wir uns diesen anzeigen lassen können:
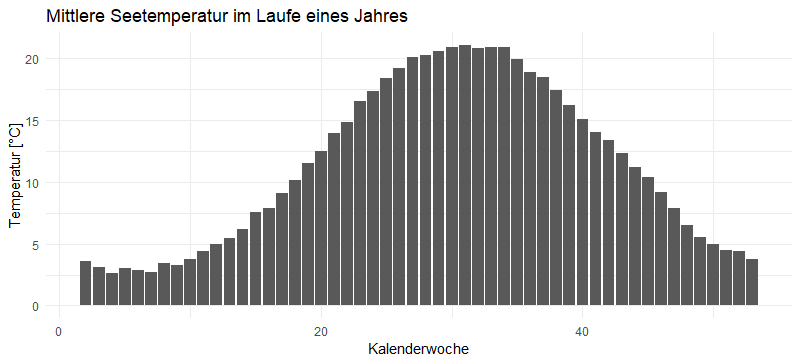
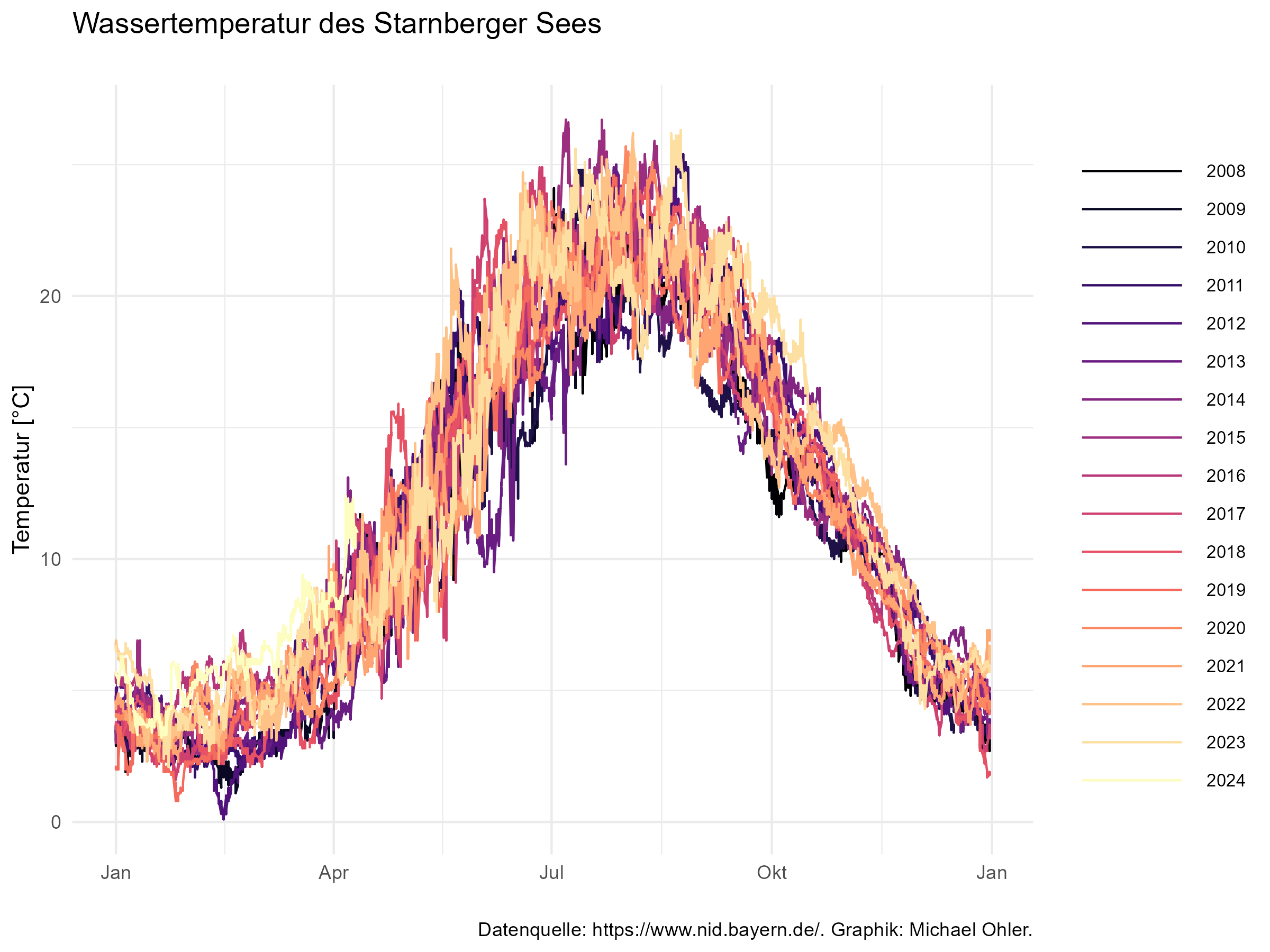
Bis auf den Anpassungsfehler des Modells (dargestellt in der nächsten Graphik) durchläuft die Temperatur des Starnberger Sees also diese Temperaturkurve – zusätzlich zu dem stetigen Temperaturanstieg.
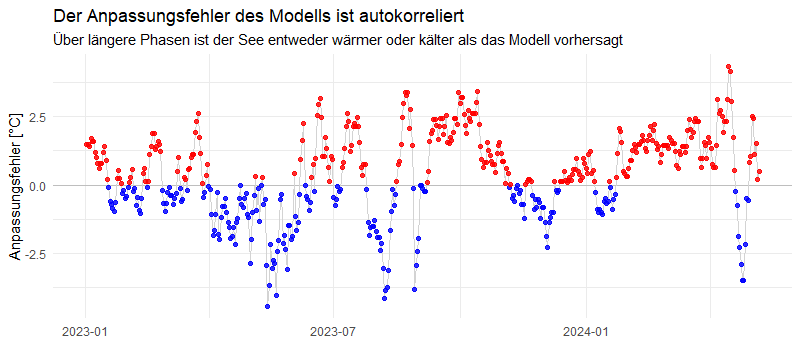
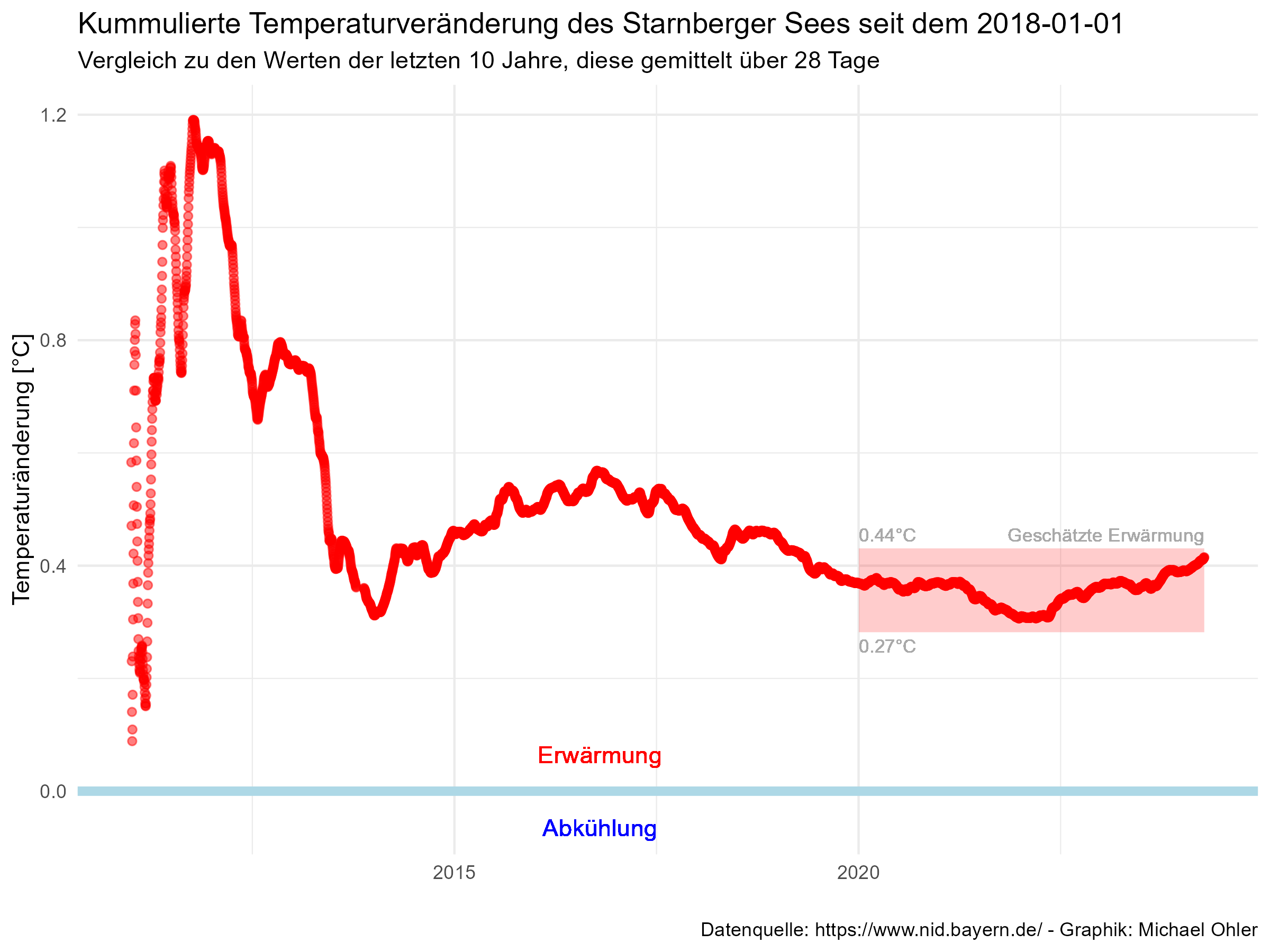
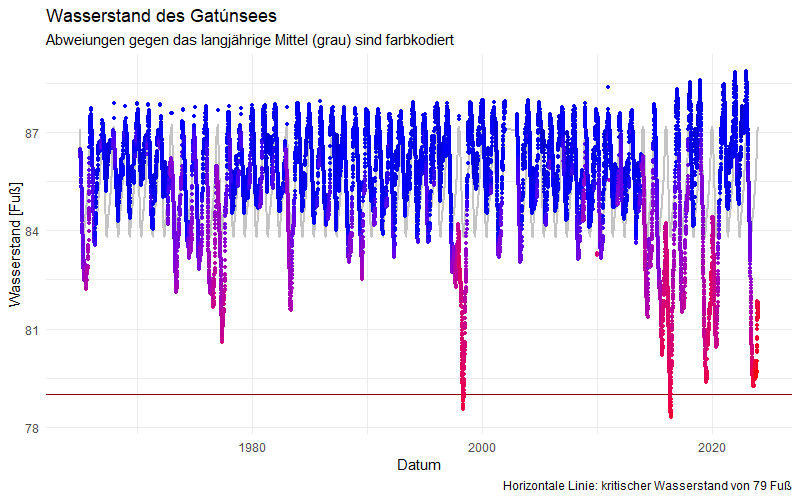
Wir erkennen hier, dass der Anpassungsfehler keineswegs „rein zufällig“ verläuft. Es gibt durchaus längere Zeiträume, über die hinweg die Temperatur deutlich über oder deutlich unter den durch das Modell beschriebenen Werten liegen. Mathematisch formuliert: der Anpassungsfehler ist mit sich selbst korreliert. Wenn eine Abweichung zwischen tatsächlicher und vom Modell vorhergesagter Temperatur eher über der Nulllinie liegt, dann werden auch die darauffolgenden Werte sich eher dort als auf der anderen Seite befinden. Bei einem rein zufälligen Prozess würden sich diese Abweichungen nach oben und nach unten schnell die Waage halten.
Wie ist das Jahr 2024 bisher verlaufen?
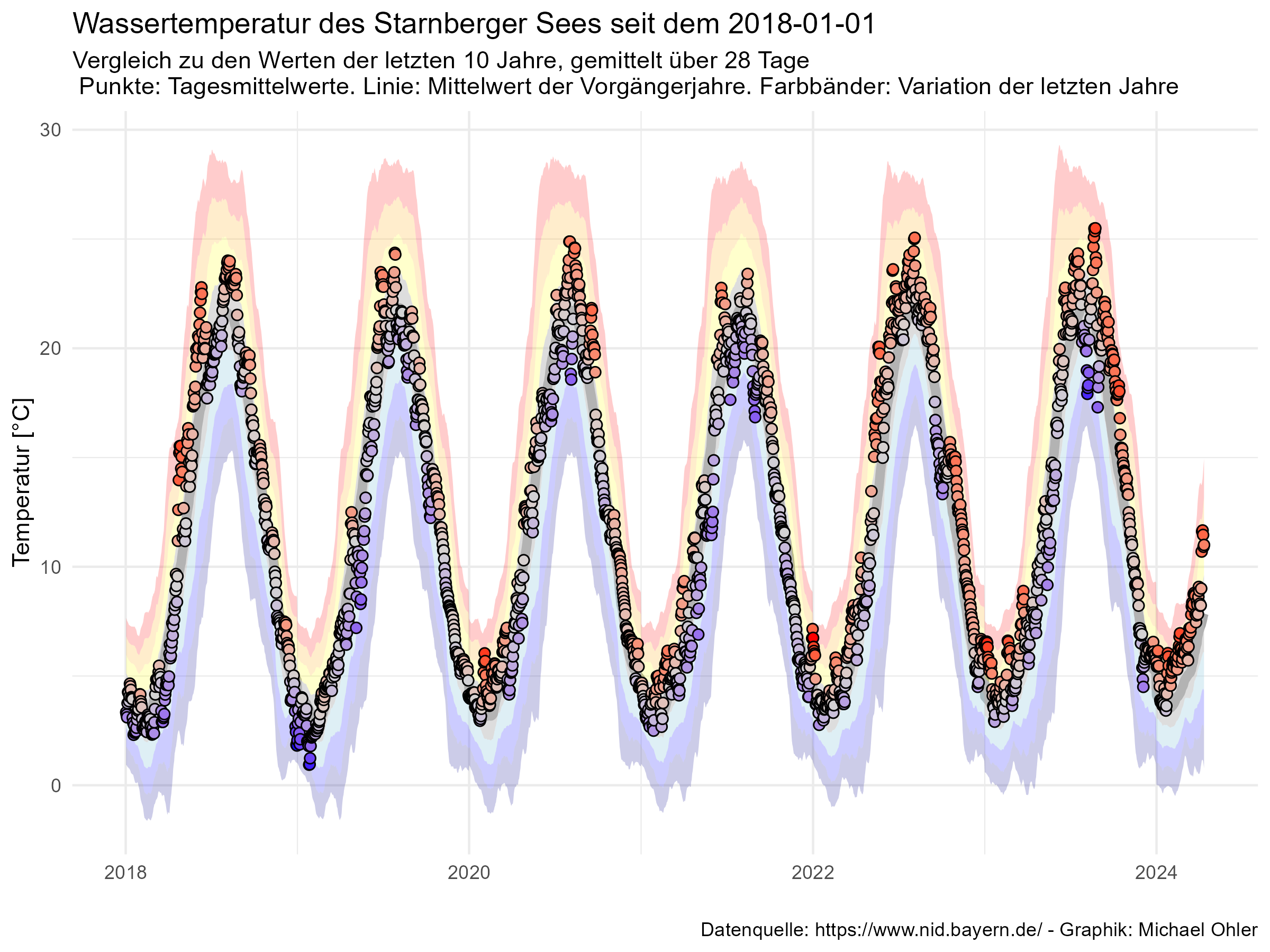
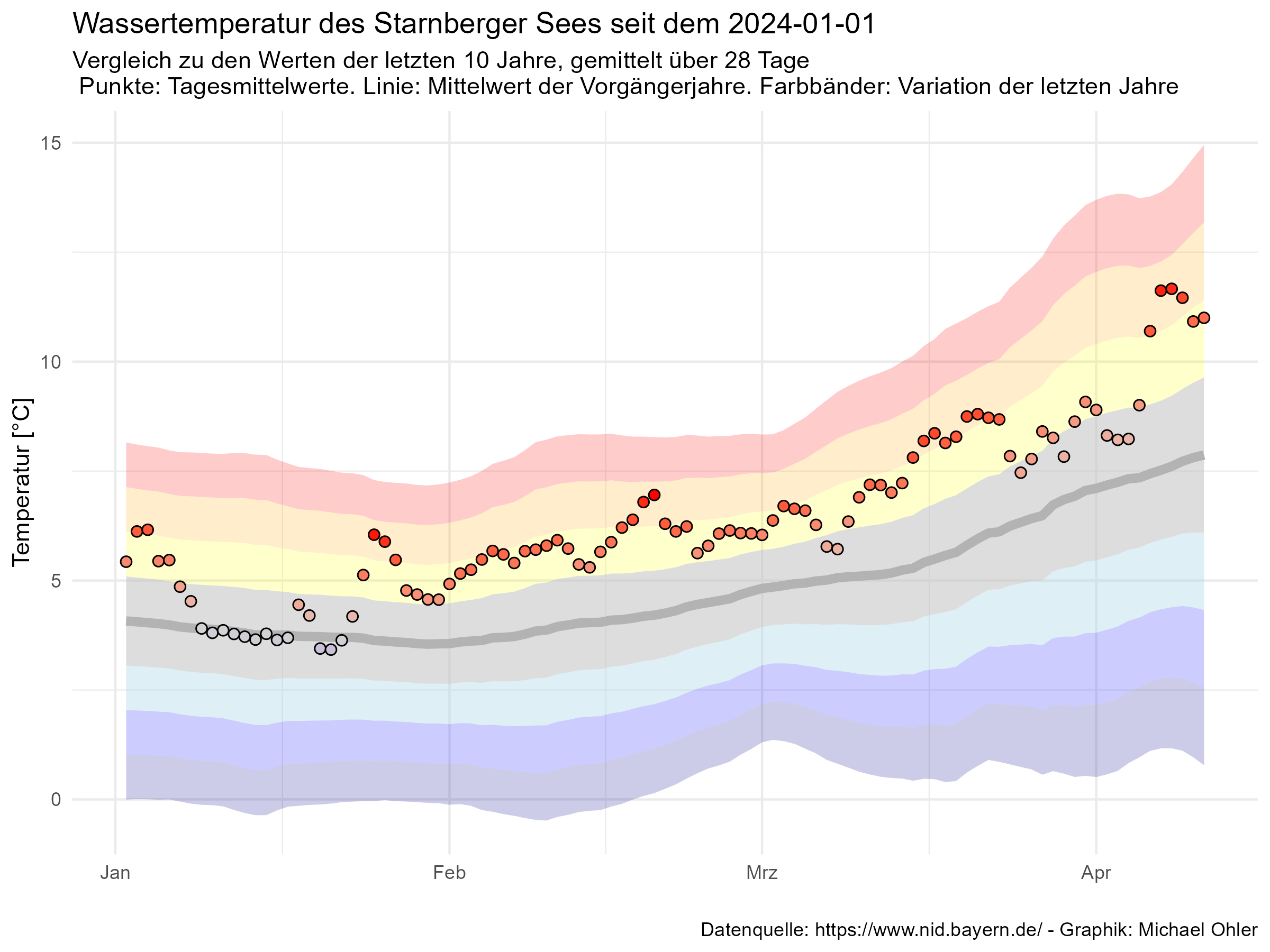
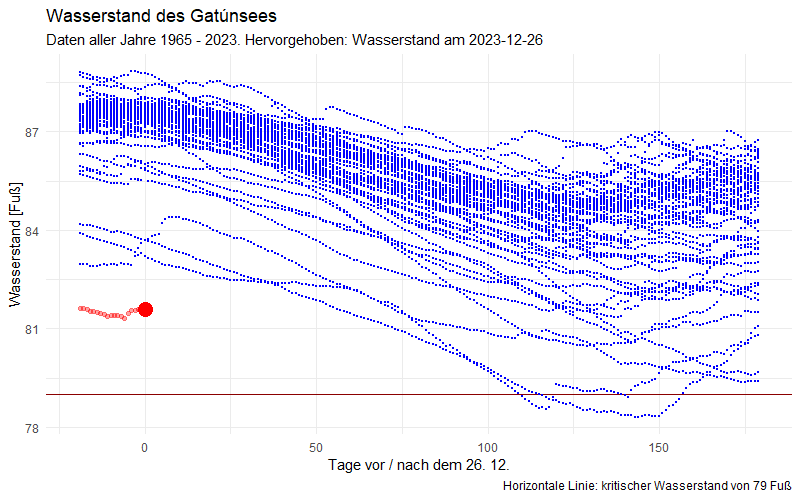
Ich habe nun alle vorliegenden Werte vom 12. Mai 2008 bis zum 31. Dezember 2023 verwendet, um mit der oben angezeigten Formel ein Modell zu „trainieren“ und dieses zu verwenden, um den Verlauf des Jahres 2024 vorherzusagen. Diese Vorhersage vergleiche ich mit den tatsächlich gemessenen Werten:

Die graue Mittellinie ist die Vorhersage des Modells. Für Ende Januar erwarten wir laut Modell die niedrigste Temperatur. Da wir je Woche vorhersagen, ist diese graue Linie gestuft. Um diese Linie herum habe ich „Schläuche“ von je einer, zwei, drei und vier Standardabweichungen gezogen, sodass wir erkennen, dass das Wasser Mitte April außergewöhnlich warm war (und Christian deshalb die Badesaison frühzeitig eröffnen konnte). Kurz darauf wurde das Wasser wieder außergewöhnlich kalt: ein Kälteeinbruch mit Wind und Regen hat für eine deutliche Abkühlung gesorgt (die blauen Punkte Ende April). Seither ist die Temperatur wieder deutlich gestiegen und liegt in den letzten Tagen eher im Bereich des Erwarteten (innerhalb des grauen Bandes von einem Sigma um die Vorhersage).
Stelle Dir vor, Du hast die Daten und ein Analysewerkzeug…
Stelle Dir vor, Du wohnst am Chiemsee, am Steinhuder Meer oder an einem anderen See. Vielleicht gehst Du jeden Tag mit dem Hund am Ufer spazieren. Im Laufe der Jahre weißt Du, wie die Farbe des Sees sich mit den Jahreszeiten ändert und wie er nach einem Sturm aussieht. Vielleicht bist Du nach solch einem Spaziergang neugierig, welchen Einfluss wohl die letzten warmen oder kalten Tage hatten und Du gehst „mal schnell ins Netz“ und erstellst Dir Graphiken wie die oben dargestellten.
Da die Daten immer die gleiche Struktur haben (Datum/Uhrzeit, Temperatur) ist das kein Hexenwerk: auf einer einzigen Webseite lässt sich der Temperaturverlauf aller Seen, der Nordsee, aller Flüsse und Bäche betrachten. Es reicht, wenn irgendjemand diese Daten ins Netz stellt…
Stelle Dir weiter vor, das nicht nur Du, sondern das viele das tun. Irgendwem wird irgendwann bei irgendeinem Gewässer etwas auffallen, was so noch niemand bemerkt hat. Und dann kann diese Person die Geschichte erzählen, vielleicht Alarm schlagen. Im Gemeinderat könntet Ihr einmal im Quartal Euch die Wasserstands- und Temperaturverläufe anschauen. Wir können so achtsamer mit unseren Gewässern umgehen – und Maßnahmen rechtzeitig ergreifen, anstatt erst, wenn es zu spät ist.
Von der Struktur her sehen auch die Wasserstandsdaten genauso aus: Datum/Uhrzeit, Wasserstand. Stelle Dir vor, Du entdeckst bei dem Bach in Deiner Nachbarschaft einen Anstieg – nicht des mittleren Wasserstandes, sondern der Ausschläge nach oben und nach unten: mal ist der Bach fast ausgetrocknet, mal tritt er über die Ufer. Solche Entwicklungen sind schleichend – und können irgendwann, wie wir alle wissen, katastrophale Folgen haben. Stelle Dir vor, Du erkennst hier solch eine Entwicklung in der Frühphase und Du sprichst darüber. Jemand anders bringt das in Zusammenhang mit einem geringeren Baumbestand im Einzugsbereich des Baches. Gemeinsam könntet Ihr Maßnahmen einfordern – auf Grundlage von Daten. Natürlich würden danach Wissenschaftlerinnen und Wissenschaftler die Daten noch einmal „richtig“ unter die Lupe nehmen. Da sie aber angesichts der vielen Gewässer nach der Nadel im Heuhaufen suchen müssten, sind sie dafür auf die „Demokratisierung“ solcher Analysen angewiesen. Und Du und wir alle könnten sie auf diese „Nadeln“ aufmerksam machen.
Stelle Dir weiter vor, genau dafür gibt es eine Webseite und Du könntest „einfach mal schnell“ mit ein paar einfachen Werkzeugen das Gewässer untersuchen, das Du von Deinen Spaziergängen gut kennst…
Da fällt mir gleich noch ein weiterer Anwendungsfall ein…
Nun sind nicht nur die Temperaturverläufe von Gewässern sondern auch die CO2-Konzentration der Erdatmosphäre jahreszeitlichen Schwankungen unterworfen. Auch diese Daten habe die gleiche Struktur: Datum / Konzentration. An der Frage, ob Corona – und die damit einhergehende, geringere wirtschaftliche Tätigkeit der Menschheit – eine Auswirkung auf diesen Verlauf hatte, daran habe ich mir vor Jahr und Tag die Zähne ausgebissen. Ich glaube, mit dem hier vorliegenden Instrumentarium sollte ein neuer Anlauf möglich sein.
Aber das ist eine andere Daten-Geschichte. Und die soll ein andermal erzählt werden…
{kind=link}
{kind=link}
{kind=link}