Damals wie heute ging es um ein Thema, das uns begleitet: Wir haben Herausforderungen – und wir können damit umgehen, wenn wir sie klar benennen. Der „absurde Held“ von Albert Camus bleibt offensichtlich weiterhin ein Anker und die Ethik des Doktor Rieux wichtig.
Mit der Zeit habe ich mich hier stark auf Datenanalyse konzentriert. Viele Themen sind weiterhin aktuell (Klima, Umwelt, Wirtschaft, Demokratie) – und manche Reihen, etwa zu den Corona-Fallzahlen, blicken nach vorn.
Ich weiß, dass einige von euch regelmäßig hereinschauen. Danke dafür!
Mein Ziel war nie, einfach nur zu informieren. Mir ging es vor allem darum zu zeigen: Ihr könnt das selbst.
Die wichtigsten Gespräche führe ich inzwischen mehr im direkten Austausch – in Workshops und Schulungen –, bei denen ich selbst oft am meisten lerne.
Darum habe ich in den letzten Wochen entschieden, diesen Blog einzustellen. Aufgrund der Kündigungsfristen bleibt er noch eine Weile online. Ihr findet mich weiterhin leicht – und erreicht mich am besten direkt.
Ich wünsche allen Leserinnen und Lesern alles Gute. Lasst uns in Kontakt bleiben.
Die Analyse von Umweltdaten ist mehr als eine Spielerei
Daten lassen mich einfach nicht los, solange noch eine nicht-erzählte Geschichte in ihnen steckt. Und so ist das auch mit den Temperaturdaten des Starnberger Sees, dem hier nun der dritte Eintrag gewidmet ist.
Ich halte das jedoch für mehr als einfach nur „Spielerei“:
Zu vielen Gewässern gibt es lange Zeitreihen mit Temperatur- und Wasserstandsdaten
Diese Daten genau zu betrachten ist für unseren achtsamen Umgang mit der Natur wichtig
Sie sind also wertvoll und zudem einfach zu analysieren: „Datum/Uhrzeit – Temperatur“ oder „Datum/Uhrzeit – Wasserstand“
Wenn es gelänge, diese Analysen zu „demokratisieren“, sodass aufmerksame Bürgerinnen oder Anwohner eines Sees oder Flusses sie selbst unternehmen können, dann könnten sie, hoffentlich rechtzeitig, Trends erkennen und, falls nötig, Warnungen aussprechen. Denn bei der Vielzahl der Gewässer kann diese Aufgabe nicht einfach nur ein paar Spezialisten übertragen werden.
Ein simples, lineares Modell der Temperaturentwicklung
Ich habe mit verschiedenen Modellen experimentiert und es geschafft, deren Güte R2 auf über 99% zu bringen. Im Sinne der „Demokratisierung“ der Analyse von Umweltdaten geht es mir jedoch vor allem darum, ein einfach nachvollziehbares Modell aufzubauen.
Das heute verwendete Modell setzt deshalb einen linearen Verlauf der Temperatur voraus, dem eine jahreszeitliche Schwankung überlagert ist:
Temperatur = Linearer Anstieg + Jahreszeitliche Schwankung.
In R ist solch ein Modell mit einer Zeile Code erstellt:
model <- lm(Temp ~ Index + KW, data = df, na.action = na.omit)
Hier steht „lm“ für „lineares Modell“, das den Datenrahmen df verwendet und die Temperatur gegen den laufenden Index der Tage sowie die Kalenderwoche des jeweiligen Jahres untersucht. Dabei werden Tage ohne Eintrag („NA“) weggelassen. So erhalte ich ein Modell mit einer Güte von immerhin 95% und einen mittleren Anpassungsfehler von 1.5°C. Das Modell sagt die tatsächliche Temperatur also mit dieser Genauigkeit (bei einem Sigma) voraus.
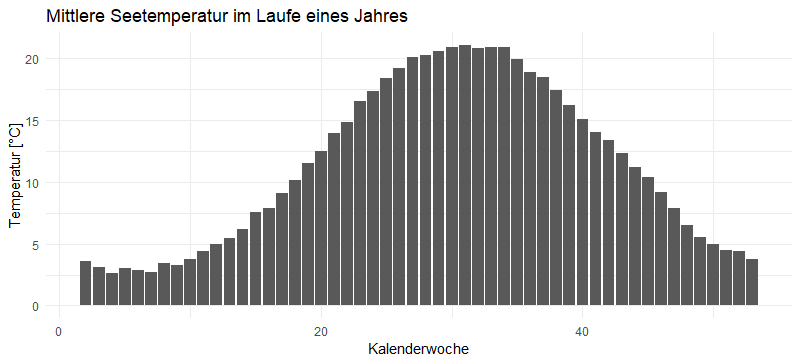
Aus dem „summary“ des Modells lese ich zudem heraus, dass wir es über den betrachteten Zeitraum mit einer Erwärmung von ca. 0,7 – 0,8°C pro 10 Jahre zu tun haben. Das Modell passt auch Woche für Woche den durchschnittlichen Temperaturhub an, sodass wir uns diesen anzeigen lassen können:
Bis auf den Anpassungsfehler des Modells (dargestellt in der nächsten Graphik) durchläuft die Temperatur des Starnberger Sees also diese Temperaturkurve – zusätzlich zu dem stetigen Temperaturanstieg.
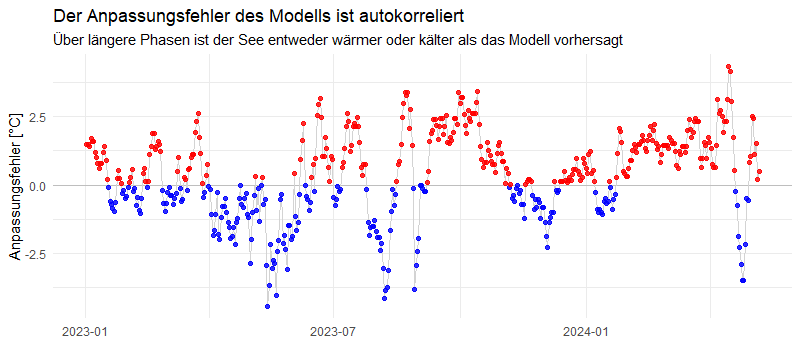
Wir erkennen hier, dass der Anpassungsfehler keineswegs „rein zufällig“ verläuft. Es gibt durchaus längere Zeiträume, über die hinweg die Temperatur deutlich über oder deutlich unter den durch das Modell beschriebenen Werten liegen. Mathematisch formuliert: der Anpassungsfehler ist mit sich selbst korreliert. Wenn eine Abweichung zwischen tatsächlicher und vom Modell vorhergesagter Temperatur eher über der Nulllinie liegt, dann werden auch die darauffolgenden Werte sich eher dort als auf der anderen Seite befinden. Bei einem rein zufälligen Prozess würden sich diese Abweichungen nach oben und nach unten schnell die Waage halten.
Wie ist das Jahr 2024 bisher verlaufen?
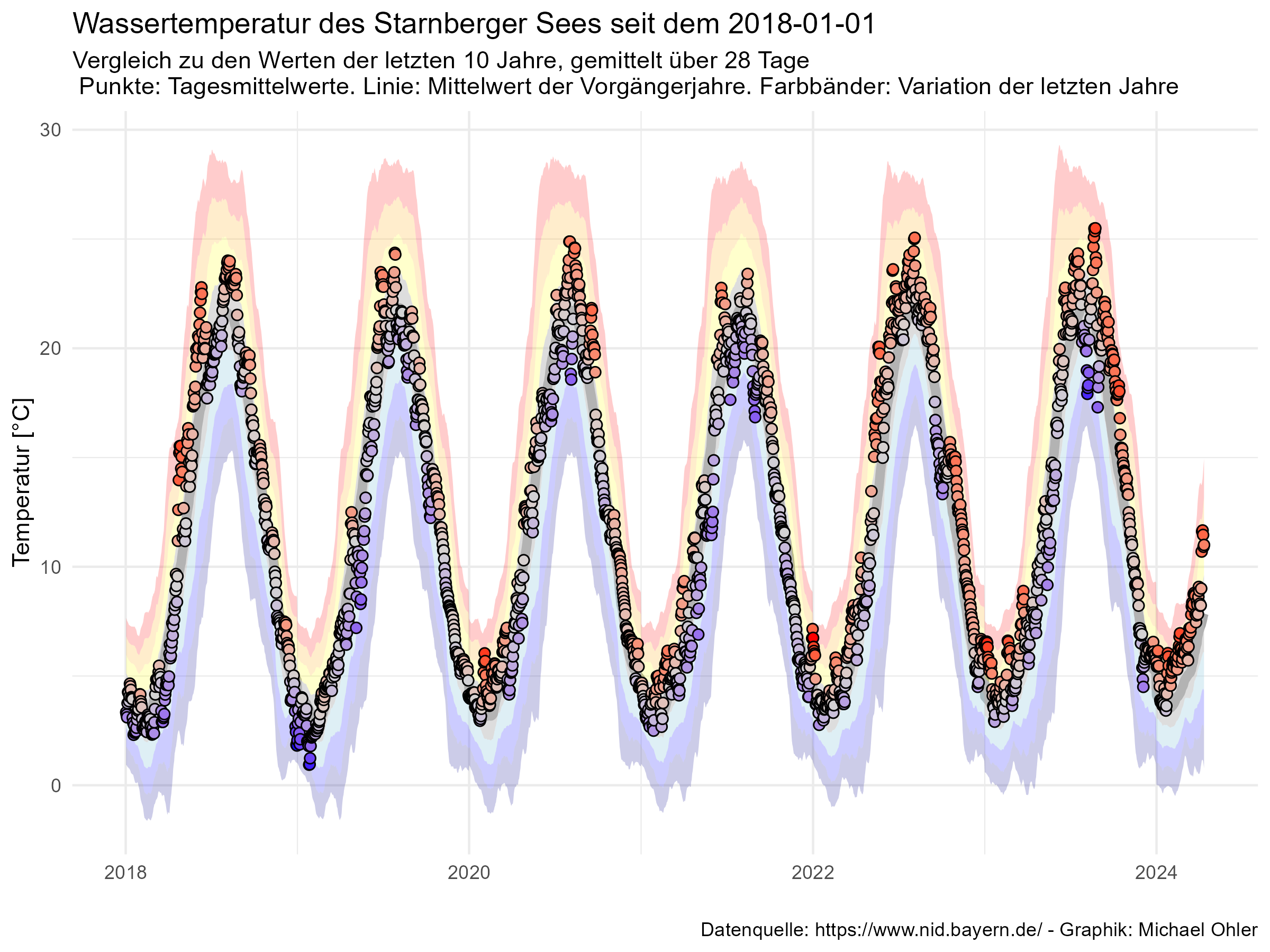
Ich habe nun alle vorliegenden Werte vom 12. Mai 2008 bis zum 31. Dezember 2023 verwendet, um mit der oben angezeigten Formel ein Modell zu „trainieren“ und dieses zu verwenden, um den Verlauf des Jahres 2024 vorherzusagen. Diese Vorhersage vergleiche ich mit den tatsächlich gemessenen Werten:
Die graue Mittellinie ist die Vorhersage des Modells. Für Ende Januar erwarten wir laut Modell die niedrigste Temperatur. Da wir je Woche vorhersagen, ist diese graue Linie gestuft. Um diese Linie herum habe ich „Schläuche“ von je einer, zwei, drei und vier Standardabweichungen gezogen, sodass wir erkennen, dass das Wasser Mitte April außergewöhnlich warm war (und Christian deshalb die Badesaison frühzeitig eröffnen konnte). Kurz darauf wurde das Wasser wieder außergewöhnlich kalt: ein Kälteeinbruch mit Wind und Regen hat für eine deutliche Abkühlung gesorgt (die blauen Punkte Ende April). Seither ist die Temperatur wieder deutlich gestiegen und liegt in den letzten Tagen eher im Bereich des Erwarteten (innerhalb des grauen Bandes von einem Sigma um die Vorhersage).
Stelle Dir vor, Du hast die Daten und ein Analysewerkzeug…
Stelle Dir vor, Du wohnst am Chiemsee, am Steinhuder Meer oder an einem anderen See. Vielleicht gehst Du jeden Tag mit dem Hund am Ufer spazieren. Im Laufe der Jahre weißt Du, wie die Farbe des Sees sich mit den Jahreszeiten ändert und wie er nach einem Sturm aussieht. Vielleicht bist Du nach solch einem Spaziergang neugierig, welchen Einfluss wohl die letzten warmen oder kalten Tage hatten und Du gehst „mal schnell ins Netz“ und erstellst Dir Graphiken wie die oben dargestellten.
Da die Daten immer die gleiche Struktur haben (Datum/Uhrzeit, Temperatur) ist das kein Hexenwerk: auf einer einzigen Webseite lässt sich der Temperaturverlauf aller Seen, der Nordsee, aller Flüsse und Bäche betrachten. Es reicht, wenn irgendjemand diese Daten ins Netz stellt…
Stelle Dir weiter vor, das nicht nur Du, sondern das viele das tun. Irgendwem wird irgendwann bei irgendeinem Gewässer etwas auffallen, was so noch niemand bemerkt hat. Und dann kann diese Person die Geschichte erzählen, vielleicht Alarm schlagen. Im Gemeinderat könntet Ihr einmal im Quartal Euch die Wasserstands- und Temperaturverläufe anschauen. Wir können so achtsamer mit unseren Gewässern umgehen – und Maßnahmen rechtzeitig ergreifen, anstatt erst, wenn es zu spät ist.
Von der Struktur her sehen auch die Wasserstandsdaten genauso aus: Datum/Uhrzeit, Wasserstand. Stelle Dir vor, Du entdeckst bei dem Bach in Deiner Nachbarschaft einen Anstieg – nicht des mittleren Wasserstandes, sondern der Ausschläge nach oben und nach unten: mal ist der Bach fast ausgetrocknet, mal tritt er über die Ufer. Solche Entwicklungen sind schleichend – und können irgendwann, wie wir alle wissen, katastrophale Folgen haben. Stelle Dir vor, Du erkennst hier solch eine Entwicklung in der Frühphase und Du sprichst darüber. Jemand anders bringt das in Zusammenhang mit einem geringeren Baumbestand im Einzugsbereich des Baches. Gemeinsam könntet Ihr Maßnahmen einfordern – auf Grundlage von Daten. Natürlich würden danach Wissenschaftlerinnen und Wissenschaftler die Daten noch einmal „richtig“ unter die Lupe nehmen. Da sie aber angesichts der vielen Gewässer nach der Nadel im Heuhaufen suchen müssten, sind sie dafür auf die „Demokratisierung“ solcher Analysen angewiesen. Und Du und wir alle könnten sie auf diese „Nadeln“ aufmerksam machen.
Stelle Dir weiter vor, genau dafür gibt es eine Webseite und Du könntest „einfach mal schnell“ mit ein paar einfachen Werkzeugen das Gewässer untersuchen, das Du von Deinen Spaziergängen gut kennst…
Da fällt mir gleich noch ein weiterer Anwendungsfall ein…
Nun sind nicht nur die Temperaturverläufe von Gewässern sondern auch die CO2-Konzentration der Erdatmosphäre jahreszeitlichen Schwankungen unterworfen. Auch diese Daten habe die gleiche Struktur: Datum / Konzentration. An der Frage, ob Corona – und die damit einhergehende, geringere wirtschaftliche Tätigkeit der Menschheit – eine Auswirkung auf diesen Verlauf hatte, daran habe ich mir vor Jahr und Tag die Zähne ausgebissen. Ich glaube, mit dem hier vorliegenden Instrumentarium sollte ein neuer Anlauf möglich sein.
Aber das ist eine andere Daten-Geschichte. Und die soll ein andermal erzählt werden…
In meinem letzten Beitrag habe ich Temperaturdaten des Starnberger Sees untersucht und mit einer recht hemdsärmeligen Methode eine Erwärmung über den Betrachtungszeitraum gefunden. Allerdings habe ich für diese Untersuchung jeweils nur den Höchst- und den Tiefstwert eines jeden Jahres verwendet und so aus dem reichen Schatz der Daten mit mehr als 133000 Messwerten von über 5500 Tagen nur einen verschwindend kleinen Teil der Information, nämlich die jeweiligen Höchst- und Tiefstwerte eines jeden Jahres, genutzt. Wenn Du Dich mit Daten beschäftigst, dann würde auch Dich das wurmen.
Deshalb möchte ich heute nachlegen. Es geht mir zunächst um eine graphische Darstellung. Dafür habe ich ein wenig „knobeln“ müssen und einige Methoden ausprobiert. Und ich war froh, dass mir dazu die Analysesprache R zur Verfügung steht. Da ich mich derzeit auch in Python einarbeite und ich, zumindest was die graphischen Möglichkeiten angeht, noch nicht so ganz zufrieden bin (was auch an meinen begrenzten Fähigkeiten liegen mag), möchte ich gerne eine „Python Challenge“ aussprechen:
Kannst Du, kann irgend jemand mit vernünftigem Aufwand die folgenden Graphiken in Python nachbauen? Meinetwegen können wir auch Excel, Minitab, SPSS & Co mit einschließen. Ich glaube aber, diese Werkzeuge scheiden schon an der Startlinie aus. Schreib‘ mich gerne an, wenn es Dir gelingt!
Zunächst geht es hemdsärmelig weiter
Die Schwierigkeit der Analyse besteht darin, dass die Temperatur des Sees jahreszeitlichen Schwankungen unterliegt: Im Winter ist das Wasser kalt und im Sommer warm. Es gibt zudem sowohl kalte als auch warme Sommer und Winter. Und auch die Erwärmung im Frühling oder die Abkühlung im Herbst könnte früher oder später einsetzen. Wie also macht man einen langfristigen Trend, so es ihn denn gibt, sichtbar?
Die „richtige“ Herangehensweise wäre, Werkzeuge der Zeitreihenanalyse wie ARIMA zu verwenden. Vor mehr als 15 Jahren habe ich mich darin eingearbeitet, das jedoch nie wieder verwendet. Deshalb möchte ich mich zunächst einmal darum „herummogeln“ und schauen, wie ich eigenhändig weiterkomme. Vermutlich im nächsten Beitrag werde ich mich dann um diese Werkzeuge kümmern.
Der Vergleich zu den Vorjahren
Eine erste Idee besteht darin, den jeweiligen Tag eines jeden Jahres zu nehmen. Der erste Januar ist der Tag 1 und der 31. Dezember der Tag 365. Wir könnten dann Tag für Tag die Mittelwerte der vergangenen 5 oder auch 10 Jahre berechnen und dieser Mittelwert mit dem im Folgejahr am Vergleichstag gemessenen Wert vergleichen.
Das habe ich ausprobiert. Da aber eben die Erwärmungs- und Abkühlungsphasen mal früher und mal später einsetzen, führt das zu einer höheren Variation dieser Mittelwerte und damit der Referenzwerte.
Deshalb habe ich das Zeitfenster des Vergleichs variabel gemacht. Sagen wir, ich möchte wissen, ob der See am Tag 109 dieses Jahres (am heutigen 18. April) im Vergleich zu den Vorgängerjahren eher wärmer oder eher kälter war. In meinem Code kann ich jetzt einstellen, dass ich einstellbar zum Beispiel 5 oder 10 Jahre zurückschauen möchte. Ich kann auch einstellen, dass ich für den Vergleichszeitraum aus jedem dieser Jahre ein Zeitfenster von plus und minus beispielsweise 14 Tagen auswählen möchte. Über all diese Tage berechne ich dann den mittleren Wert (Median) und die typische Variation (Standardabweichung). Da die Messbehörde an manchen Tagen besonders „fleißig“ war und häufiger als sonst die Wassertemperatur gemessen hat, habe ich vorher den Mittelwert all dieser Tageswerte gebildet, um nicht bestimmte Tage bevorzugt zu berücksichtigen, nur weil an ihnen häufiger gemessen wurde.
Um zu beurteilen, ob der heutige Wert stark von der Vergangenheit abweicht, vergleiche ich den Unterschied zwischen historischem Median und heutigem Messwert mit der Standardabweichung dieser historischen Vergleichswerte: Liegt der Unterschied zwischen plus/minus einer Standardabweichung, dann sage ich: alles gut, das kommt vor. Eine Abweichung um eine, zwei, drei oder mehr Standardabweichungen nach oben oder nach unten zeigt hingegen eine immer stärkere Auffälligkeit an. In der folgenden Graphik stelle ich das bildlich dar. Die Farbbänder geben dabei die Bänder von einer, zwei und drei Standardabweichungen in beide Richtungen an: warme Farben für Abweichungen nach oben und kalte für Abweichungen nach unten.
Zugegeben: das ist eine nicht ganz leicht verdauliche Graphik. Du kannst sie wie folgt lesen. Wenn eine Abkühlungsphase wie im Herbst 2022 vor allem rötlich gefärbt ist, dann hat sich der See in dem Jahr später als früher abgekühlt. Für die Sommermonate dominiert über alle Jahre hinweg die rote Farbe: die Sommer sind wärmer geworden. Auch die Tiefpunkte im Winter sind – mit Ausnahme des Winters 2019 – vor allem durch wärmere Temperaturen geprägt.
Interessant sind auch Phasen, an denen die Temperaturpunkte zwischen rötlichen („wärmer als in den 10 vorherigen Jahren“) und bläulichen („kälter als vorher“) Farbtönen springen. Das siehst Du zum Beispiel für den Winter 2022/2023. Ich halte das nicht für Fehler oder Ungenauigkeiten in den Daten. Wer einmal im Starnberger See weiter hinausgeschwommen ist, der weiß, dass es recht kräftige Strömungen gibt. Ich nehme also an, dass wir hier den Effekt von sich – aufgrund von Wind und Wetter – ändernden kalten und warmen Strömungen sehen. Diese Effekte werden bei der Mittelwertbildung „herausgemittelt“, sind aber bei den Tagesdaten durchaus vorhanden.
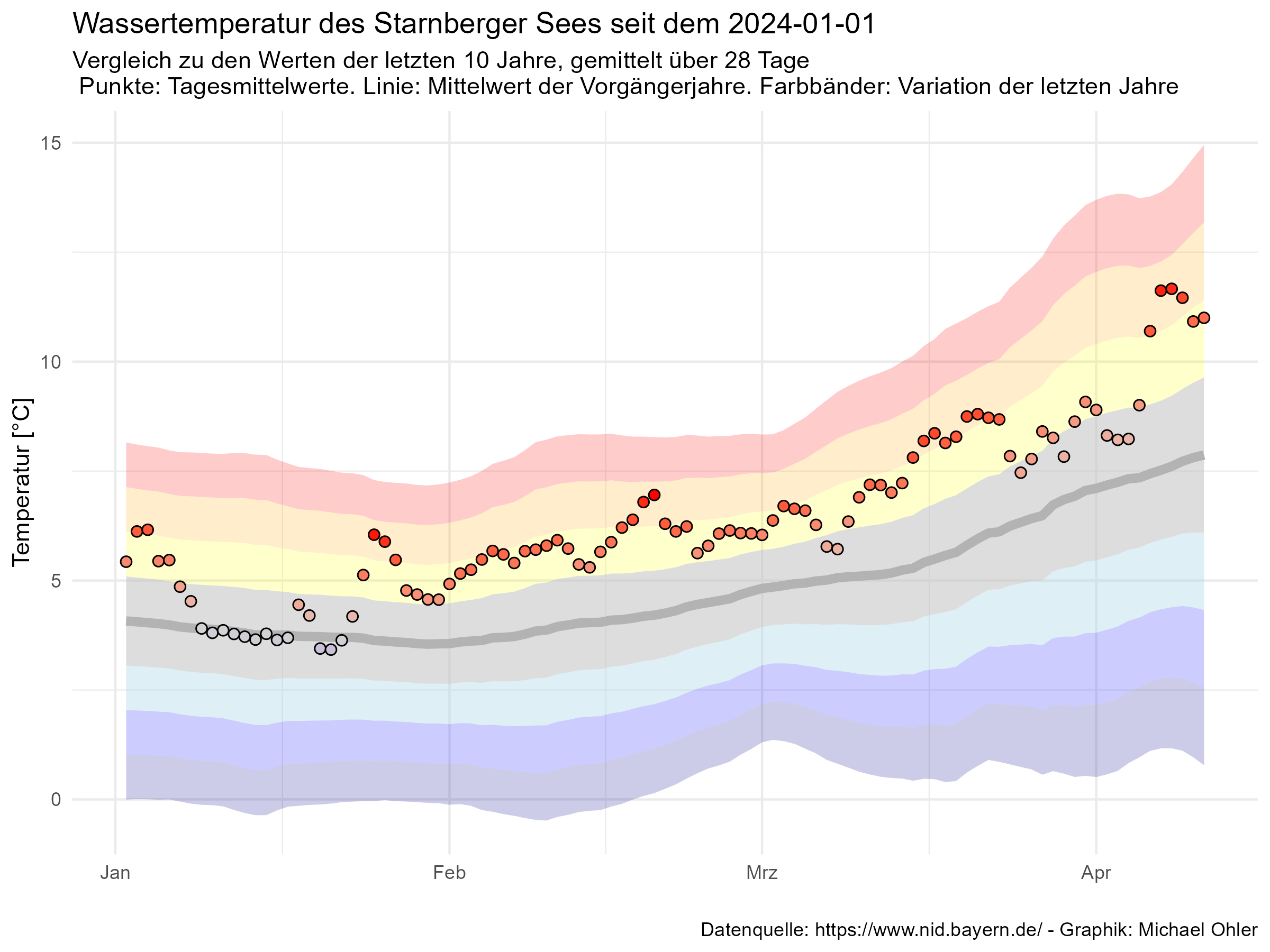
Die folgende Graphik zeigt aus der vorherigen Graphik den Ausschnitt seit Beginn dieses Jahres:
Sehr deutlich erkennbar liegen die Temperaturen deutlich über denen der Vorgängerjahre – und es ist kein Wunder, dass mein Freund Christian am letzten Wochenende bei behaglichen 12°C Wassertemperatur die Badesaison eröffnet hat. Diese Temperaturen liegen in dem orange dargestellten Band von zwei bis drei Standardabweichungen über dem mittleren Wert der Vorgängerjahre.
Um wie viel ist der See nun „wirklich“ wärmer geworden?
Das ist tatsächlich eine kniffelige Frage und ich habe einige Zeit gebraucht, um eine mir sinnvoll erscheinende Methode der Bewertung zu finden. Wenn Du die obere erste Graphik betrachtest, dann siehst Du, dass die Temperaturwerte mal nach oben (rot) und mal nach unten (blau) abweichen. Du kannst nun sagen: „Ja klar, das kommt natürlich vor. ‚Im Schnitt‘ gleicht sich das aber aus“.
Wenn dem so wäre, dass sich das „im Schnitt ausgleicht“, dann sollten sich die Abweichungen nach oben und nach unten die Waage halten. Für die folgende Diskussion möchte ich Dir einen konkreten Blick auf die Daten geben:
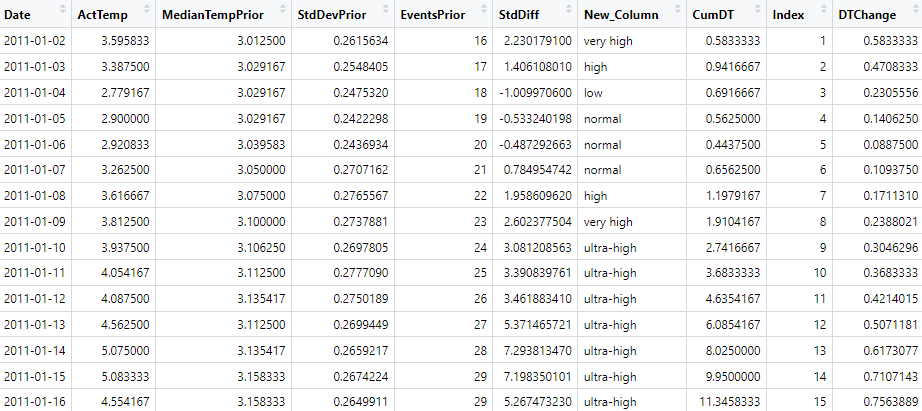
Du siehst hier das Datum, die „aktuelle Temperatur“ (gemittelt über alle verfügbaren Messwerte) an dem jeweiligen Tag, den historischen Median, die historische Standardabweichung und wie viele Tagesmittelwerte der Berechnung von Median und Standardabweichung zugrunde gelegen haben. In der Spalte CumDT („kumuliertes Delta der Temperatur“) rechne ich zunächst den Unterschied der Werte in Spalte 2 und 3 aus: das ist die jeweilige Temperaturabweichung. Für den 2. Februar beträgt sie 0.8333 Grad. Diese Abweichung addiere ich zu dem Temperaturunterschied des 3. Februar hinzu und erhalte dann 0.9417 Grad – und so weiter. Wenn sich diese Abweichungen nach oben und nach unten die Waage halten würden, dann würde diese Summe über die gesamte Tabelle hinweg berechnet klein bleiben. In der Spalte DTChange dividiere ich diese Summe noch durch den laufenden Index, also die Anzahl der Werte, die ich in CumDT bis zur entsprechenden Zeile aufsummiert habe. Am Ende des Betrachtungszeitraum steht so die „Nettoabweichung“ von aktueller zur historischen Vergleichstemperatur.
Dieses „Nettoabweichung“ lässt sich über den Betrachtungszeitraum hinweg auch graphisch darstellen:
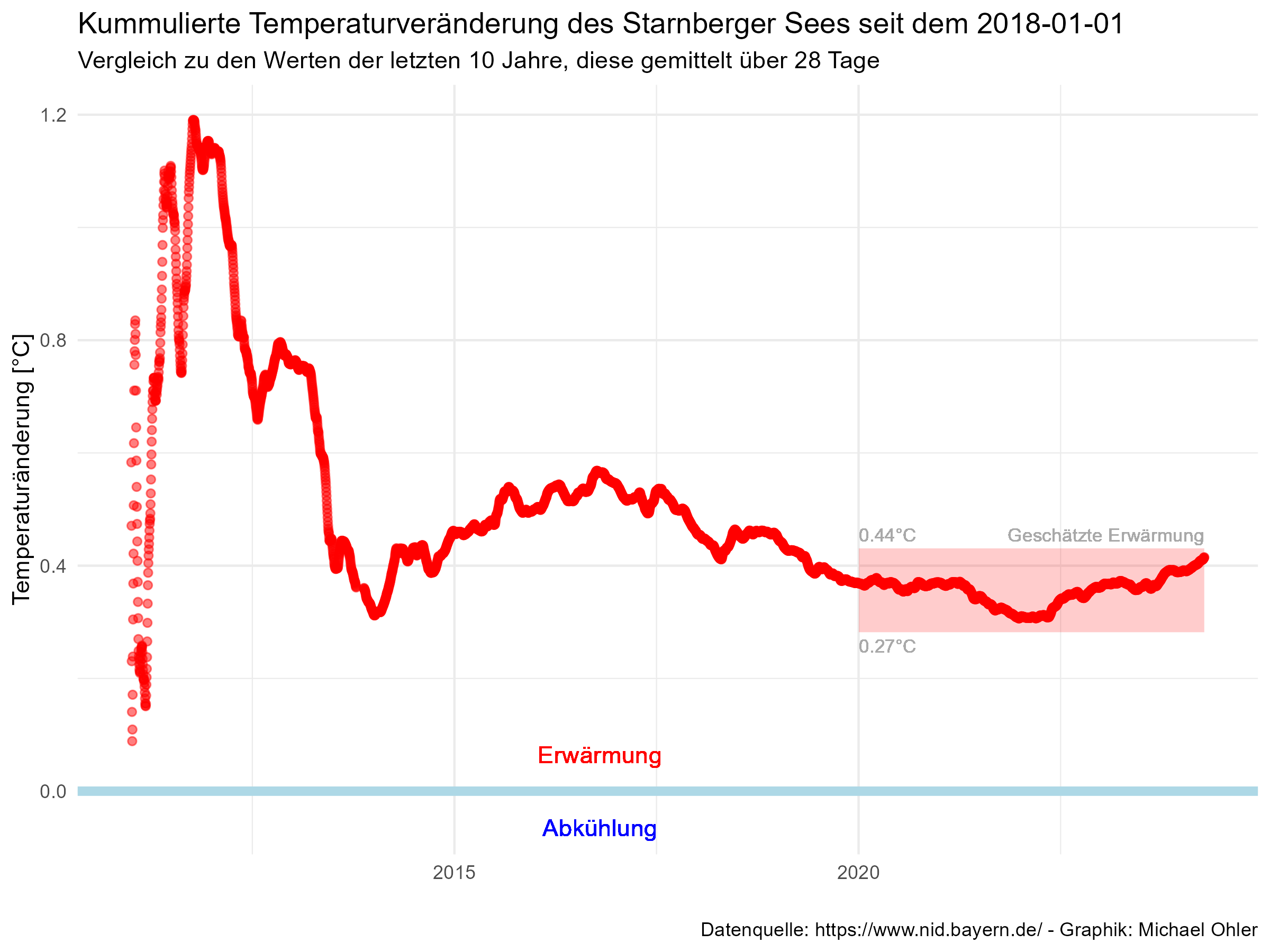
Zu Beginn steigen die Werte zunächst an: eine „Wärmephase“, dann fallen sie wieder ab, eine „Kältephase“. Je mehr Werte hinzukommen, desto weniger spielen solche Wärme- und Kältephasen jedoch eine Rolle, weil sie sich tatsächlich über den Betrachtungszeitraum hinweg „wegmitteln“. Allerdings schwingt sich die Kurve nicht um die Null-Linie (hellblau) herum ein. Sie liegt vielmehr durchgehend oberhalb und damit im Bereich der Erwärmung.
Ich verwende dann den Zeitraum seit dem Beginn des Jahres 2020, um diese Erwärmung abzuschätzen und berechne für diesen Zeitraum Mittelwert und Standardabweichung von DTChange. In der Graphik angezeigt ist der Bereich von plus/minus drei Standardabweichungen. So kommen wir zu der Aussage:
In den letzten 10 Jahren hat sich der Starnberger See tatsächlich erwärmt. Mit unserer hemdsärmeligen Methode ermitteln wir eine Erwärmung von ca. 0.3-0.4°C über einen Zeitraum von 10 Jahren.
Das mag nicht nach viel erscheinen und andere mögen beurteilen, welche Auswirkungen es hat. Aber es ist signifikant.
Lasst uns Umweltdaten aufbereiten!
Ich muss die Daten noch mittels ARIMA anschauen. Eine andere Idee besteht darin, auch neuronale Netze einzusetzen. Mal sehen, was ich im Laufe der nächsten Wochen bewerkstelligen kann.
Ich glaube jedoch, dass es auch jetzt schon losgehen kann: vielleicht finden sich beim Ammersee oder irgend einem anderen Gewässer Auffälligkeiten der Temperatur oder des Wasserstandes? Es liegen zu sehr vielen bayrischen und deutschen Gewässern Daten öffentlich vor. Sie müssen „nur noch“ analysiert werden.
Wenn Du bei einer Versicherung arbeitest oder in Gewässernähe bauen möchtest, dann könnten solche Analysen durchaus interessant sein. Aber vielleicht interessierst Du Dich auch „einfach nur so“ für den Fluss in Deiner Nähe und möchtest wissen, wie ungewöhnlich Temperatur oder Wasserstand heute im Vergleich zur Vergangenheit sind?
Melde Dich gerne, wenn Du Dich dafür interessierst!
Neulich war ich wieder einmal in Starnberg zu Besuch bei meinen Freunden Renate und Christian. Für mich sind sie Vorbilder eines umweltbewussten Lebensstils. Letztlich geht es auch auf sie und eine Diskussion mit unserer Tochter, dazumal noch bei Fridays for Future, zurück, dass ich seit Anfang 2020 innerhalb von Europa nicht mehr beruflich geflogen bin. Von Hamburg nach Brno, Lausanne, München oder Paris fahre ich seither und bis heute konsequent mit dem Zug.
Renate und Christian habe ich auch von meinen Untersuchungen zum Wasserstand im Panamakanal erzählt. So kamen wir auch auf den Starnberger See zu sprechen. Sehen wir auch hier den Einfluss des Klimawandels?
Ein Dank an die Obrigkeit!
Als Landschaftsarchitekt kennt Christian eine Datenquelle: den Gewässerkundlichen Dienst Bayern. Wenn Du Dich für Wasserstand und -temperatur von Gewässern interessierst, dann stellt diese Webseite eine wahre Fundgrube dar.
Zugegeben: Du kannst die Daten nicht einfach per Skript von einer URL einlesen, wie das für die CO2-Daten des Mauna Loa Observatoriums möglich ist. Die Daten kommen auch in mehreren Tabellen daher, die man miteinander verbinden muss. Aber wenn Du die Anfrage stellst, dann hast Du innerhalb weniger Minuten den Download-Link.
Und es ist eine wahre Freude, diesem „geschenkten Gaul“ ins Maul zu schauen: Seit dem Jahr 2008 liegen zum Starnberger See Messdaten in hoher Granularität vor, oft mit mehreren Messwerten pro Tag.
Ein Lob an dieser Stelle auf unsere öffentliche Verwaltung, die Qualität ihrer Arbeit und die Transparenz!
Der Starnberger See wird immer wärmer!
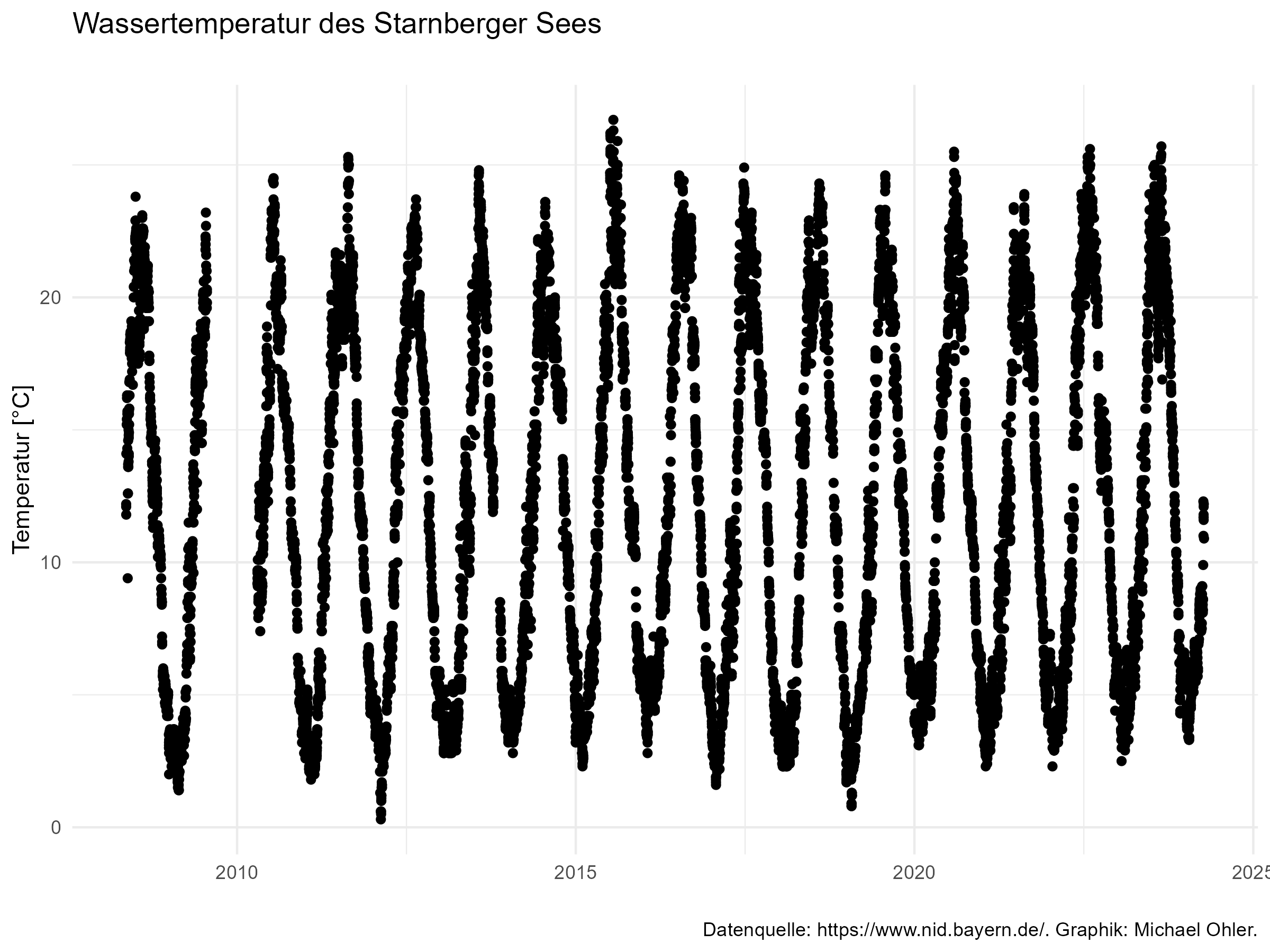
Um die Daten graphisch darzustellen, ziehe ich eine Zufallsstichprobe der Größe 10.000 aus den über 130.000 Messwerten:
Das geschulte Auge erkennt, dass der Sommer 2015 besonders warm war: die Kurve geht da besonders weit nach oben.
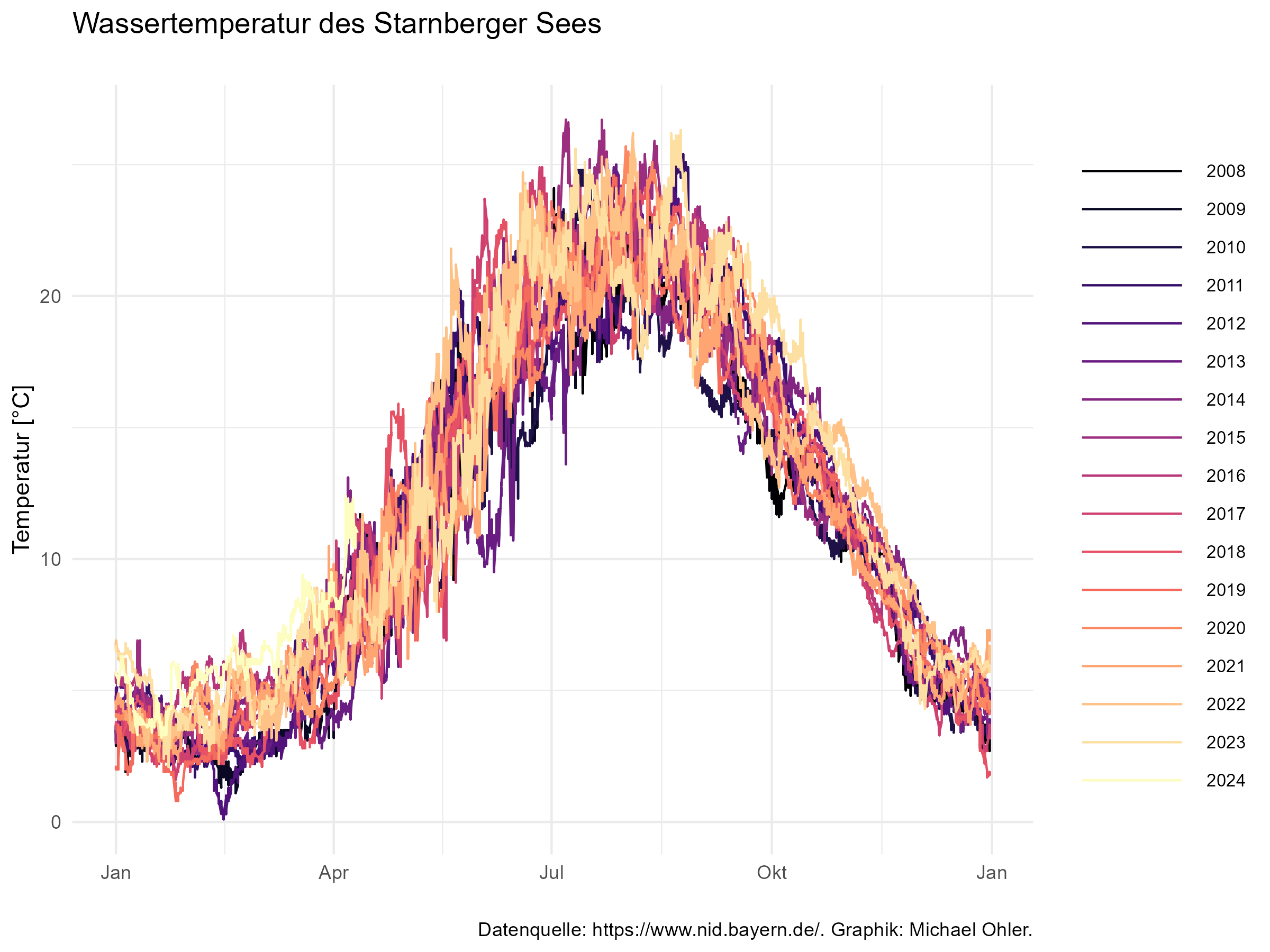
Schauen wir uns zunächst den Jahresverlauf an:
Zugegeben: das Ergebnis sieht recht wild aus. Um dem Auge zu helfen, habe ich deshalb die Farbpalette so gewählt, dass die frühen Jahre einer kalten und die späteren einer immer wärmeren Farbe zugeordnet werden. Wir erkennen am unteren Rand der Temperaturkurven eher kalte und am oberen Rand eher warme Farben:
Wird der See immer wärmer?
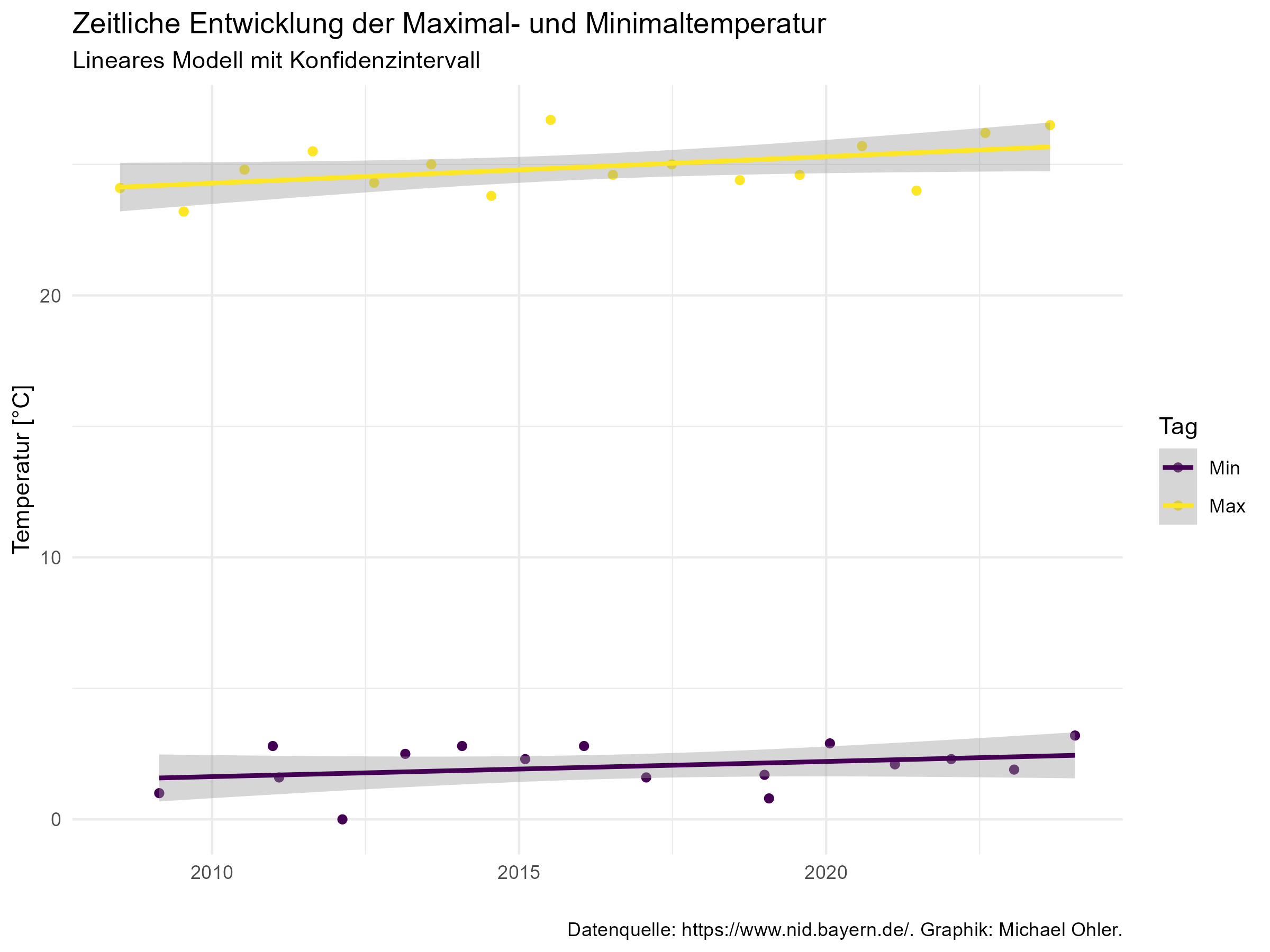
Um dieser Frage nachzugehen, ziehe ich aus allen Daten Jahr für Jahr den Datensatz mit der jeweils höchsten und der niedrigsten gemessenen Temperatur heraus und stelle diese wie folgt graphisch dar:
Dank der Hilfe der Ausgleichsgeraden durch diese Temperaturwerte erkennt man tatsächlich einen Anstieg. Ein statistisches Regressionsmodell zeigt, dass dieser Anstieg bei einem P-Wert von 2,4% auch tatsächlich signifikant ist. Aus der so ermittelten Steigung dieser beiden Geraden können wir schließen:
Über den betrachteten Zeitraum wurde der Starnberger See im Laufe von 12,5 Jahren um ein Grad wärmer.
Die Analyse von Umweltdaten muss „demokratisiert“ werden
Ob diese Ergebnisse mit dem Klimawandel zusammenhängen? Das mögen andere beurteilen.
Wichtig erscheint, dass diese wertvollen Daten aufbereitet und untersucht werden sollten. Für freischaffende Blogger wie mich wäre das angesichts des Reichtums allein der Daten, die vom Gewässerkundlichen Dienst Bayern bereitgestellt werden, eine Mammutaufgabe. Nun könnte man dort studentische Hilfskräfte einstellen und so diese und ähnliche Untersuchungen (zum Beispiel zu den gemessenen Wasserständen oder der Temperaturentwicklung anderer Gewässer) anstellen.
Solch ein Herangehen erscheint aber erstens aufwendig. Denn es gibt Daten zu einer großen Anzahl von Gewässern. Zweitens und viel ärgerlicher noch: schon kurze Zeit nach diesen Untersuchungen käme bestimmt die Frage auf: „Wie sieht es eigentlich jetzt aus?“ – Und die Analysen müssten wiederholt werden.
„Statische“ Analysen – so wie hier – sind nicht geeignet. Es braucht „dynamische“ Werkzeuge mit Zugriff auf tagesaktuelle Daten.
Wird dieser Weg ein leichter sein?
Deshalb gibt es meiner Ansicht nach nur einen Weg:
Die Daten müssen in einem maschinenlesbaren und möglichst über die verschiedenen Gewässer hinweg standardisierten Format direkt online abrufbar sein: So wie die CO2-Daten des Mauna Loa Observatoriums auf Hawaii.
Auf Grundlage dieser Daten wird in einem „open source“ Projekt eine App erstellt – ähnlich meiner eigenen „Umwelt-App“ (eine Art „funktionaler Prototypen“ für das, was wir bauen könnten) – mit der jedermann und jedefrau die Daten selbst erkunden kann.
Denn so können alle, die sich für Temperatur oder Wasserstand eines Gewässers, oder für andere Umweltdaten interessieren, die Daten selbst erkunden und Entwicklungen und außergewöhnliche Ereignisse identifizieren, diskutieren und melden.
Weil Umweltdaten von öffentlichem Belang sind, müssen sie nicht nur frei verfügbar sein. Wir müssen auch die Möglichkeit demokratisieren, diese Daten zu erkunden.
Technisch erscheint das wahrlich kein Hexenwerk. Ich werde in den nächsten Wochen einmal auf den Gewässerkundlichen Dienst zugehen.
Wenn Du in der einen oder anderen Form mitmachen kannst oder möchtest – und sei es, weil Du jemand bei diesem oder einem anderen Dienst kennst, oder weil Du diesem Anliegen bei Entscheidungsträgern Gehör verschaffen kannst, dann melde Dich gerne!
Meiner Ansicht nach geht es um Folgendes:
Beim Gewässerkundlichen Dienst bewirken, dass die Datenverfügbarkeit standardiesiert und vereinfacht wird
Eine App bauen (bisher nutze ich R, Python ist ebenfalls denkbar), die erlaubt, die Erkundung dieser Daten zu „demokratisieren„.
Workshops abhalten, in denen Menschen ausprobieren können, was sie anhand der Daten über die Gewässer erfahren können, für die sie sich interessieren.
Wenn das nach einem „Just-do-it-Projekt“ für Dich klingt, dann auf und los!
Es ist einige Zeit vergangen seit meinem letzten Blogeintrag.
Ein Nachtrag
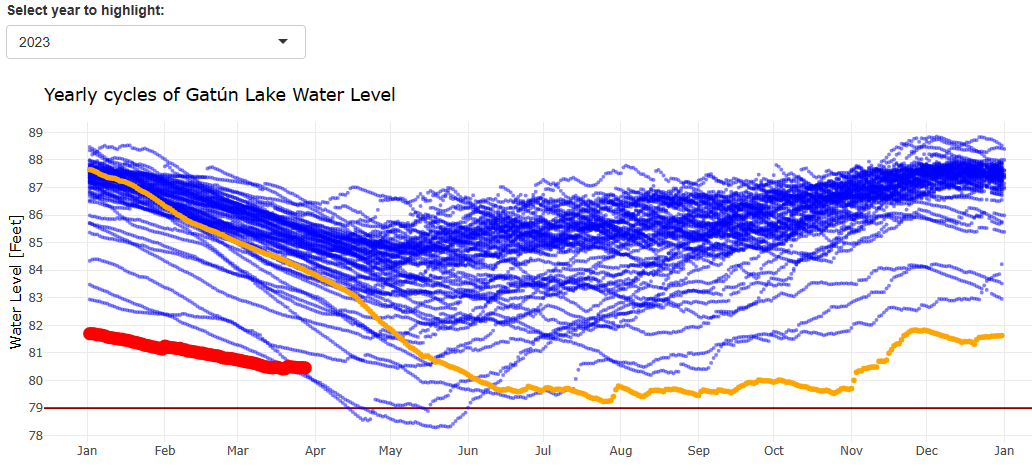
Kurz zum letzten Eintrag: Es zeichnet sich inzwischen eine Entwicklung am Panamakanal ab. Die folgende Graphik habe ich mit meiner eigenen App erstellt. Wir erkennen, dass die Kanalbehörden sparsam mit dem verfügbaren Wasser umgehen (müssen). Der Kanal operiert mit geringerer Kapazität – aber dazu sind (mir) leider keine Daten verfügbar. Falls Du eine Quelle kennst, dann schreibe mich gerne an!
Mit der App am 28. 3. 2024 erstellter Screenshot. Hervorgehoben sind der Verlauf des Wasserstandes im Gatún-See für das Jahr 2023 (orange) und das Jahr 2024 (rot).
Es ist Frühling: die Kirschblüten blühen so schön
Wir leben in Wedel. Hier befindet sich nicht zuletzt auch die „Schiffsbegrüßungsanlage“ des Hamburger Hafens. Seit Jahrzehnten wird in Hamburg das japanische Kirschblütenfest begangen und auch wir waren zweimal in „Planten und Blomen“ dabei. Manche meiner Freunde teilen derzeit Bilder von Kirschblüten und in manchen Straßen ist es eine wahre Pracht.
Nicht umsonst also wird das Kirschblütenfest in Japan seit über 1000 Jahren begangen – und dokumentiert. Historikerinnen und Historiker haben sich durch die Quellen gearbeitet und Jahr für Jahr das Datum des Beginns der Kirschblüte veröffentlicht. Verfügbar sind ihre Daten über diese Quelle: Paleo Data Search | Study | National Centers for Environmental Information (NCEI) (noaa.gov).
Yasuuki Aono hat Daten bis hin zum Jahr 2021 zusammengetragen. Diese Daten verwende ich hier: „Historical Series of Phenological data for Cherry Tree Flowering at Kyoto City„. Wenn Du eine Quelle hast, die bis heute aktualisiert wird, dann bin ich daran interessiert – denn die Daten sind wertvoll, da sie so einen langen Zeitraum überstreichen, und es ist interessant und wichtig zu sehen, wie es weitergeht. Ich habe mir die Daten heruntergeladen, lese sie mit folgendem R-Skript ein und bereite sie auf:
# Daten einlesen:
df <- read_excel("040_KyotoFullFlowerW.xls", skip = 15)[, 1:5]
# Spaltennamen vereinfachen:
colnames(df) <- c("Year",
"DOY",
"Date.Coded",
"Source",
"Reference")
# Mit dieser Datumsinformation erstellen wir später die Graphiken:
df$Date <- make_date(year = year(Sys.Date()),
month = 1,
day = 1) + days(df$DOY - 1)
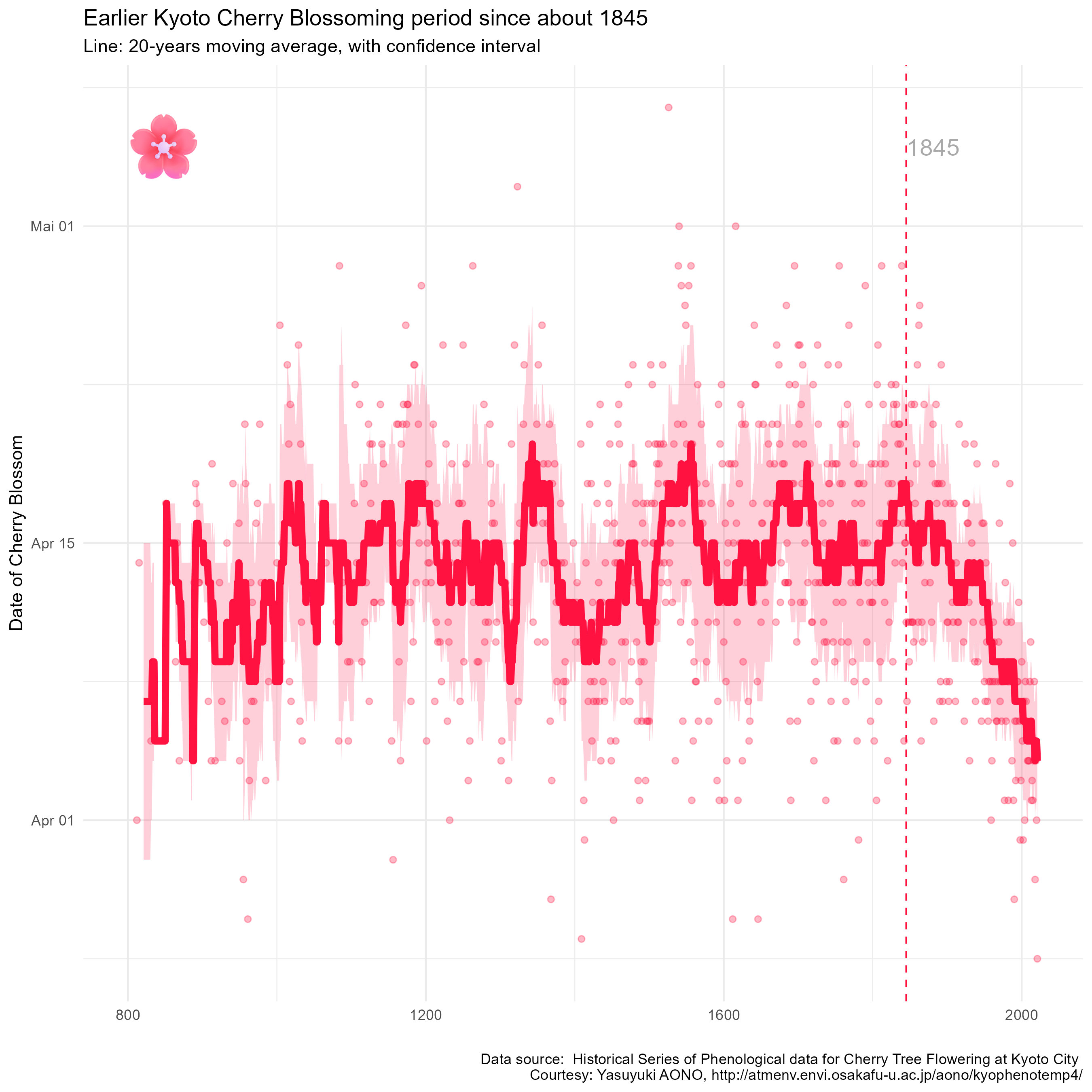
Erkennbar sind (siehe dafür die Graphik ganz unten), dass der Beginn der Kirschblüte von Jahr zu Jahr stark schwanken kann. Aber es ist auch ersichtlich, dass sie in den letzten 150 Jahren tendenziell früher begonnen hat.
Datenaufbereitung
Das möchte ich mir genauer ansehen. Dafür berechne ich Jahr für Jahr einen gleitenden Mittelwert über eine frei wählbare Zeitspanne („span“). Für die jeweilige Spanne bestimme ich ebenso die Standardabweichung. Es mag nicht besonders elegant sein (R-Profis rümpfen die Nase, wenn ich eine Schleife verwende), aber es ist eben doch auch schnell getan und so erstelle ich mir eine neue Tabelle res (wie „result“, also „Ergebnis“) wie folgt:
# Vorbereitungen:
start <- min(df$Year)
end <- max(df$Year)
span <- 20 # Über diese Spanne wird der Mittelwert ermittelt
res <- NULL # Initialisierung der Tabelle res
# Erstellung von gleitendem Mittelwert und Standardabweichungen:
for (y in (start+span):end) {
temp <- df %>%
filter(Year <= y,
Year >= y-span)
append <- data.frame(
Year = y,
Moving.Average = round(mean(temp$DOY, na.rm = TRUE), 0),
SD = sd(temp$DOY, na.rm = TRUE)
)
res <- rbind(res, append)
}
# Wir erzeugen noch einen "optisch ansprechenden "Vertrauensschlauch":
alpha <- 0.4 # frei wählbar
z <- qnorm(1 - alpha / 2) # z-Wert für 95% CI
res$LowerCI <- round(res$Moving.Average - z * res$SD, 0)
res$UpperCI <- round(res$Moving.Average + z * res$SD, 0)
res$Date <- make_date(year = year(Sys.Date()),
month = 1,
day = 1) + days(res$Moving.Average - 1)
res$Date.UCL <- make_date(year = year(Sys.Date()),
month = 1,
day = 1) + days(res$UpperCI - 1)
res$Date.LCL <- make_date(year = year(Sys.Date()),
month = 1,
day = 1) + days(res$LowerCI - 1)
So lässt sich dann folgende Graphik erzeugen:
# Zunächst die Werte selbst:
p <- ggplot() +
geom_point(data = df,
aes(x = Year,
y = Date))
# Wir fügen den "Schlauch für den Vertrauensbereich hinzu:
p <- p +
geom_ribbon(data = res,
aes(x = Year,
ymin = Date.LCL,
ymax = Date.UCL))
# Nun kommt noch der gleitende Mittelwert:
p <- p +
geom_line(data = res,
aes(x = Year,
y = Date)) +
theme_minimal()
print(p)
Mit einigen „Verschönerungen“ (siehe unten) erhalte ich das folgende Ergebnis. Da ich diese Graphik am Dienstag nach Ostern in einer Schulung für Analystinnen und Analysten verwenden werde, siehst Du mir die englische Beschriftung hoffentlich nach:
Auf der horizontalen Achse ist das jeweilige Jahr aufgetragen und auf der vertikalen Achse das Datum der ersten Kirschblüte. Jeder Punkt entspricht einem Kirschblütenfest – seit mehr als 1200 Jahren… Deutlich erkennbar ist der Trend zu immer früherer Kirschblüte seit dem Jahr 1845.
Nun bin ich zugegebenermaßen nicht der Erste, der diese Daten aufbereitet. Der Economist hat das im Jahr 2017 in seinem – in der Regel sehr lesenswerten – „Graphical Detail“ schon getan. Dort wird auch das Offensichtliche diskutiert:
Die Kirschblüte ist ein „Klimaindikator“.
Wenn es wärmer wird, dann blühen die Kirschen früher. Und seit Mitte des 19. Jahrhunderts sind weltweit die Temperaturen angestiegen.
Mir liegt hier an folgenden zwei Aspekten:
Mit dem Panamakanal, jetzt der Kirschblüte und auch inspiriert von einem Blog meines ESSC-Kollegen Daniel Fügner zur Entwicklung des Wasserstands der Nidder denke ich, dass ich noch einige weitere „Klimaindikatoren“ aufspüren und untersuchen möchte. Damit meine ich frei verfügbare Messreihen, gerne über Jahrzehnte oder wie hier sogar Jahrtausende hinweg, die direkt oder indirekt Aufschluss über Klimaveränderungen geben können. Wenn Du Ideen oder Quellen hast: gerne!
Beruflich bin ich immer wieder mit „kritischen“ Daten konfrontiert – und sehe, wie wenig achtsam, durchaus im modernen Sinne des Wortes, diese aufbereitet und dargestellt werden. Wenn wir mit Daten Botschaften vermitteln, vielleicht sogar Handlung inspirieren wollen, dann müssen wir diese Daten auch aufbereiten und die Botschaft auf ansprechende Weise klar herausarbeiten. Deshalb möchte ich hier auch den Code bereitstellen. Denn es liegt mir daran, diese Fähigkeiten zu „demokratisieren“.
Der vollständige Quellcode der Graphik
Ganz im Sinne des zweiten Punktes: Gerne kannst Du diese Graphik bei Dir zuhause selbst erstellen und verändern. Dieses Wissen lässt sich übrigens nur deshalb so leicht teilen, weil es hier als Skript verfügbar ist. Wenn Du diese Fähigkeit hast: versuche einmal, jemand anderem zu erklären, wie er oder sie so eine Graphik in Excel erzeugen kann…
Ich hoffe, ich darf in diesem nüchtern gehaltenen Blog die Botschaft heute einmal dramatisieren: Ich bin Hobbyastronom. Gestern habe ich durch’s Fernrohr geschaut. Und einen Kometen gesehen, der auf die Erde zurast…
Es geht natürlich nicht um einen Kometen, sondern um den Panamakanal.
Meine Schlussfolgerungen basieren auf Szenarien, für die ich historische Daten heranziehe: ich verwende die Entwicklungen der vergangenen Jahrzehnte, um den derzeitigen (noch nicht kritischen, aber außergewöhnlich niedrigen) Wasserstand des Panamakanals in die Zukunft zu extrapolieren. Denn bis zum Ende des Jahres, also jetzt, muss der Gatúnsee gut gefüllt sein, damit der Panamakanal im nun folgenden Jahr sicher betrieben werden kann.
Die unten entwickelten Szenarien zeigen, dass wir im nächsten Jahr mit einer längeren Periode geringer Kapazität im Panamakanal rechnen müssen – und deshalb mit erheblichen Beeinträchtigungen weltweiter Lieferketten.
Bei der Supply Chain & Logistics Konferenz Anfang Dezember in Berlin kam über einem Kaffee das Thema auf, dass nicht nur der Suezkanal und die Straße von Hormuz für unvorhergesehene Störungen globaler Lieferketten sorgen können, sondern zunehmend auch der Panamakanal.
Der Panamakanal ist ein entscheidendes Element in der weltweiten Lieferketteninfrastruktur. Er dient als maritime Abkürzung, die einen effizienten und kostengünstigen Transport von Gütern zwischen Atlantik und Pazifik ermöglicht. Im Vergleich zur Umrundung von Kap Hoorn, und erst recht im Vergleich zum Weg durch die Nordwest-Passage, werden Reisedistanzen und -gefahren für Schiffe dank dieses Kanals erheblich verkürzt.
Schon dieses Jahr hat es an ungewöhnlich vielen Tagen im Panamakanal „bedenklich niedrige Wasserstände“ gegeben. Das führte jeweils dazu, dass große Schiffe („Panamax„) nicht mehr vollbeladen durch den Kanal fahren konnten. Auch sinkt die Kapazität des Kanals bei Niedrigstand, da dann zu wenig Wasser für einen häufigeren Schleusenbetrieb zur Verfügung steht.
Diese Dinge wollen wir uns heute genauer anschauen. Eine kurze Internetrecherche zeigt, dass es für den Betrieb des Kanals auf den Wasserstand des künstlich aufgestauten Gatúnsees ankommt. Bei einem Wasserstand von weniger als 79 Fuß wird es kritisch. Historische Daten dafür – leider aber nicht für die abgefertigte Tonnage oder die Anzahl der geschleusten Schiffe – werden dankenswerterweise von den Kanalbehörden bereitgestellt.
Datenbeschaffung und -aufbereitung
Wie sonst auch verwende ich ein R-Skript, was nicht zuletzt den Vorteil hat, dass ich meine Analyse bequem aktuell halten und in eine App einbauen kann: bei diesem Link auf den Reiter „Panama Canal“ klicken, um den aktuellen Stand im Jahr 2024 im Vergleich zu vorhergehenden Jahren zu sehen.
Die Daten enthalten zwei Spalten: das Datum und den Wasserstand in Fuß. Ich filtere einige Zeilen heraus, in denen ein unrealistischer Wasserstand von Null vermerkt ist, und erkenne, dass es für das Jahr 2002 lediglich zwei Einträge gibt. Sehr viel später fällt mir zudem auf, dass ausgerechnet zwischen den Jahren einige Werte „Ausreißer“ darstellen – vermutlich keine „echten“ Schwankungen des Wasserstandes, sondern Probleme in der Datenerfassung oder -übertragung.
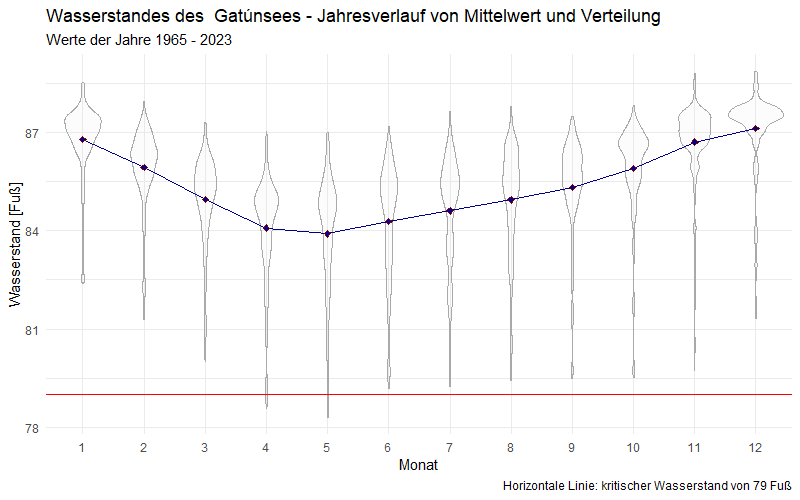
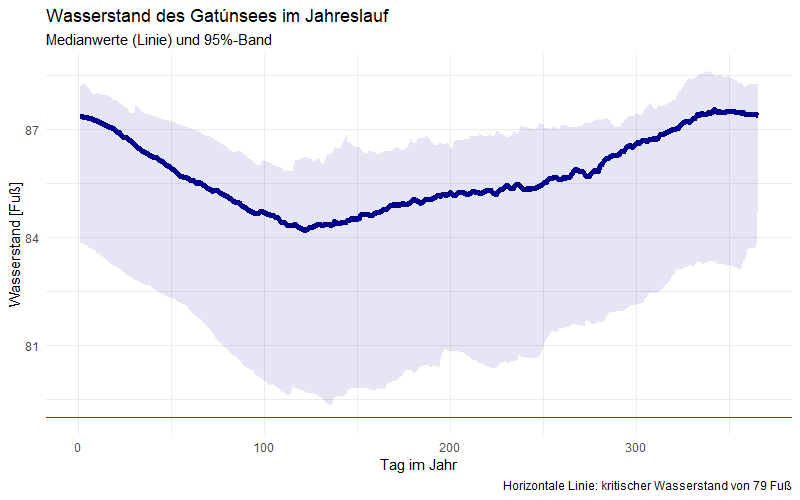
Für die weitere Handhabung berechne ich aus der Datumsspalte weitere Spalten für das Jahr (1965 bis 2023), den Monat (1, 2, … 12) und den Tag des jeweiligen Jahres (1, 2, … 365). Da im Jahresverlauf Schwankungen auftreten (siehe unten), berechne ich für jeden Monat und für jeden Tag im Jahr einen Mittelwert. Puristen mögen einwenden, dass ich besser den Median verwenden sollte, denn die Daten sind nicht normalverteilt, wie auch die folgende Graphik schon zeigt:
Verlauf des Wasserstandes über das Jahr und über alle Jahre hinweg
Wie die vorherige Graphik zeigt, sind die mittleren Wasserstände in den Monaten April bis August am niedrigsten. Kritische Niedrigstände wurden bisher lediglich im April und Mai erreicht. Die Wasserstände streuen zudem stark – mit Ausreißern nach unten. Auf Tagesbasis stellt sich die Situation wie folgt dar:
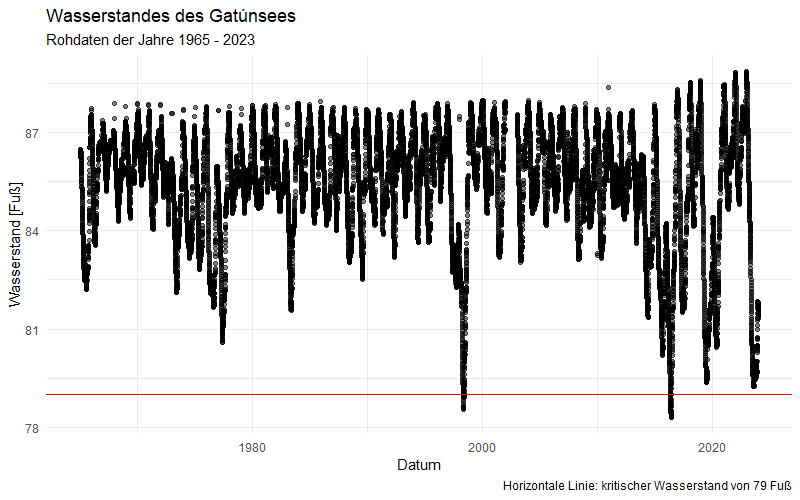
Wir schauen uns den zeitlichen Verlauf über alle Jahre hinweg genauer an:
So erkennen wir, dass die jahreszeitlichen Schwankungen Mitte der 1970er Jahr mehrere Jahre nacheinander besonders stark nach unten ausgeschlagen haben. Im April 1998 gab es die ersten 12 Tage mit einem kritischen Wasserstand von weniger als 79 Fuß und zwei weitere Tage im Mai. Im Jahr 2016 traten 41 solcher Tage auf. Überhaupt scheinen sich niedrige Wasserstände in den letzten Jahren gehäuft zu haben – erkennbar an den häufiger gewordenen Ausreißern nach unten. Auch die Varianz des Wasserstandes (optisch der Abstand von Höchst- zu Tiefstwerten innerhalb eines Zeitraumes) scheint seit ca. 2015 deutlich angestiegen zu sein.
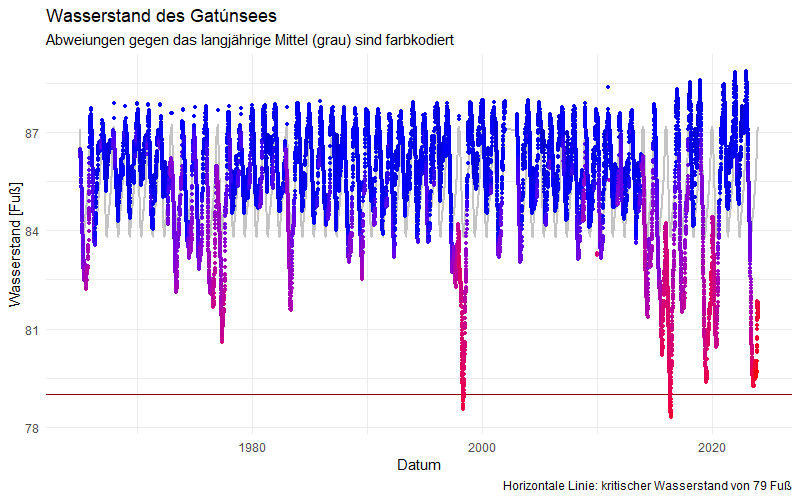
Ich habe längere Zeit herumprobiert und bin immer noch nicht so ganz schlüssig, denke aber, dass die folgende Graphik die Dramatik der Entwicklung ganz gut wiedergibt:
Hier stelle ich den vorher schon gezeigten Verlauf dar, allerdings nun den Ausschnitt seit den 1990er Jahren. Zusätzlich färbe die Punkte umso röter ein, je weiter der Wasserstand von seinem langjährigen Tagesmittel abweicht. Diese Mittelwerte – berechnet auf Grundlage aller Daten – zeige ich im Hintergrund grau. So werden die starken Abweichungen des Wasserstandes nach unten während der letzten Jahre deutlich sichtbar.
Auch jetzt, gegen Ende des Jahres 2023 (hellrot, ganz rechts in der Graphik), zu Zeiten seines Höchststandes, hat der See einen historischen Tiefstand für die Jahreszeit erreicht – deutlich unter den Tiefstständen sogar, die sonst in den Monaten April bis Juni erreicht werden.
Auf Grundlage der historischen Entwicklung erwarten wir also, dass es nun von den aktuell erreichten 81,6 Fuß wieder „bergab“ (!) geht. Somit besteht die Erwartung und Befürchtung, dass die Marke von 79 Fuß bald erreicht sein könnte.
Wie geht es weiter?
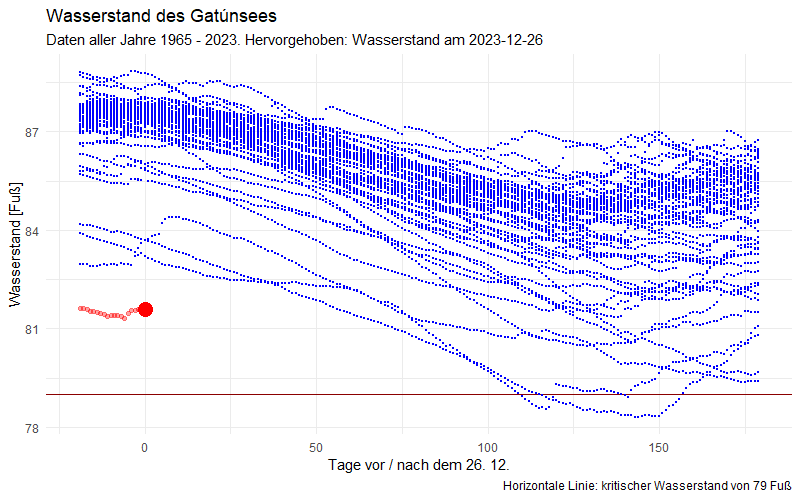
Um das genauer zu betrachten, schauen wir uns die Jahresverläufe an:
Der diesjährige Verlauf (rot) liegt weit außerhalb der zu dieser Jahreszeit jemals aufgetretenen Wasserstände.
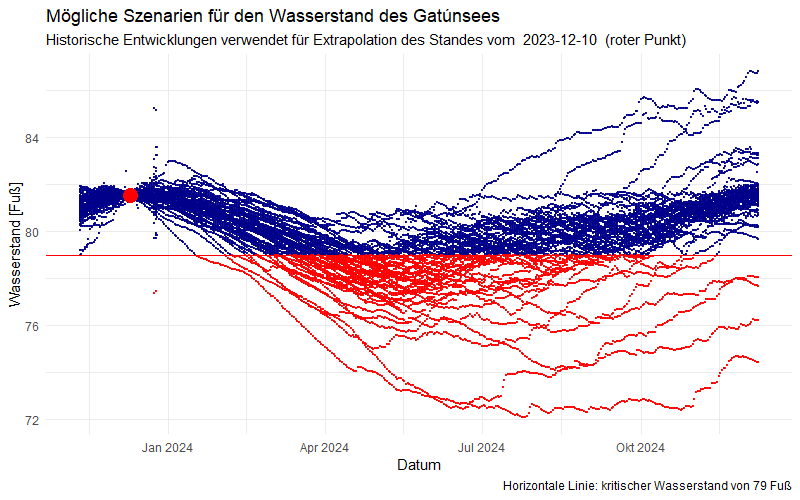
Nun ist die spannende Frage, wie es wohl weitergehen könnte. Dafür stelle ich folgende Überlegung an: Ich verschiebe alle Verläufe der vergangenen Jahre auf den Startpunkt in diesem Jahr und schaue, wohin das führt. Dabei gab es noch eine Schwierigkeit: zwischen den Jahren zeigen die Wasserstände für einige Jahre (1997, 2015, 2019, 1982, 2008, 2013, 1971, 1998, 2016, 2020, 1983, 1977, 2014) einen erstaunlichen Sprung. Ein Messfehler? Ich verschiebe deshalb die Normalisierung auf einen früheren Termin, den 10. Dezember 2023 (der rote Punkt in der folgenden Graphik) und lasse die vergangenen Entwicklungen durch eine Verschiebung des Wasserniveaus dort starten:
Wir erkennen wir die ganze Dramatik dessen, was für 2024 droht: wenn sich der Wasserstand entwickelt wie in der Vergangenheit – und jede der gezeigten Kurven ist eine aus der Vergangenheit – dann führen manche Szenarien zu einem dramatischen und nie dagewesenen Niedrigwasser im Panamakanal – von dem sich dieser auch im gesamten nun folgenden Jahr nicht erholen würde.
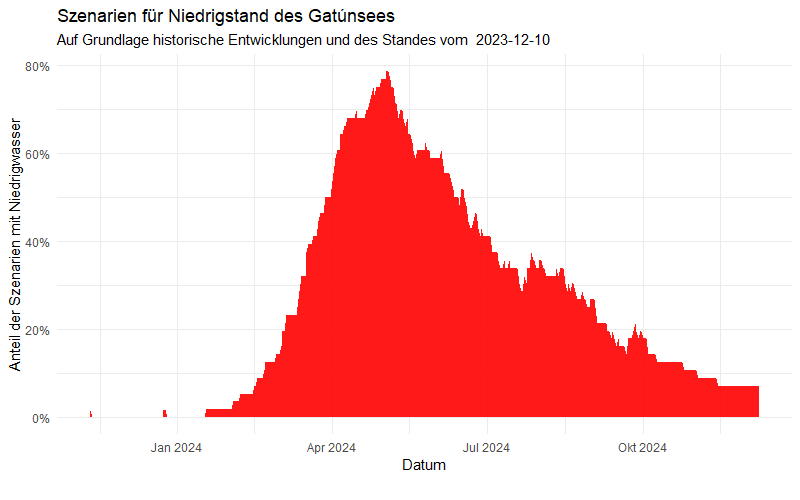
Diese Szenarien lassen auch eine Wahrscheinlichkeitsbetrachtung zu: wir bestimmen dafür Tag für Tag den Anteil der Szenarien mit Niedrigwasser, also einem Stand von weniger als 79 Fuß. Das Ergebnis ist beunruhigend:
Spätestens ab dem März 2024 steigt die Wahrscheinlichkeit für Niedrigstand rasant an und erreicht Anfang Mai fast die 80-Prozent-Marke. Bis Ende Oktober liegt die Wahrscheinlichkeit für Niedrigwasser noch bei 10%: kein beruhigender Ausblick für das nun kommende Jahr!
Sind wir vorbereitet?
Dies ist „nur“ ein Blog, in dem ich öffentlich verfügbare Daten verwende und interpretiere. Ich glaube, dass das wichtig ist. Hier aber stellt sich die Frage: wie bewusst ist Stakeholdern und Entscheidern die Situation? Werden ausreichend Maßnahmen eingeleitet für dieses „Tagebuch einer angekündigten Krise“? Oder müssen wir uns für 2024 auf Engpässe in den weltweiten Lieferketten einstellen?
Anmerkung: auf Grundlage von Rückmeldungen habe ich diesen Artikel stark überarbeitet und in englischer Sprache auch auf LinkedIn veröffentlicht.
Wir machen uns Sorgen darum, wie wir in Zukunft hochwertige Arbeitsplätze in Deutschland halten können. Angesichts von steigenden Energiekosten, Lieferkettenproblemen, der demographischen Entwicklung und dem damit einhergehendem Fach- und Führungskräftemangel ist ein Thema etwas ins Hintertreffen geraten: unsere „Erfolgsrezepte“. Intellektuelles Eigentum ist ein wesentlicher Baustein für die Zukunft.
In diesem Beitrag betrachte ich vor allem das Thema „Patente“, und das im internationalen Vergleich. Der Vorteil liegt vor allem darin, dass Daten frei verfügbar sind. Wusstest Du das? Nutzt Du diese? Auch wenn es sich bei Patenten um die „sichtbare Spitze eines Eisberges“ handelt, können wir aus Patentdaten interessante Einsichten und einige Handlungsempfehlungen ableiten.
Intellektuelles Eigentum als Erfolgsfaktor für die Zukunft
In einem vorherigen Beitrag habe ich beschrieben, wie Du Daten zu weltweit veröffentlichten Patenten beschaffen und visualisieren kannst. Wir hatten auch gesehen, dass in Asien ein immer größerer Anteil des weltweiten intellektuellen Eigentums erzeugt wird.
Verpassen wir hier den Anschluss?
Heute wollen wir zunächst fragen, welche Länder die meisten Patente pro Kopf der Bevölkerung veröffentlichen. Das ist ein Blickwinkel, den ich aus den Gesprächen der letzten Wochen mitgenommen habe.
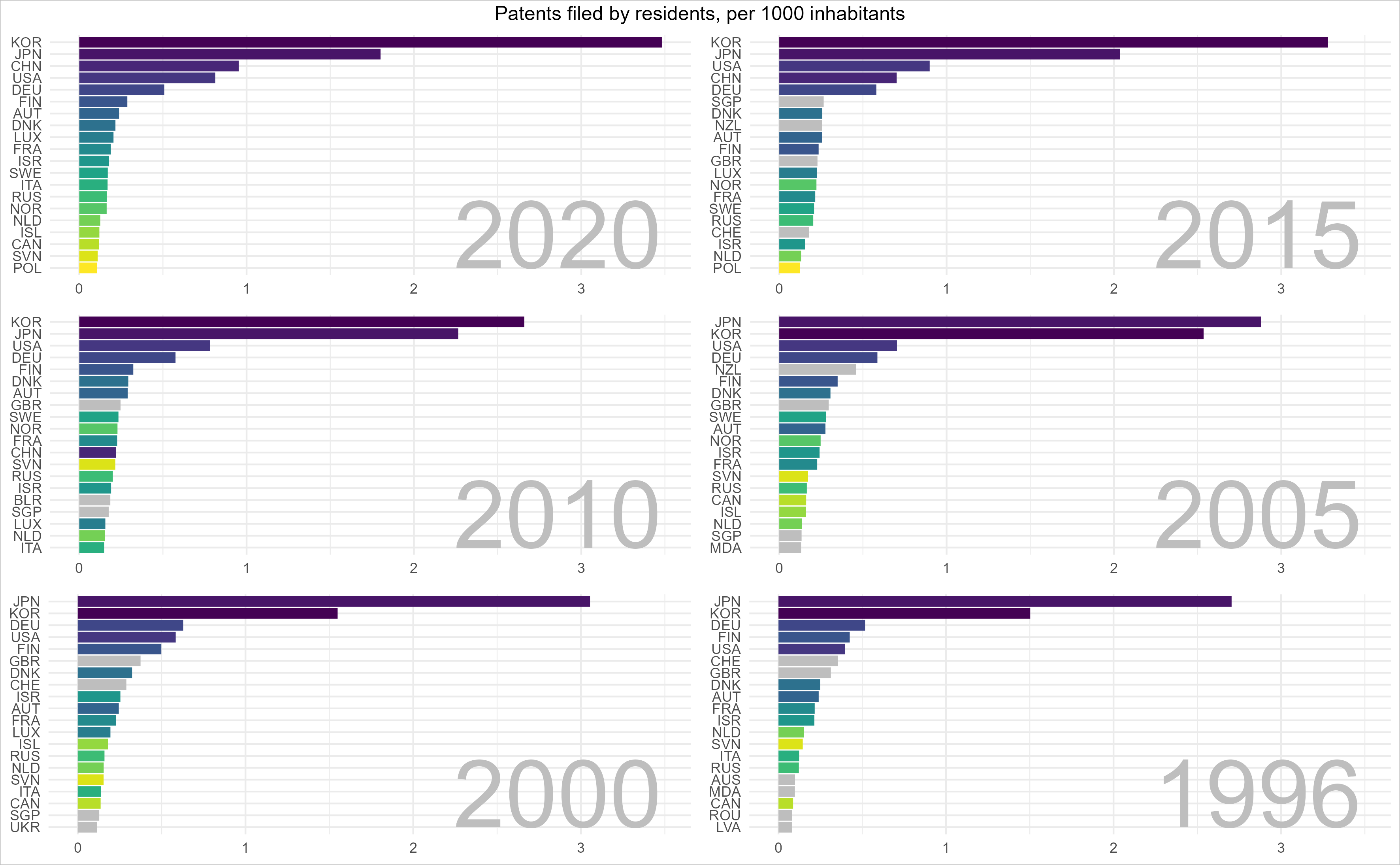
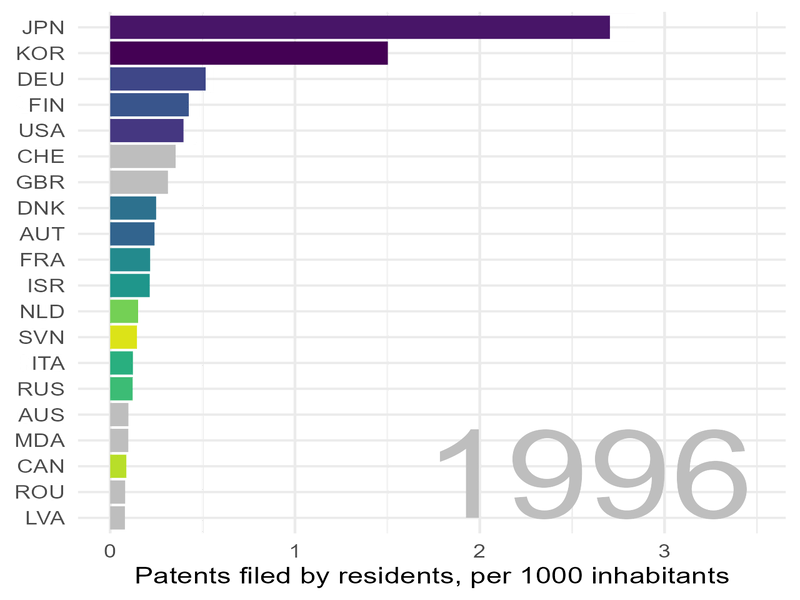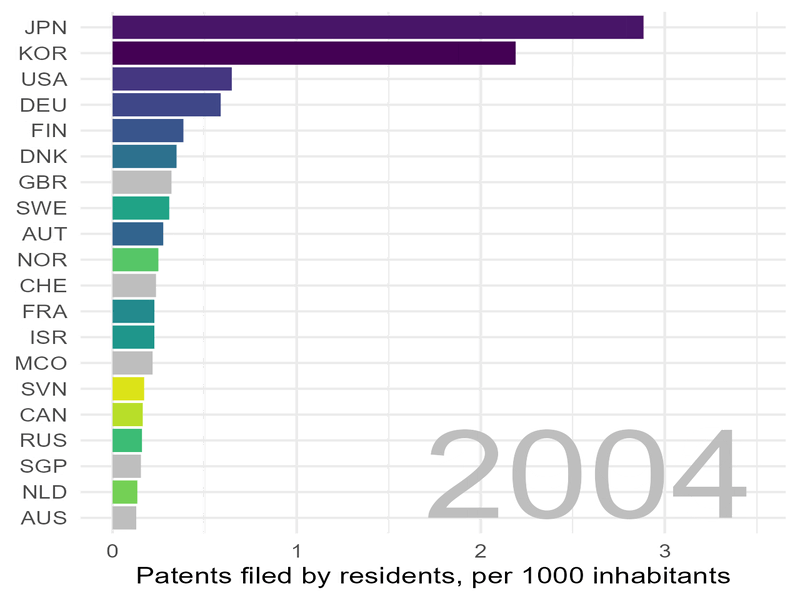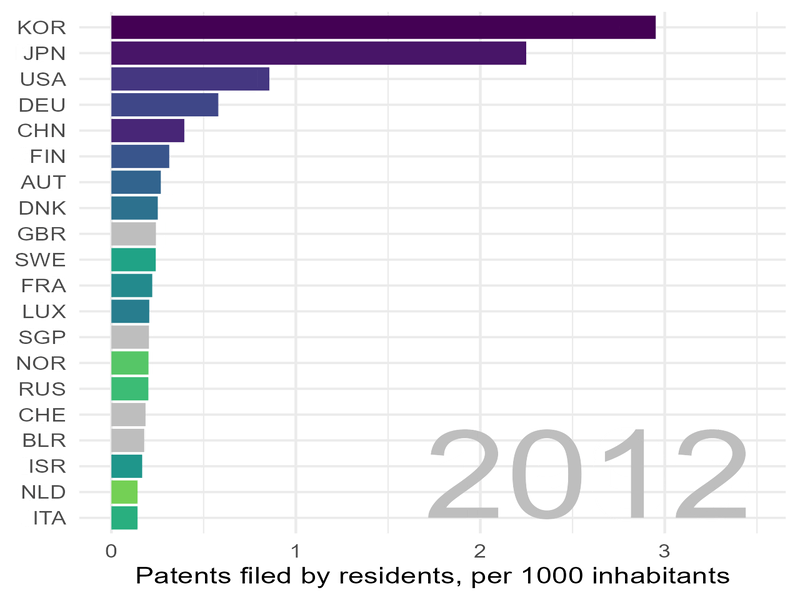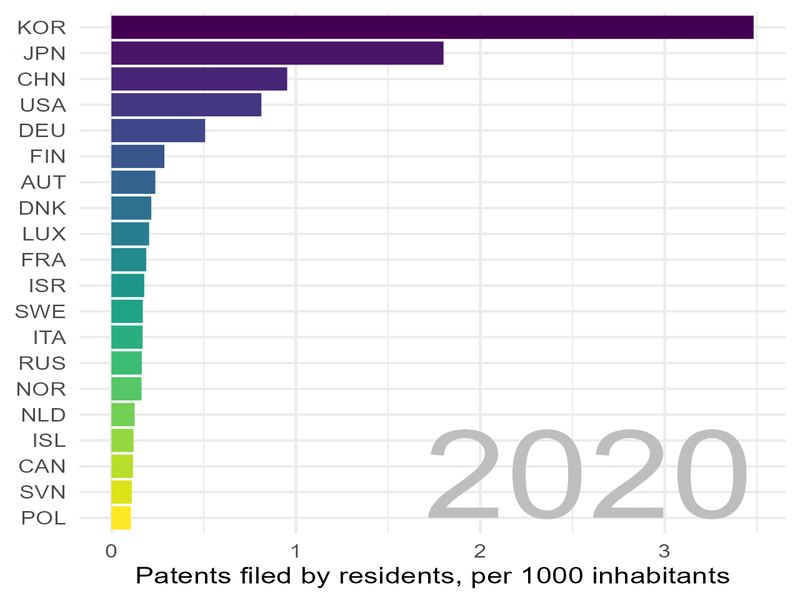
Wir schauen uns die Lage zunächst „statisch“ an und wählen dafür einige Jahre aus:
Deutschland steht im Jahr 2020 immerhin auf Platz 4, allerdings mit ca. sieben mal weniger Patenten pro Kopf der Bevölkerung als Korea.
In Sachen Patenten zieht Korea „mit Siebenmeilenstiefel“ an uns vorbei.
Auch China legt in den 2010er Jahren eine beeindruckende Aufholjagd hin, erkennbar im folgenden „Film“. Du könntest einwerfen, deutsche Patente seien besser. Sicher?
Die schleichende Gefahr für Unternehmertum: ungenügende Absicherung des intellektuellen Eigentums
So kommen wir in meinen Gesprächen auf einen weiteren Einwand:
Beim Geschäftserfolg geht es nicht nur um Patente.
Das stimmt. Gehe aber bei nächster Gelegenheit einmal über eine Industriemesse und wähle einen Stand aus, um zu fragen: Wie in aller Welt dieser kleine Biegeradius in hoher Stückzahl fehlersicher hergestellt werden kann? Welche Toleranzen dafür gebraucht werden? Und welche Anforderungen an die umgebende Spritzgussmasse gestellt werden müssen? Man wird Dich nur mit der Kneifzange anfassen…
Am Frankfurter Flughafen, Terminal 1, unten bei den Autovermietungen, habe ich ca. im Jahr 2013 in der McDonalds Küche einmal einen riesengroßen Salzstreuer für Pommes gesehen – ganz offensichtlich clever abgeguckt von der Mutter Natur und der Mohnblume. Ich habe mich mit einer Telekamera auf die Lauer gelegt und ein Foto für meine Innovationstrainings gemacht – und musste kurz darauf das Bild unter Aufsicht einer hinzugerufenen Sicherheitsfachkraft wieder löschen…
Nicht alles wird patentiert. Das Patent auf den Salzstreuer habe ich damals nicht gefunden. Das für Coca Cola wäre längst abgelaufen, wenn sie ihr Rezept patentiert hätten. Open AI legt seine Algorithmen auch nicht im Schaufenster aus und Coco Chanel meldet ebenfalls keine Patente auf Düfte an. Viele Fertigungsprozesse in der Automobil-, chemischen, Lebensmittel- und Pharmaindustrie unterliegen „einfach nur“ der Geheimhaltung. So wie auch die Designmethoden bei Inditex und anderen Modehäusern.
Patente stellen die sichtbare „Spitze eines Eisberges“ dar.
Und weil sie sichtbar sind, lassen sie sich gut einsetzen. Du kannst sie verkaufen, lizensieren. Du hast für 20 Jahre ein Monopol auf Deine tolle Idee. Selbst wenn Deine Firma pleite geht, können ihre Patente immer noch viel wert sein. Ein Land, in dem viele Patente angemeldet werden, zieht internationale Unternehmen an, kann das eigene „intellektuelle Eigentum“ einsetzen, um neues zu produzieren, stellt seine Schaffenskraft unter Beweis.
Patente als „Wegweiser“ in die Zukunft
Gespräche und Recherchen der letzten Wochen fördern – auch im Vergleich mit Korea – einige Erfolgsfaktoren zutage, die Deutschland mittel- und langfristig helfen können:
Investitionen in Forschung und Entwicklung: Südkorea hat ganz offensichtlich in den letzten Jahrzehnten erhebliche Investitionen in Forschung und Entwicklung getätigt. Dies schließt öffentliche und private Investitionen in Forschungseinrichtungen, Universitäten und Unternehmen ein. Ziel dieser Investitionen war und ist es, das technologische Know-how des Landes zu stärken und Innovationen zu fördern.
Bildungssystem: Das koreanische Bildungssystem scheint einen Schwerpunkt auf Wissenschaft und Technik zu legen. So „produziert“ es hochqualifizierte Absolventen in den Bereichen Ingenieurwissenschaften, Informatik und anderen technischen Disziplinen, die in der Lage sind, innovative Technologien zu entwickeln und zu patentieren. In einem zukünftigen Blogbeitrag könnten wir uns einmal PISA-Studien und speziell die MINT-Fächer anschauen.
Regierungsprogramme und -initiativen: Die koreanische Regierung hat verschiedene Programme und Initiativen zur Förderung von Forschung und Innovation ins Leben gerufen. Das tut auch Deutschland und jedes OECD-Land: finanzielle Unterstützung, Steuervergünstigungen, Anreize für Unternehmen und Forschungseinrichtungen. Vielleicht können wir uns dennoch das eine oder andere aus Korea abgucken?
Kulturelle Faktoren: Hier tue ich mich am schwersten. Aber es heißt, die koreanische Kultur fördere harte Arbeit, Wettbewerb, Ehrgeiz und den Drang nach Exzellenz. Zumindest einige sagen, dass auch dies dazu beitrage, dass viele Menschen in Korea motiviert seien, in technologischen Bereichen erfolgreich zu sein – und so eben auch Patente schreiben und veröffentlichen.
Soviel zu dem, was „die Regierung“ tun könnte. Auch Dein Unternehmen kann eigene Schwerpunkte setzen, zum Beispiel:
Systematische Innovationskultur: In den 2015er Jahren habe ich mit amerikanischen Kollegen Entwicklungen auf LinkedIn verfolgt. Wir haben gesehen, wie einige (v.a. russische) TRIZ-Experten (Theorie der erfinderischen Problemlösung) zu Samsung gewechselt sind und in der Folge deren Patentportfolios erweitert haben. TRIZ-Konferenzen waren und sind koreanische Vertreter jedenfalls sehr kompetent vertreten. Dank KI erwarten viele ein Wiederaufblühen von Methoden wie TRIZ, auch in Verbindung mit Design Thinking und „Outcome-Driven Innovation“. Wie geht Ihr hier vor?
Innovations-Portfolio-Management: Habt Ihr einen systematischen Innovationsprozess, vom Markt her gesteuert, der ständig Entwicklungen beobachtet, Chancen daraus ableitet, diese in Prototypen verwandelt, Prototypen in Produkte übersetzt und im Markt testet? Ein Prozess, bei dem aktiv geprüft wird, welche Patente abgeleitet werden können und welche gebraucht werden (z.B. für „Patent Fencing“)?
Wettbewerberanalyse: Beobachtet Ihr Patentveröffentlichungen von Wettbewerbern? Könntest Du mir für Deinen Bereich die fünf Wettbewerberpatente nennen, die Euch am meisten im Weg stehen? Analysiert Ihr systematisch, wie diese Patente aufgebaut sind, wo sie ihre Schwachstellen haben und gegebenenfalls umgangen werden können? Beobachtet Ihr, wer Eure Patente verletzt? Betreibt Ihr dafür „Reverse Engineering“ von Wettbewerberprodukten – vielleicht auch, um zu erkennen, wo sie, trickreich und völlig legal, Eure Patente umgehen konnten? Wie setzt Ihr im Fall der Fälle Eure Rechte durch? Gibt es Zahlen dazu, welche Produkte, Märkte, Wettbewerber besonders „anfällig“ sind und Eurer besonderen Beobachtung bedürfen?
Geheimhaltungsvereinbarungen und Vertraulichkeitsvereinbarungen: Wie nutzt Ihr bei der Zusammenarbeit mit Partnern, Lieferanten, Forschungseinrichtungen und auch Mitarbeitern Geheimhaltungsvereinbarungen, um sicherzustellen, dass vertrauliche Informationen geschützt bleiben? Wie schult Ihr Mitarbeiter zu diesen Themen? Im Bereich der Arbeitssicherheit gibt es meldepflichtige Vorfälle und Beinaheunfälle. Gibt es solche Zahlen und die dahinter liegenden Prozesse und Verantwortlichkeiten auch zu Geheimhaltungsthemen?
Datenschutz und IT-Sicherheit: Memorysticks sind schon lange abgeschaltet – auch bei Euch, richtig? Die zunehmende Digitalisierung stellt aber gerade bei den Themen intellektuelles Eigentum und Geschäftsgeheimnisse neue Herausforderungen. Können Eure Mitarbeiter ChatGPT nutzen? Nein? – Schade! – Oh, doch, das tun sie? Wie sorgt Ihr dann dafür, dass hier nicht ein gewaltiges Datenleck entsteht? Und das ist nur ein Beispiel unter vielen…
Zusammenarbeit mit Forschungseinrichtungen, Universitäten und anderen Einrichtungen: Welche Themen bearbeitet Ihr selbst? Für welche braucht und habt Ihr Kooperationen? Wie trefft Ihr klare Vereinbarungen über Nutzung und Schutz von Ergebnissen? Gibt es zu diesem Vorgehen ein „Strategiepapier“ und Entscheidungsgrundlagen?
Technologietransfer und Lizenzierung: Wie setzt Ihr Euer eigenes Patentportfolio nutzbringend ein? Welche Lizenzen gebt Ihr heraus – welche nehmt Ihr? Wer hat ein Auge darauf, dass so ein möglichst großer Nutzen erzeugt wird (und wie groß war dieser Nutzen im letzten Jahr)?
Diese Liste ist das Ergebnis aus Gesprächen der letzten Wochen. In der Regel gibt es zu jedem Thema „etwas“: „Natürlich haben wir etwas“ oder – „Ja, die F&Eler machen da was mit der Uni Stuttgart“. Es scheint jedoch an einem durchgestochenem Vorgehen zu fehlen, das sich abteilungs- und begreifsübergreifend aus unternehmerischen Zielen ableitet und entsprechend nachgehalten wird. Die gute Botschaft ist jedoch: Dein Unternehmen hat viele Hebel selbst in der Hand. Ihr könnt morgen anfangen.
Was macht die Regierung?
Diesen Ruf kenne ich aus Frankreich: „Que fait le gouvernement!?“ – um die Preissteigerung, die Arbeitslosenzahlen, die Lieferkettenengpässe – und überhaupt jedes größere Problem in den Griff zu kriegen. Franzosen nehmen sich mit dieser Frage gern selbst auf die Schippe.
Auch uns sind diese Fragen und die daraus entstandenen Programme der Industriepolitik durchaus vertraut: z.B. Rürupp/Riester-Sparen, Abwrackprämie, Coronahilfen, Industriestrompreis.
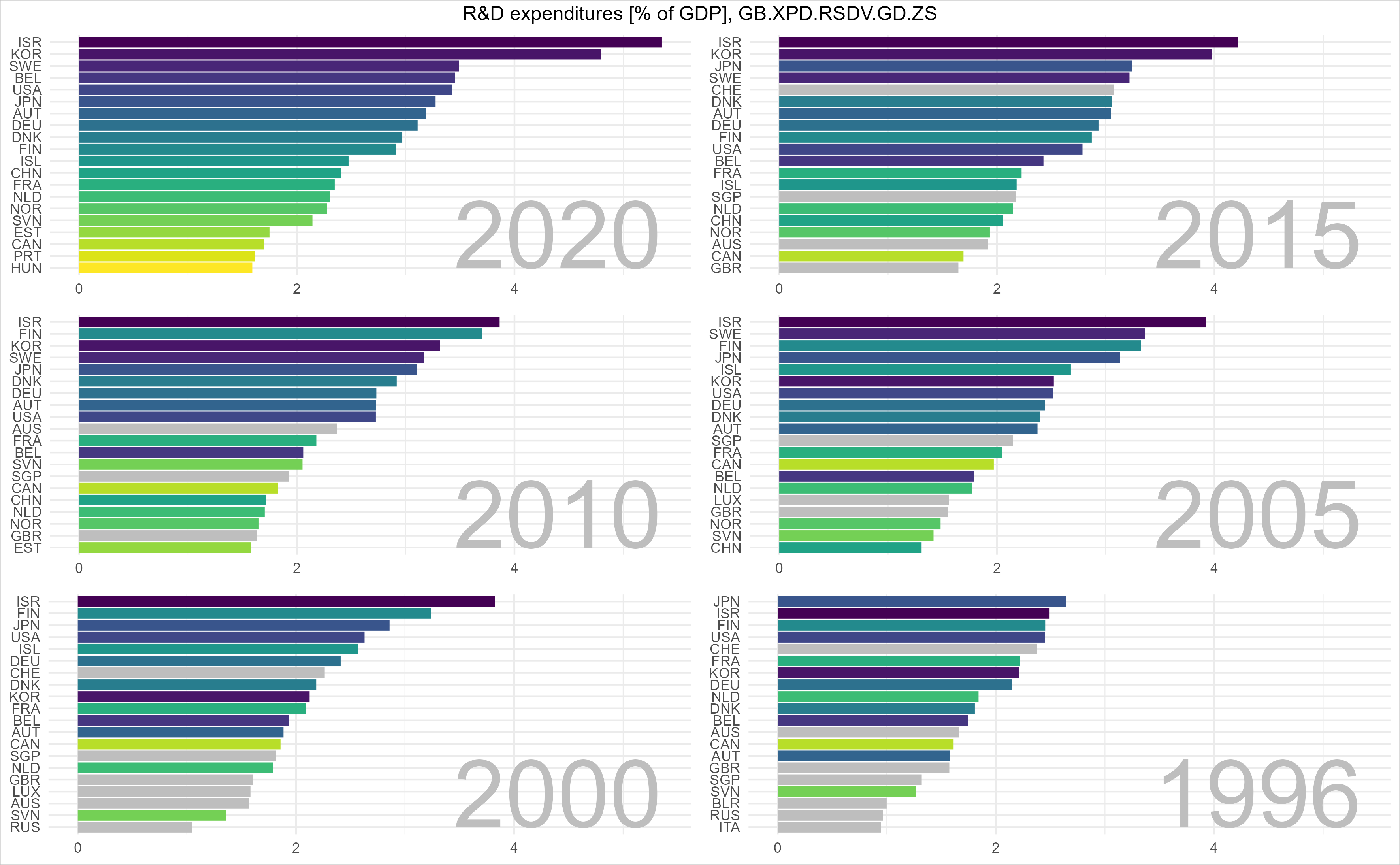
Wir wollen uns also auch anschauen, welchen Anteil ihres Bruttosozialprodukts Länder in Forschung und Entwicklung stecken. Die Weltbank trägt dazu Daten zusammen (GB.XPD.RSDV.GD.ZS), die wir uns mit den oben erstellten Algorithmen bequem anschauen können, und zwar zunächst als „Film“ …
… und dann als statische Graphik für ausgewählte Jahre:
Deutschland (DEU) spielt oben mit und hat im Jahr 1996 etwas über 2% des Bruttosozialprodukts für Forschung und Entwicklung eingesetzt. Bis zum Jahr 2000 ist diese Zahl auf immerhin 3% angestiegen. Das sind gewaltigen Summen: im Jahr 2022 hat Deutschland ein Bruttosozialprodukt von 3,88 Billionen Euro erwirtschaftet. Drei Prozent davon entsprechen 116 Milliarden Euro, immerhin 1400 Euro pro Kopf der Bevölkerung. Solche gewaltigen Summen dürfen nicht „mit der Gießkanne“ verteilt werden. Es müssen vielmehr klare Ziele definiert und abgestimmt, Programme aufgelegt und bewertet, es muss schlicht gute Arbeit geleistet werden.
Wir sehen auch:
Israel steht fast über den gesamten Zeitraum an der Spitze.
Auch Korea spielt ganz vorne mit und auch mit Schweden, Belgien, den USA, Japan und Österreich könnten wir uns vermutlich dazu austauschen, wie staatliche Ausgaben für Forschung und Entwicklung am besten gelenkt und eingesetzt werden können.
Vielleicht gibt es auch Möglichkeiten für Dein Unternehmen, sich mit anderen zusammenzusetzen, und darüber zu sprechen, was gut funktioniert, was besser gemacht werden kann und wie?
Es geht hier nicht um irgendeine Aufgabe. Es geht darum, das Unternehmen „wetterfest“ zu machen in Zeiten großer Umbrüche und dafür zu sorgen, dass es auch in Zukunft wettbewerbsfähig ist. Intellektuelles Eigentum spielt dabei eine entscheidende Rolle.
Nicht den Bach runter. Trotz allem. Das glaube ich nicht.
Langfristige Trends sind oft schwer zu erkennen. Sie entwickeln sich so gleichmäßig vor unseren Augen, dass wir sie nicht wahrnehmen. Es ist das klassische „boiling frog“ Problem: Wir merken erst dann, was vor sich geht, wenn es unübersehbar wird. Deshalb führt kein Weg an Daten vorbei. Sie weisen uns auf Veränderungen hin, die uns sonst entgehen. Die Daten müssen visualisiert werden. Und das ist nicht nur eine Aufgabe für Statistiker und Informatikerinnen.
Daten helfen Dir, Deine „Business Story“ zu erzählen.
„Business Story Telling“ ist übrigens ein großes Ding. Es gibt sogar ein Buch darüber (Lori Silverman, Business Story Telling for Dummies).
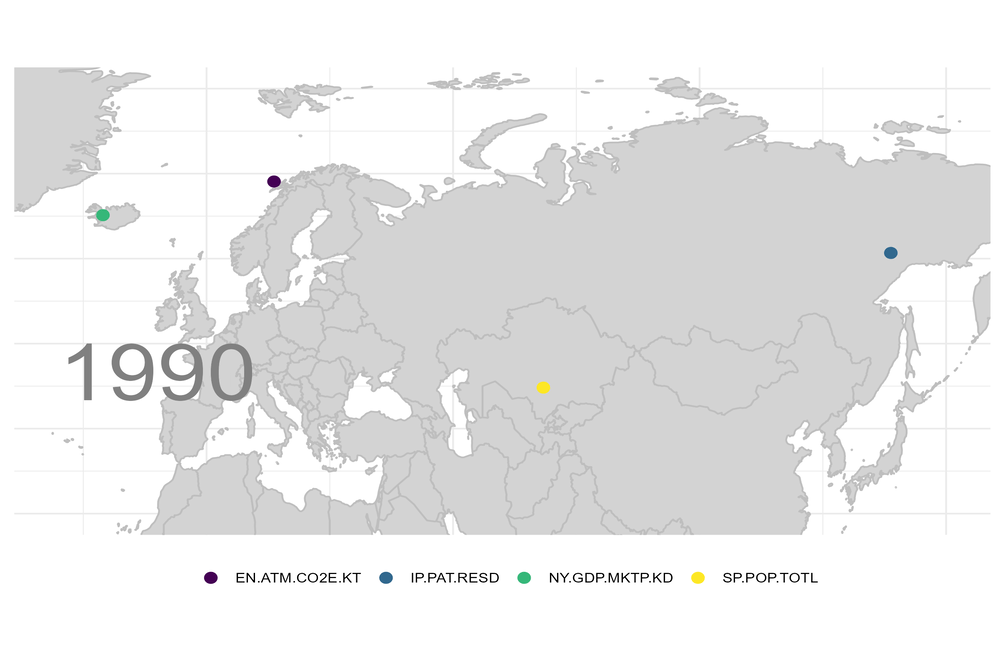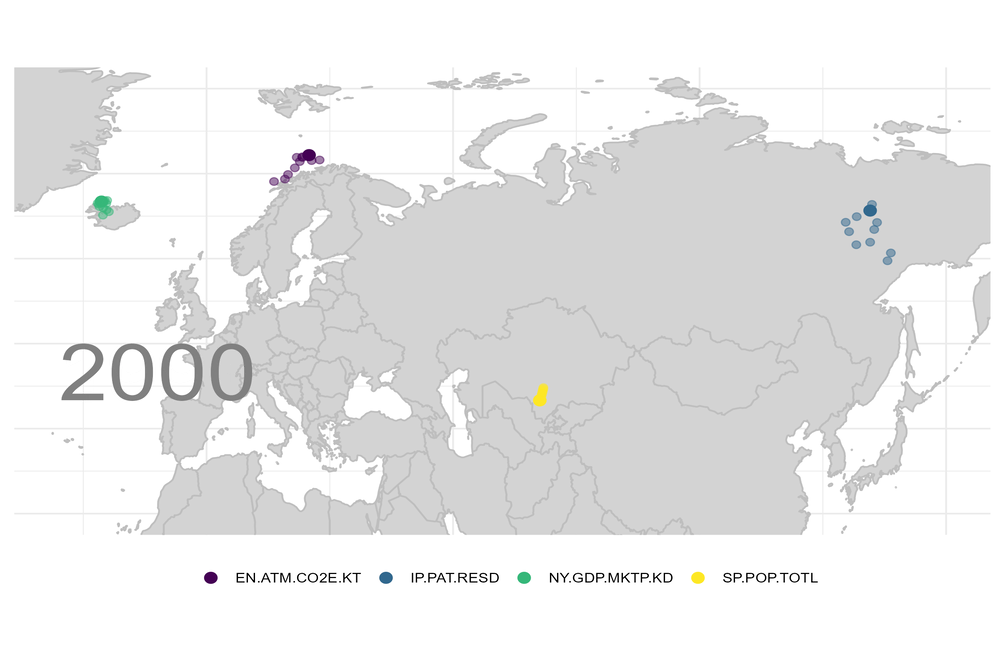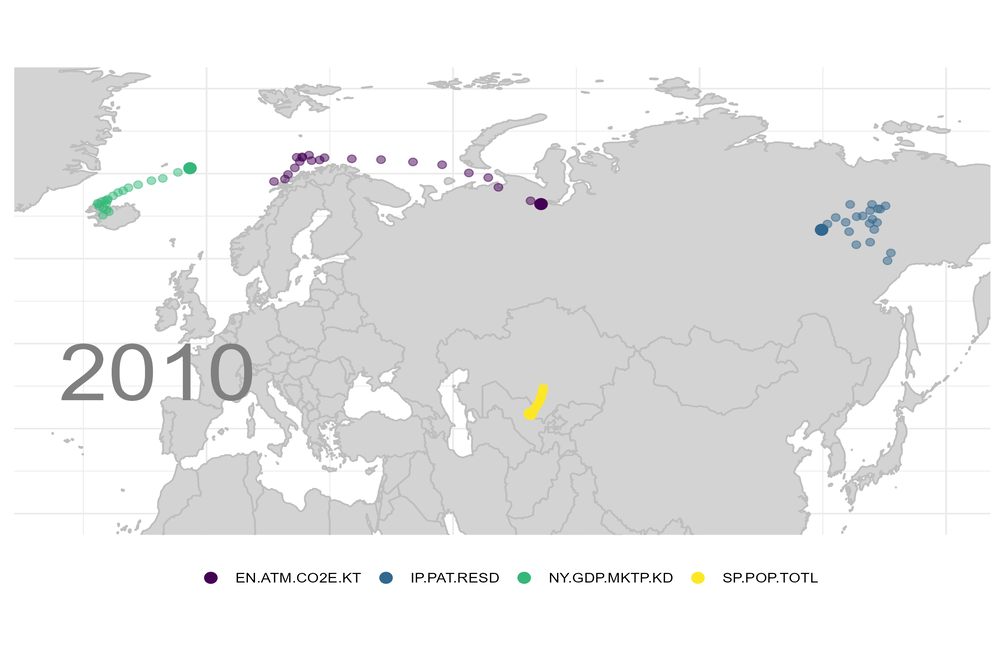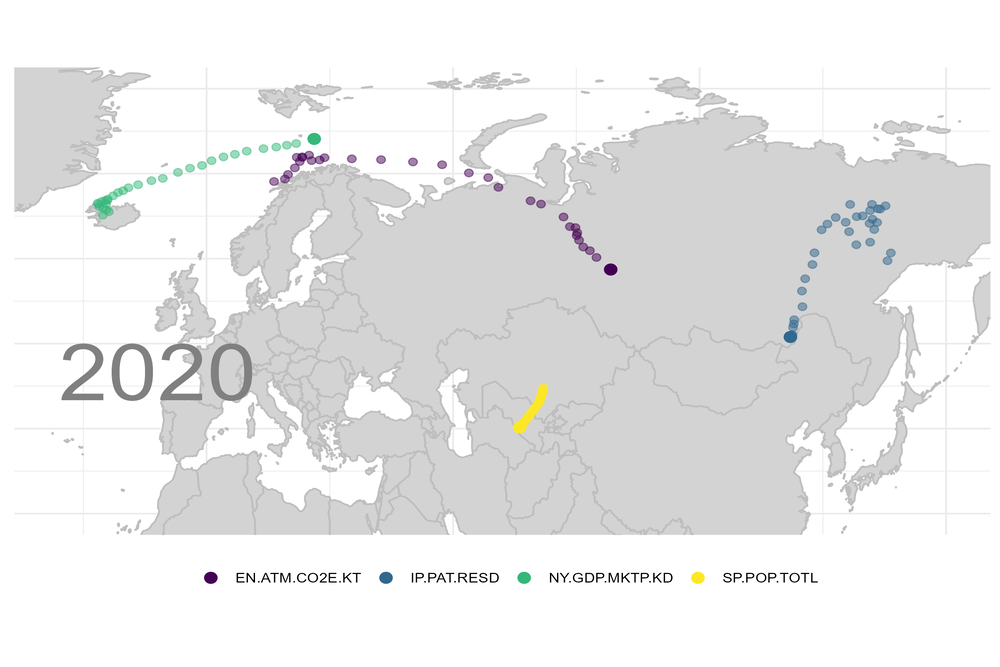
Vermutlich gibt es eine gute Handvoll Trends, denen zumindest die multinationalen Unternehmen ausgesetzt sind. Sagen wir einmal, Bevölkerung, Bruttoinlandsprodukt, Emissionen und geistiges Eigentum gehörten dazu.
Angenommen Du hättst nötigen Daten: wie würdest Du visualisieren, welche Richtung diese „Indikatoren“ einschlagen?
Für die heutige Grafik verwende ich Daten der Weltbank. Wie Du an diese Daten kommst, habe ich in vorherigen Blogs beschrieben. Für jedes Jahr habe ich dann die „Schwerpunkte“ für diese Indizes berechnet.
Berechne die xyz-Koordinaten jeder Hauptstadt auf dem Erdball und setze dort den Index des jeweiligen Landes hin. Offensichtlich liegt der Schwerpunkt dann irgendwo im Inneren des Planeten. Wenn Europa dominieren würde, dann wäre der Schwerpunkt nahe an der Oberfläche, irgendwo unter Europa. Diesen Schwerpunkt verfolge ich dann Jahr für Jahr bis zur Oberfläche des Planeten. Die Berechnung ist nicht besonders schwierig. Ich habe aber eine Weile gebraucht, um die Winkelfunktionen richtig hinzukriegen.
Das Ergebnis ist für mich überraschend und aufschlussreich zugleich. Der Schwerpunkt für das Bruttoinlandsprodukt, die angemeldeten Patente und die CO2-Emissionen gehen alle in Richtung Asien / China. Die Weltbevölkerung „marschiert“ nach Afrika:
Was bedeutet das für Dein Unternehmen?
Falls Dein Unternehmen eine internationale Ausrichtung hat, dann ergeben sich nahezu zwangsläufig aus diesen Entwicklungen sowohl Chancen als auch Risiken. Aber auch ein Weinbauer aus dem Elsass sollte vermutlich nicht die Augen verschließen. Denn angesichts dieser Trends wird Dein Unternehmen sowohl Stärken als auch Schwächen aufzeigen.
Vielleicht wusstest Du, vielleicht wusste vor allem Euer Vorstand das alles schon. Vielleicht werden diese Ergebnisse in Euer SWOT-Analyse bereits festgehalten. Vielleicht sind für Euch auch ganz andere Kennzahlen (Weltbank-Sprech: „Indizes“) interessant. Nun, dann hast Du hier eine neue Möglichkeit, diese darzustellen und die die Motivation der daraus abgeleiteten Maßnahmen zu kommunizieren.
Oder möchtest Du Eure eigenen Daten so darstellen? Sagen wir einmal: die weltweiten Verkaufszahlen Deines Unternehmens? Das könnte interessante Entwicklungen aufzeigen. Oder?
Bitte beachte: Mit dem folgenden Link verlässt Du meinen Blog, um die Plattform Youtube zu nutzen. Youtube hat eigene Datenschutzrichtlinien, die Du teilweise an Deine eigenen Bedürfnisse anpassen kannst. Es kann sein, dass Youtube Dir vor oder während der Nutzung meines Videos Werbung zeigt. Wenn Du Deine Rechte auf Youtube nicht kennst oder mit den Dir zugestandenen Rechten nicht einverstanden bist, dann solltest Du den folgenden Link nicht verwenden.
Wenn Du viel mit Datenanalyse zu tun hast, dann solltest Du coden. Dabei kannst Du Dich von KI unterstützen lassen.
Neulich habe ich ein Seminar beim Europäischen Six Sigma Club dazu gehalten, wie Du ChatGPT & Co bei der Datenanalyse einsetzen kannst. Und zwar:
Als klassische Suchmaschine: Du fragst, wie Du gewisse Analysen in Excel, Power-BI, PSPP, Minitab usw. durchführen kannst. Wenn Du dabei z.B. ChatGPT/Bing verwendest, dann erhältst Du auch Links zu relevanten Webseiten.
Die KI erledigt die Rechnung. Du kannst Deine Rohdaten übermitteln und sagen: Mache mal bitte einen t-Test mit zwei Stichproben. Das Ergebnis ist beeindruckend: Du erhältst eine vollständige Dokumentation mit Erklärungen, die Du 1:1 in Deine Trainingsunterlagen übernehmen könntest.
Lass Dich beim Coden unterstützen: ChatGPT, Bard & Co sind SPRACHmodelle und geben ihre Ergebnisse in Form von Sprache aus. Die Ausgabesprache kann durchaus auch R oder Python sein. KI kann Dir also Code für die Lösung eines Problems erstellen.
Hier als Beispiel ein „Prompt“, den Du auch selbst in ein Sprachmodell eingeben kannst:
Erstelle mir bitte eine Funktion in der Skriptsprache R [oder Python], bei der ich eine natürliche Zahl n vorgebe und die Funktion mir dann die n-te Primzahl ausgibt.
Bei Erstellung dieses Beitrags erhalte ich dafür folgendes Ergebnis, einschließlich Kommentarzeilen:
# Funktion zur Berechnung der n-ten Primzahl
primzahl <- function(n) {
# Initialisierung
i <- 2
primzahlen <- c(2)
# Primzahlen bis n iterieren
while (length(primzahlen) < n) {
# Prüfen, ob i eine Primzahl ist
if (all(i %% primzahlen != 0)) {
# i ist eine Primzahl
primzahlen <- c(primzahlen, i)
}
# i erhöhen
i <- i + 1
}
# n-te Primzahl zurückgeben
return(primzahlen[n])
}
# Beispiel
primzahl(10)
Kopieren, Einfügen. Funktioniert.
Das ist recht beeindruckend. Unter den oben genannten drei Möglichkeiten verwende ich deshalb nahezu ausschließlich den dritten Weg. In dem Seminar habe ich dargelegt, wie erstaunlich einfach das selbst für schwierigere Anwendungsfälle ist. Ich bin deshalb überzeugt:
Wenn Du viel mit Datenanalyse zu tun hast, dann solltest Du Dir die Chance nicht entgehen lassen, Dich von KI beim Coden coachen zu lassen.
Ich bin mir sicher, dass das im Laufe der Zeit noch leichter wird als es heute schon ist.
Warum Du „coden“ solltest, wenn Du Dich viel mit Datenanalyse beschäftigst
Ich sehe hier drei Gründe:
Der Algorithmus muss Dir gehören
Mit dem Code könnt Ihr, vor allem als Team, schneller lernen
Ihr könnt die Qualität Eurer Analysen ständig verbessern.
In meinen vorherigen Beiträgen habe ich das immer wieder erläutert. Ich möchte heute hier darauf verzichten. In dem heutigen Video komme ich allerdings darauf zurück.
Wir erstellen eine Animation zur Entwicklung der weltweiten Patentanmeldungen – und haben Sonderwünsche
In den Tagen nach den Seminar haben einige Teilnehmer und Teilnehmerinnen gefragt:
„Schöne Demo. Aber kannst Du mal ein ‚echtes‘ Beispiel erstellen, wie Datenanalyse per Code konkret aussieht?“
Das will ich im Folgenden tun.
Von der Sache her geht es heute lediglich um ein etwas anspruchsvolleres Balkendiagramm. Die nötigen Daten beschaffen wir uns von der Weltbank. Für ein gegebenes Jahr wollen wir die 10 Länder mit den jeweils meisten Patentanmeldungen identifizieren, diese Länder in absteigender Ordnung auf der einen Achse auftragen und auf der anderen, wie viele Patente das jeweils waren. Das kannst Du natürlich auch in Excel tun.
Danach wollen wir für jedes Jahr die erhaltenen Graphiken abspeichern und daraus eine Animation erstellen. Im Internet findest Du Webseiten, mit der Du mehrere png-Dateien zu einem „animierten Gif“ zusammenfügen kannst. Dafür muss man meiner Ansicht nach schon recht pfiffig sein. Vielleicht kannst Du auch mit Visual Basic in Excel eine Routine schreiben, die für alle 42 Jahre, für derzeit Daten vorliegen, die 10 Länder mit den meisten Anmeldungen je Jahr heraussucht, sortiert, ein Balkendiagramm dafür erstellt und dann abspeichert. Sonst musst Du das für jedes Jahr von Hand tun. Das ist möglich – aber fehleranfällig. Mit Visual Basic bist Du nun aber schon im Bereich „Coden“ unterwegs. Und warum dann nicht gleich richtig?
Denn wir noch folgende „Sonderwünsche“ an unsere Animation:
Die Skala für die Anzahl der Patente soll über die Jahre hinweg stabil bleiben, sodass das Auge leicht erkennt, wie sich die absolute Anzahl ändert („es werden jährlich mehr und mehr Patente veröffentlicht“)
Die Balken der zehn Länder des letzten vorliegenden Jahres („Situation heute“) sollen farbcodiert sein und über alle Jahre hinweg sollen diese Länder in denselben Farben dargestellt werden.
Wir möchten die Analyse gerne schnell anpassen können, wenn uns anstatt der absoluten Anzahl die Anzahl der Patente je Einwohner eines Landes oder aber der Anteil eines Landes in Prozent an den in einem Jahr weltweit veröffentlichten Patenten interessiert.
„Und dafür soll ich coden?“
Wenn Du ein Excel-Profi oder eine Power-BI-Überfliegerin bist, dann kriegst Du die heutige Aufgabe vermutlich in den Griff. Und ich sage mal: wenn Du das kannst, dann kannst Du auch das Coden erlernen, in R oder Python. Ich sehe das so: Dank Coden bist Du viel flexibler, kannst auch neuronale Netze aufbauen und diese mittels H20 online auf großen Rechnern laufen lassen. Das ist schon was… Und Du kannst Warenkorbanalysen durchführen – oder was auch immer.
Wenn Du in R / Python coden kannst, dann brauchst Du in Sachen Datenanalyse nichts anderes mehr.
Und der Code gehört Dir. Du kannst schneller Lernen. Du kannst Dein Lernen besser teilen und das Gelernte festhalten. Du brauchst auch keine online-Tools mehr, auf denen Du Dir Werbung anschauen und Cookies zustimmen musst, nur um eine Gif-Animation aus Deinen png-Files zu basteln…
Du kannst Du Dich auf alle Fälle beim Coden von künstlicher Intelligenz coachen lassen.
„Coden ist doch Aufgabe der IT. Meine Leute sollen das gar nicht können!“
Diese Aussage höre ich so oft, dass ich hier Stellung beziehen möchte. Seeleute sollen ja auch nicht schwimmen können. Die, die ich kenne, können es aber trotzdem.
Hinter dieser Aussage zur IT stehen in der Regel zwei Annahmen:
Die Sichtweise der Linienfunktion: „Coden = IT“.
Die Befürchtung der IT selbst: „Wenn irgendwo irgendein Spaghetti-Code liegt und der dann irgendwann aus irgendwelchen Gründen für irgendwen wichtig wird, dann müssen wir diesen Code am Ende auch noch warten.“
Nun, wenn das das Problem ist, dann gilt:
„Sobald Du in der Lage bist, das Problem zu formulieren, dann bist Du auch in der Lage, das Problem zu lösen“.
Diesen Satz habe ich in einem Buch von Genrich Altschuller gefunden, dem Erfinder von TRIZ. Ich möchte deshalb das Problem als TRIZ-Widerspruch umformulieren:
Ich möchte nicht, dass irgendwer außerhalb der IT auch nur eine Zeile Code schreibt, nicht einmal in Visual Basic. Deshalb haben wir diese Möglichkeit auch unterbunden. Wir tun das, damit kein Wirrwarr von nicht validiertem Code entsteht.
Ich möchte aber gleichzeitig auch, dass die Leute doch eigenen Analyse-Code schreiben. Denn ich kann ja nicht für jedes kleine Problem eine Spezialapplikation kaufen oder bei der IT einen Auftrag erstellen. In der Regel weiß ich ja zu Beginn gar nicht, ob die Analyse nur einmal gefahren wird oder ob sie sich als Standard etablieren wird. Komplizierte Excel-Dateien mit Formel-Wirrwarr und Links zu anderen Excelblättern sind ohnehin ein großes Problem.
Wenn das Dein Problem wäre, dann wäre es mit TRIZ-Ansätzen leicht zu lösen. Genug gepredigt. Nun endlich zum heutigen Thema.
Heute kannst Du mir über die Schulter schauen
Das Video, das ich unten verlinke, ist zum „Mitmachen“ gedacht. Aber auch, wenn Du einfach nur einen Eindruck gewinnen möchtest, was beim Coden auf Dich und Deine Leute zukommt, dann kannst Du es Dir anschauen. Zumindest den Anfang. Danach kannst Du selbst entscheiden, ob Du weitermachen möchtest. Der Vorteil von aufgezeichneten Videos ist ja ohnehin: Du kannst jederzeit vor- oder zurückspulen, anhalten oder auch abbrechen.
Viel Vergnügen!
Ich zeige Dir den folgenden Link an, damit Du klar erkennst, dass Du mit diesem Link meinen Blog verlässt, um die Plattform Youtube zu nutzen. Youtube hat eigene Datenschutzrichtlinien, die Du teilweise auf Deine eigenen Bedürfnisse einstellen kannst. Es kann auch sein, dass Youtube Dir vor oder während der Nutzung meines Videos Werbung zeigt. Wenn Du Deine Rechte auf Youtube nicht kennst oder nicht mit den Dir eingeräumten Rechten einverstanden bist, dann solltest Du den folgenden Link nicht verwenden.
Im letzten Eintrag habe ich mir die Fortune 500 Listen der Jahre 1955 bis 2019 vorgenommen: 65 Listen mit den jeweils 500 größten amerikanischen Unternehmen und Ihren Umsätzen, Gewinnen und Gewinnmargen. Ein wahrer Datenschatz. Wir hatten festgestellt:
Es ist immer schwerer, sich an der Spitze zu halten. Seit den 1970er Jahren ist die Wahrscheinlichkeit, von der Liste genommen zu werden, um 50% gestiegen.
Warum dieser Eintrag für Dich interessant sein könnte
Wenn Du Dich für „Marktgerechtigkeit“ interessierst (oder auch von dem Gegenteil überzeugt bist), dann solltest Du diesen Beitrag lesen. Oder Du möchtest einfach nur etwas Neues lernen und findest (so wie ich) spannend, welche Schlüsse öffentlich verfügbare Daten zulassen? – Dann los!
Vielleicht sitzt Du auch im Einkauf oder Vertrieb und suchst nach einer praktischen Kennzahl, um die „Komplexität“ Deiner Arbeit zu beschreiben? Dann habe ich heute den „Ohler Index“ im Gepäck. Du wirst sehen…
„Winner takes all“ – Wirklich?
Ich stoße manchmal auf die Sicht, dass sich die Welt immer mehr zu einem Ort entwickelt, an dem „der Gewinner alles bekommt“: Siehe den rasanten Aufstieg der FAANG-Unternehmen (Facebook, Amazon, Apple, Netflix, Google), die Dominanz von Silicon Valley oder Hollywood.
Argumente dafür, warum das so sein könnte, gibt es viele: Wer aus Globalisierung und Technologie Kapital schlagen, Netzwerkeffekte und Skalenvorteile nutzen, Plattformen schaffen, Daten und Algorithmen monopolisieren, das regulatorische Umfeld beeinflussen oder sich privilegierten Zugang zu Kapital sichern kann, wird als Sieger aus dem großen Verteilungskampf hervorgehen.
Wir würden hoffen, dass es anders wäre. Aber so ist die Welt nun einmal. Oder?
Es ist eine Sicht, der vielleicht auch Du auf die eine oder andere Weise zustimmst. Wenn das allerdings richtig wäre, dann würden die kleine Du, der kleine Ich und auch das Unternehmen am Ende der Straße kaum einen Unterschied machen können. Wir sollten uns nicht selbstständig machen, keine GmbHs gründen und uns lieber den großen Jungs und Mädels anschließen, die die vielen kleinen Unternehmen ohnehin „schlucken“ oder „plattmachen“ werden…
Ist es nicht so?
Dieser Frage wollen wir heute nachgehen. Dazu werde ich die Daten aus den Fortune 500 Listen verwenden. Und natürlich, wie sonst auch:
Wir verwenden R für unsere OSAN-Analysen
Wir betreiben „Open Source Analytics“ (OSAN) und verwenden dafür frei verfügbare Datenquellen und die Skript-, Berichts- und Webapplikationssprache R, die speziell für die Handhabung von Daten, Texten und Bildern entwickelt wurde. Du kannst Sie kostenfrei installieren. Sprachen wie R oder Python bieten Dir viele Vorteile, zum Beispiel diese:
Du hast auf einen Schlag Zugang zu den neuesten und besten Analysewerkzeugen inklusive Dokumentation.
Du kannst Dich bequem von „generativer“ künstlicher Intelligenz wie ChatGPT bei der Erstellung Deines Skripts coachen lassen.
Du kannst Deine Analysen ohne viel Aufwand ständig aktuell halten: Einmal „Run“ gedrückt und schon lädt Dein Skript wieder die neuesten Daten herunter und wertet sie für Dich aus.
Als Team ist Eure Lernkurve steiler: Anders als bei „Klicksoftware“ kannst Du Dein Vorgehen inklusive aller „Tricks und Kniffe“ in Deinem Skript festhalten. So könnt Ihr beste Praktiken leicht untereinander teilen.
Eventuelle Fehler in Deiner Analyse können von Dir oder anderen aufgespürt und korrigiert werden: Denn anhand des Skriptes können alle Dein Vorgehen genau nachvollziehen.
Wie können wir Umsätze aus dem Jahr 1955 mit Umsätzen heute vergleichen?
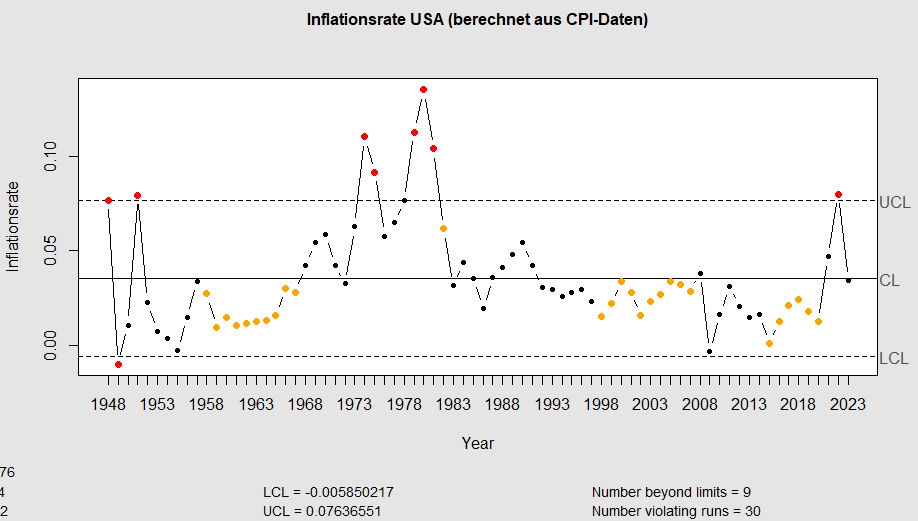
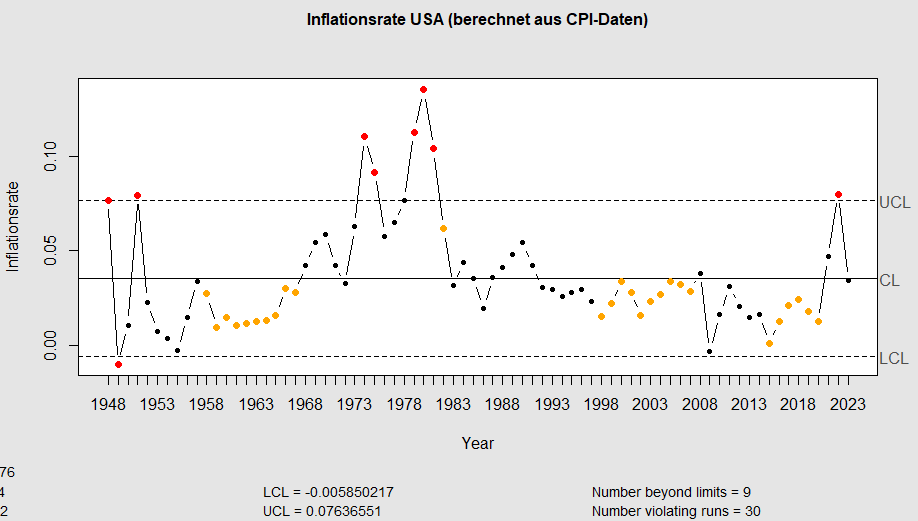
Eine Idee besteht darin, Jahr für Jahr die Umsätze von Fortune-500 Unternehmen mit der allgemeinen wirtschaftlichen Entwicklung zu vergleichen. Allerdings haben wir jeweils „nominelle“ Werte vor uns: Wegen der Inflation war ein Dollar im Jahr 1960 mehr wert als heute. Die Khan-Akademie hat einen Erklär-Artikel veröffentlicht, der diese Dinge verständlich darstellt – und auch, wie Du das rechnen kannst. Dank eines Hinweises von ChatGPT finde ich auch, wie ich die entsprechenden Daten herunterladen kann: Ein Einzeiler (im Folgenden: „CPI-Daten herunterladen“). Auf der Webseite des „Bureau for Labor Statistics“ findet sich zudem der „CPI Inflation Calculator„, mit dem Du diese Rechnung auch manuell durchführen kannst.
Im folgenden Code wird zunächst ein xts-Objekt erstellt (speziell für die Handhabung von Zeitreihen-Daten). Ich überführe dieses Objekt mittels fortify.zoo in den Dataframe CPI („Consumer Price Index“) und berechne durch den Vergleich von Jahres- und Vorjahreswerten (mit der lag-Funktion) auch die Inflation, die ich als Regelkarte darstelle:
Wir erkennen: in den letzten Jahrzehnten bis hin zum Jahr 2016 hatten die USA eine lange Phase signifikant niedriger Inflationsraten.
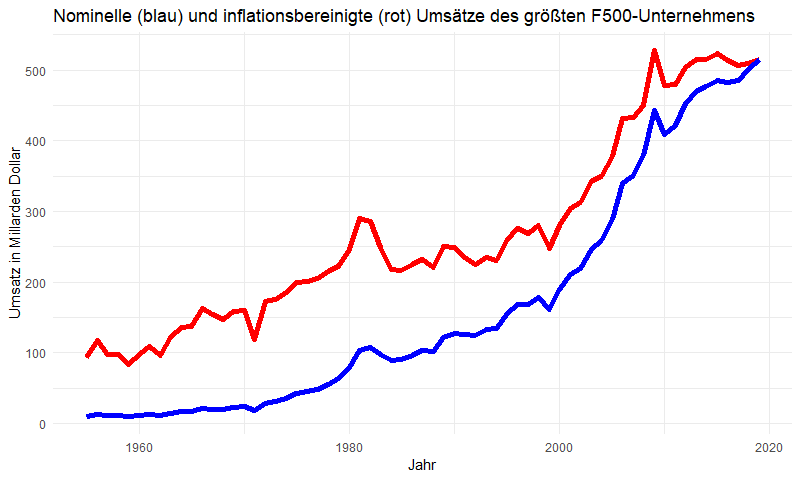
Mit diesen Daten passen wir nun die Dollarwerte an die Kaufkraft des Dollars im Jahr 2019 an. Die so angepassten Umsätze (Revenue.adj) des jeweiligen „Jahressiegers“ (Rank == 1 im folgenden Code) lassen wir uns darstellen:
t <- t %>%
left_join(CPI)
CPI_2019 <- CPI %>% filter(Year == 2019) %>% pull(CPI_mean)
t <- t %>%
mutate(Revenue.adj = Revenue/CPI_mean*CPI_2019,
Total.Revenue.adj = Total.Revenue/CPI_mean*CPI_2019,
GDP.adj = GDP/CPI_mean*CPI_2019)
ggplot(data = t %>% filter(Rank == 1)) +
geom_line(aes(x = Year, y = Revenue.adj), colour = "red") +
geom_line(aes(x = Year, y = Revenue), colour = "blue")
Es ist beeindruckend: auch die inflationsbereinigten Daten bescheinigen ein starkes Wachstum des führenden US-Unternehmens. Mit Blick auf die Eingangsfrage stellen wir fest:
Wer auch immer es ist: Der Gewinner entwickelt sich prächtig.
Wie sieht diese Entwicklung im Vergleich zur Gesamtwirtschaft aus?
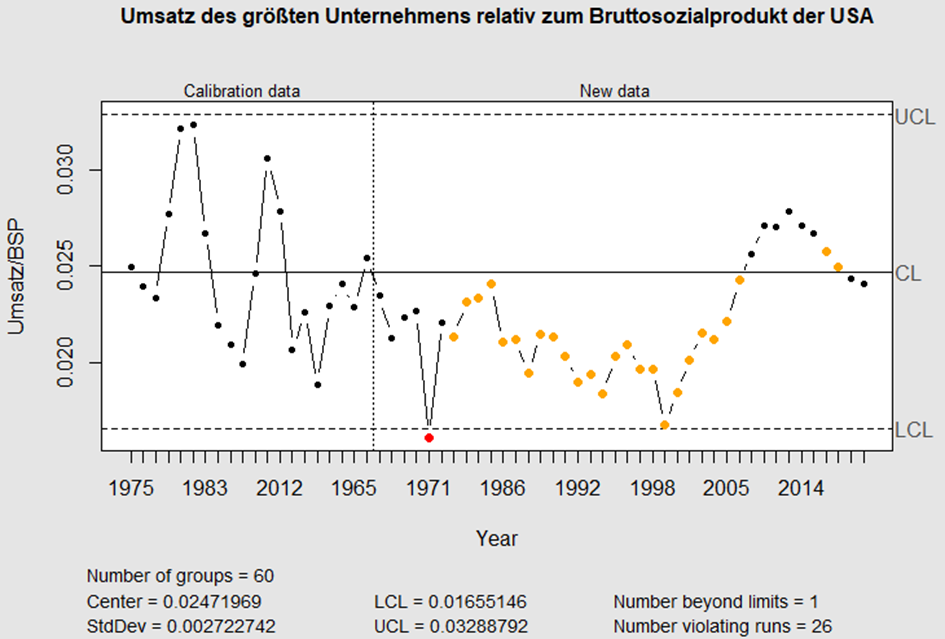
Wie ist jedoch über den gleichen Zeitraum die US-amerikanische Wirtschaft gewachsen? Denn an der Messlatte müssen wir ja auch den „Gewinner“ messen. Dafür beschaffen wir uns Daten von der Weltbank für das Bruttosozialprodukt (gezeigt im folgenden Code) und binden diese mittels left_join (nicht gezeigt) ein:
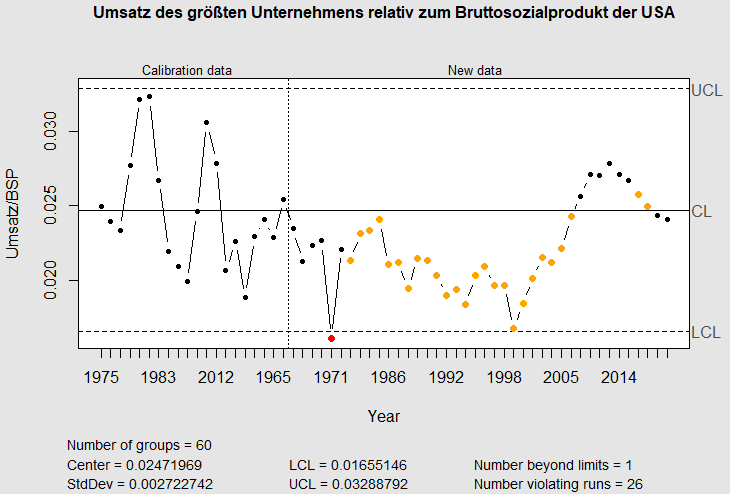
Als Regelkarte dargestellt erkennen wir: „kein Drama“.
Dafür berechne ich das Verhältnis des Umsatzes des jeweils größten Unternehmens zum Bruttosozialprodukt und kalibriere die Regelkarte mit der Entwicklung bis 1979. In den 25 folgenden Jahren war dieses Verhältnis außergewöhnlich niedrig und liegt auch in den Jahren 2018/19 wieder im Bereich des Üblichen:
Die Entwicklung des Gewinners folgt der des Gesamtmarktes.
Der „Ohler-Index“ – eine praktische Größe mit vielen Anwendungen
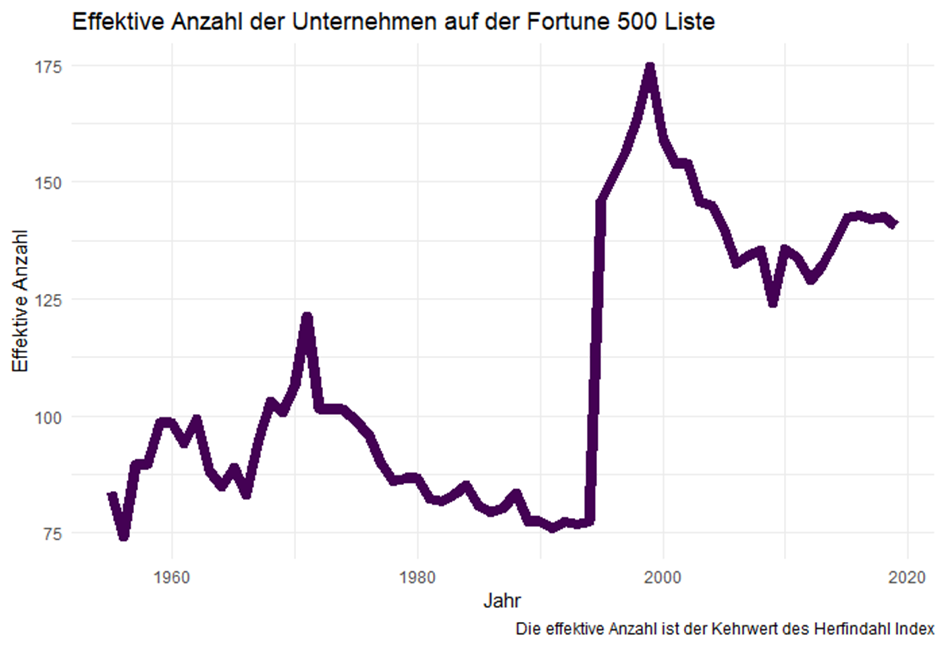
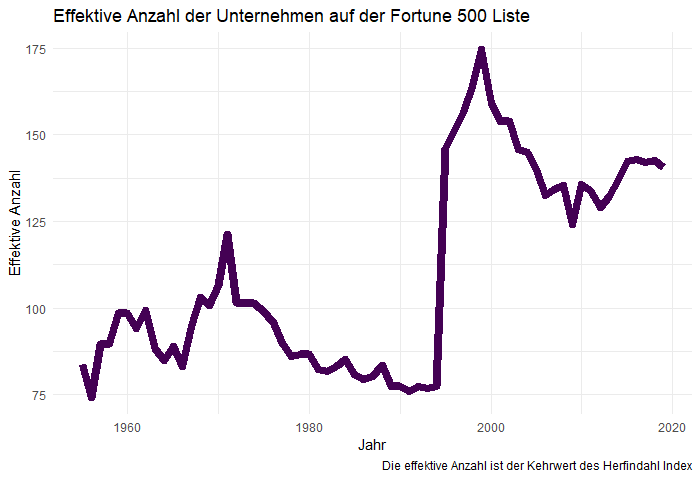
Bisher haben wir lediglich die Entwicklung des jeweils größten Unternehmens betrachtet. Jetzt möchten wir untersuchen, in wie vielen Händen sich die Umsätze aller Fortune-500 Unternehmen „konzentrieren“. Ich verwende dafür den Herfindahl-Index – allerdings mit einer Abwandlung, die dieser recht abstrakte Größe eine einfache Bedeutung verleiht.
Nehmen wir an, wir hätten drei Unternehmen, die jeweils 1/3 des Marktes (gemessen an ihren Umsätzen) für sich beanspruchen. Natürlich würden wir in diesem Fall von drei Marktteilnehmern sprechen. Wie wäre es aber, wenn zwei Unternehmen je 49% erwirtschafteten und das dritte die verbleibenden 2%? Würden wir in dem Fall auch sagen, dass sich drei Unternehmen „den Markt aufteilen“?
Den Herfindahl-Hirschman Index (HHI) berücksichtigt solche Situationen wie folgt: Im ersten Fall ergibt sich HHI = (1/3)2 + (1/3)2 + (1/3)2 = 1/3 und im zweiten HHI = (0,49)2 + (0,49)2 + (0,02)2 = 1/2,08. Ich schreibe das in dieser Form, weil der Kehrwert des Herfindahl Indexes die „effektive Anzahl“ der Marktteilnehmer wiedergibt – 3 im ersten und 2,08 im zweiten Fall.
Diese Darstellung hat praktische Anwendungen, die ich in meiner Beratungstätigkeit immer wieder einsetze:
Steigt die Anzahl Eurer Lieferanten oder Kunden? Sehr einfach: nimm die monatlichen Geldflüsse hin zu jedem Lieferanten und von jedem Kunden. Berechne nun die jeweiligen Anteile und so den Kehrwert des Herfindahl Index.
Es ist erstaunlich, dass bisher sonst niemand auf diese Idee gekommen zu sein scheint. Wenn Du möchtest, dann kannst Du diesen neuen Index – zum Spaß – gerne „Ohler-Index“ nennen. 🙂
In R sieht die Rechnung wie folgt aus (die Spalte Rev.Percent habe ich schon vorher erzeugt):
Diese Graphik ist nun reichlich erstaunlich: Im Jahr 1994 sind die Umsätze der 500 größten US-Unternehmen in den Händen von 76 „effektiven“ Marktteilnehmern konzentriert. Im Jahr 1995 schnellt diese Zahl auf 146 Unternehmen hoch und hat sich seither bei etwa 135 Unternehmen eingependelt.
Seit dem Jahr 1995 wird der „Kuchen“ unter etwa doppelt so vielen Marktteilnehmern aufgeteilt wie vorher. Die „Kleinen“ (unter den 500 Größten) scheinen ihre Chancen genutzt zu haben.
Gemeinsam mit Thomas und vielleicht auch Christian bin ich derzeit dabei herauszufinden, was sich in der US-amerikanischen Wirtschaft – oder auch nur in der Bewertung der 500 größten Unternehmen – für diesen massiven Effekt geändert haben könnte. Wenn Du den vorherigen Blog gelesen hast: in diesem Zeitraum wurden ganze 291 Unternehmen auf der Fortune 500 Liste ausgetauscht.
Melde Dich gerne, wenn Du dabei mitmachen möchtest!


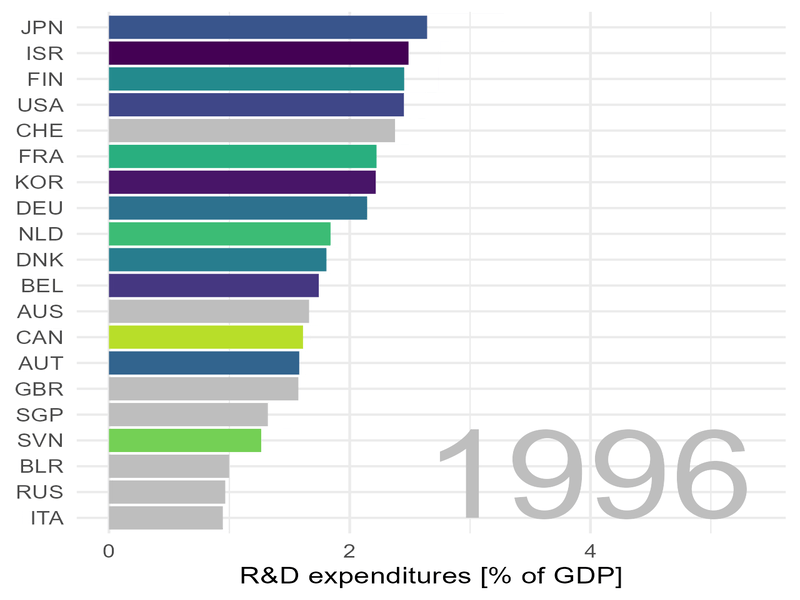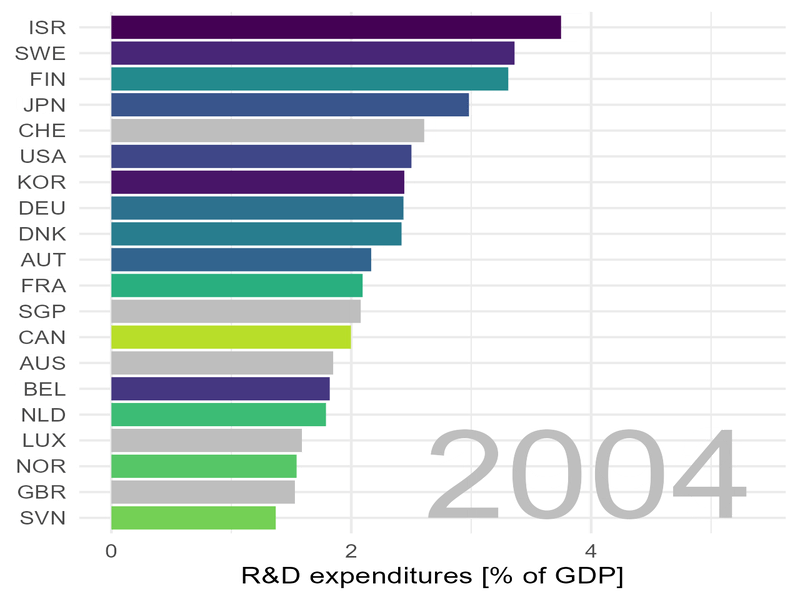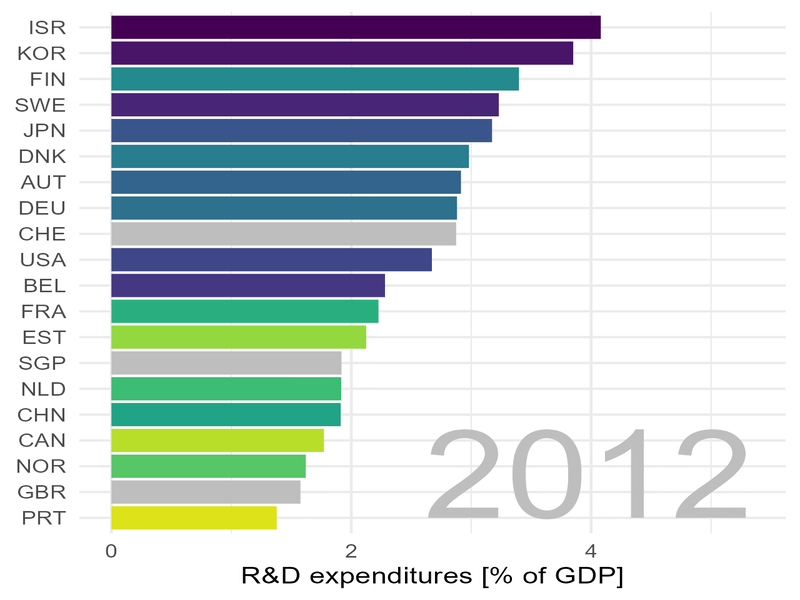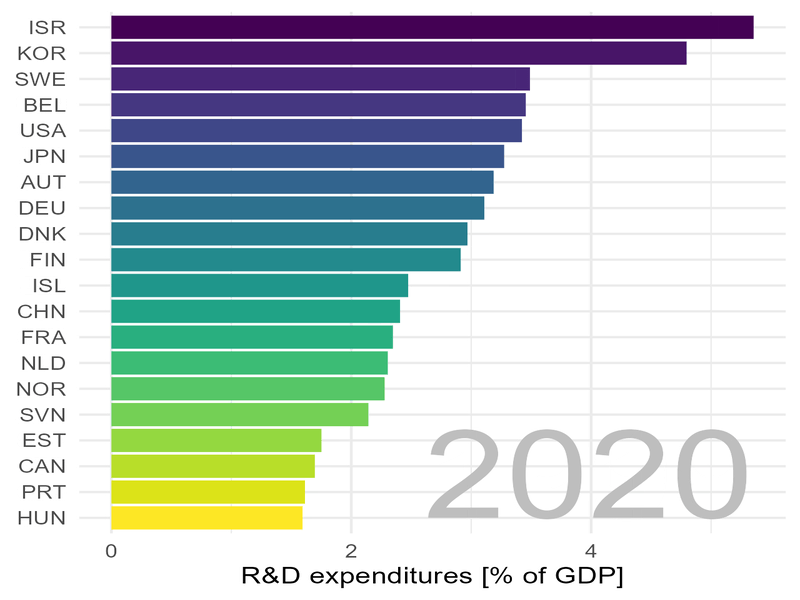
{kind=link}
{kind=link}
{kind=link}