
Im letzten Eintrag habe ich mir die Fortune 500 Listen der Jahre 1955 bis 2019 vorgenommen: 65 Listen mit den jeweils 500 größten amerikanischen Unternehmen und Ihren Umsätzen, Gewinnen und Gewinnmargen. Ein wahrer Datenschatz. Wir hatten festgestellt:
Es ist immer schwerer, sich an der Spitze zu halten.
Seit den 1970er Jahren ist die Wahrscheinlichkeit,
von der Liste genommen zu werden,
um 50% gestiegen.
Warum dieser Eintrag für Dich interessant sein könnte
Wenn Du Dich für „Marktgerechtigkeit“ interessierst (oder auch von dem Gegenteil überzeugt bist), dann solltest Du diesen Beitrag lesen. Oder Du möchtest einfach nur etwas Neues lernen und findest (so wie ich) spannend, welche Schlüsse öffentlich verfügbare Daten zulassen? – Dann los!
Vielleicht sitzt Du auch im Einkauf oder Vertrieb und suchst nach einer praktischen Kennzahl, um die „Komplexität“ Deiner Arbeit zu beschreiben? Dann habe ich heute den „Ohler Index“ im Gepäck. Du wirst sehen…
„Winner takes all“ – Wirklich?
Ich stoße manchmal auf die Sicht, dass sich die Welt immer mehr zu einem Ort entwickelt, an dem „der Gewinner alles bekommt“: Siehe den rasanten Aufstieg der FAANG-Unternehmen (Facebook, Amazon, Apple, Netflix, Google), die Dominanz von Silicon Valley oder Hollywood.
Argumente dafür, warum das so sein könnte, gibt es viele: Wer aus Globalisierung und Technologie Kapital schlagen, Netzwerkeffekte und Skalenvorteile nutzen, Plattformen schaffen, Daten und Algorithmen monopolisieren, das regulatorische Umfeld beeinflussen oder sich privilegierten Zugang zu Kapital sichern kann, wird als Sieger aus dem großen Verteilungskampf hervorgehen.
Wir würden hoffen, dass es anders wäre.
Aber so ist die Welt nun einmal.
Oder?
Es ist eine Sicht, der vielleicht auch Du auf die eine oder andere Weise zustimmst. Wenn das allerdings richtig wäre, dann würden die kleine Du, der kleine Ich und auch das Unternehmen am Ende der Straße kaum einen Unterschied machen können. Wir sollten uns nicht selbstständig machen, keine GmbHs gründen und uns lieber den großen Jungs und Mädels anschließen, die die vielen kleinen Unternehmen ohnehin „schlucken“ oder „plattmachen“ werden…
Ist es nicht so?
Dieser Frage wollen wir heute nachgehen.
Dazu werde ich die Daten aus den Fortune 500 Listen verwenden.
Und natürlich, wie sonst auch:
Wir verwenden R für unsere OSAN-Analysen
Wir betreiben „Open Source Analytics“ (OSAN) und verwenden dafür frei verfügbare Datenquellen und die Skript-, Berichts- und Webapplikationssprache R, die speziell für die Handhabung von Daten, Texten und Bildern entwickelt wurde. Du kannst Sie kostenfrei installieren. Sprachen wie R oder Python bieten Dir viele Vorteile, zum Beispiel diese:
- Du hast auf einen Schlag Zugang zu den neuesten und besten Analysewerkzeugen inklusive Dokumentation.
- Du kannst Dich bequem von „generativer“ künstlicher Intelligenz wie ChatGPT bei der Erstellung Deines Skripts coachen lassen.
- Du kannst Deine Analysen ohne viel Aufwand ständig aktuell halten: Einmal „Run“ gedrückt und schon lädt Dein Skript wieder die neuesten Daten herunter und wertet sie für Dich aus.
- Als Team ist Eure Lernkurve steiler: Anders als bei „Klicksoftware“ kannst Du Dein Vorgehen inklusive aller „Tricks und Kniffe“ in Deinem Skript festhalten. So könnt Ihr beste Praktiken leicht untereinander teilen.
- Eventuelle Fehler in Deiner Analyse können von Dir oder anderen aufgespürt und korrigiert werden: Denn anhand des Skriptes können alle Dein Vorgehen genau nachvollziehen.
Wie können wir Umsätze aus dem Jahr 1955 mit Umsätzen heute vergleichen?
Eine Idee besteht darin, Jahr für Jahr die Umsätze von Fortune-500 Unternehmen mit der allgemeinen wirtschaftlichen Entwicklung zu vergleichen. Allerdings haben wir jeweils „nominelle“ Werte vor uns: Wegen der Inflation war ein Dollar im Jahr 1960 mehr wert als heute. Die Khan-Akademie hat einen Erklär-Artikel veröffentlicht, der diese Dinge verständlich darstellt – und auch, wie Du das rechnen kannst. Dank eines Hinweises von ChatGPT finde ich auch, wie ich die entsprechenden Daten herunterladen kann: Ein Einzeiler (im Folgenden: „CPI-Daten herunterladen“). Auf der Webseite des „Bureau for Labor Statistics“ findet sich zudem der „CPI Inflation Calculator„, mit dem Du diese Rechnung auch manuell durchführen kannst.
# CPI-Daten herunterladen:
getSymbols("CPIAUCSL", src = "FRED")
# Mittelwerte je Jahr berechnen:
CPI <- fortify.zoo(CPIAUCSL, index.names = "Date") %>%
mutate(Year = year(Index)) %>%
group_by(Year) %>%
summarise(CPI_mean = mean(CPIAUCSL)) %>%
mutate(CPI_LAG = lag(CPI_mean),
Inflation = (CPI_mean - CPI_LAG)/CPI_LAG) %>%
slice(-1)
Im folgenden Code wird zunächst ein xts-Objekt erstellt (speziell für die Handhabung von Zeitreihen-Daten). Ich überführe dieses Objekt mittels fortify.zoo in den Dataframe CPI („Consumer Price Index“) und berechne durch den Vergleich von Jahres- und Vorjahreswerten (mit der lag-Funktion) auch die Inflation, die ich als Regelkarte darstelle:
c_chart <- qcc(data = CPI$Inflation, labels = CPI$Year, type = "xbar.one")
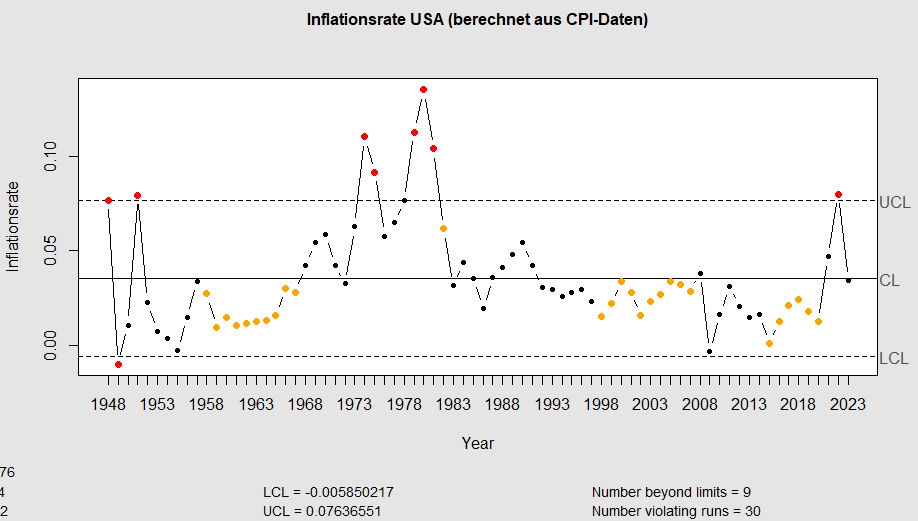
{kind=link}
Wir erkennen: in den letzten Jahrzehnten bis hin zum Jahr 2016 hatten die USA eine lange Phase signifikant niedriger Inflationsraten.
Mit diesen Daten passen wir nun die Dollarwerte an die Kaufkraft des Dollars im Jahr 2019 an. Die so angepassten Umsätze (Revenue.adj) des jeweiligen „Jahressiegers“ (Rank == 1 im folgenden Code) lassen wir uns darstellen:
t <- t %>% left_join(CPI) CPI_2019 <- CPI %>% filter(Year == 2019) %>% pull(CPI_mean) t <- t %>% mutate(Revenue.adj = Revenue/CPI_mean*CPI_2019, Total.Revenue.adj = Total.Revenue/CPI_mean*CPI_2019, GDP.adj = GDP/CPI_mean*CPI_2019) ggplot(data = t %>% filter(Rank == 1)) + geom_line(aes(x = Year, y = Revenue.adj), colour = "red") + geom_line(aes(x = Year, y = Revenue), colour = "blue")
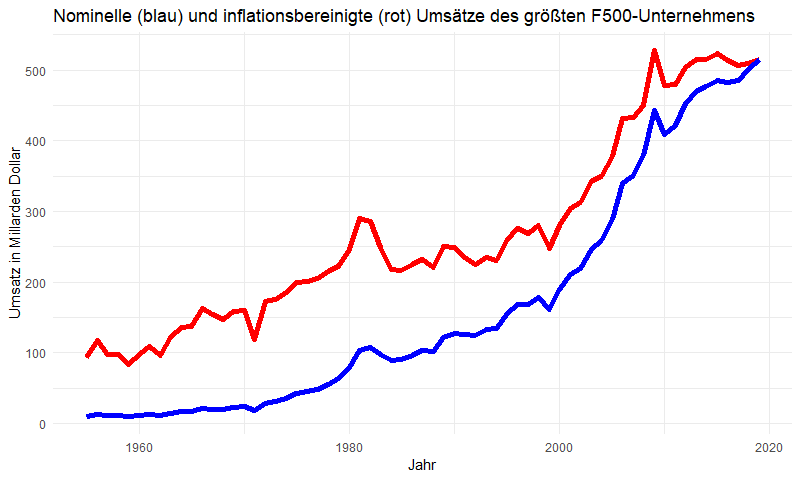
Es ist beeindruckend: auch die inflationsbereinigten Daten bescheinigen ein starkes Wachstum des führenden US-Unternehmens. Mit Blick auf die Eingangsfrage stellen wir fest:
Wer auch immer es ist:
Der Gewinner entwickelt sich prächtig.
Wie sieht diese Entwicklung im Vergleich zur Gesamtwirtschaft aus?
Wie ist jedoch über den gleichen Zeitraum die US-amerikanische Wirtschaft gewachsen? Denn an der Messlatte müssen wir ja auch den „Gewinner“ messen. Dafür beschaffen wir uns Daten von der Weltbank für das Bruttosozialprodukt (gezeigt im folgenden Code) und binden diese mittels left_join (nicht gezeigt) ein:
library(WDI) # Weltbank Daten
gdp <- WDI(indicator = "NY.GDP.MKTP.CD",
extra = TRUE) %>%
filter(iso3c == "USA") %>%
select(year, NY.GDP.MKTP.CD) %>%
rename("Year" = "year",
"GDP" = "NY.GDP.MKTP.CD")
Als Regelkarte dargestellt erkennen wir: „kein Drama“.
Dafür berechne ich das Verhältnis des Umsatzes des jeweils größten Unternehmens zum Bruttosozialprodukt und kalibriere die Regelkarte mit der Entwicklung bis 1979. In den 25 folgenden Jahren war dieses Verhältnis außergewöhnlich niedrig und liegt auch in den Jahren 2018/19 wieder im Bereich des Üblichen:
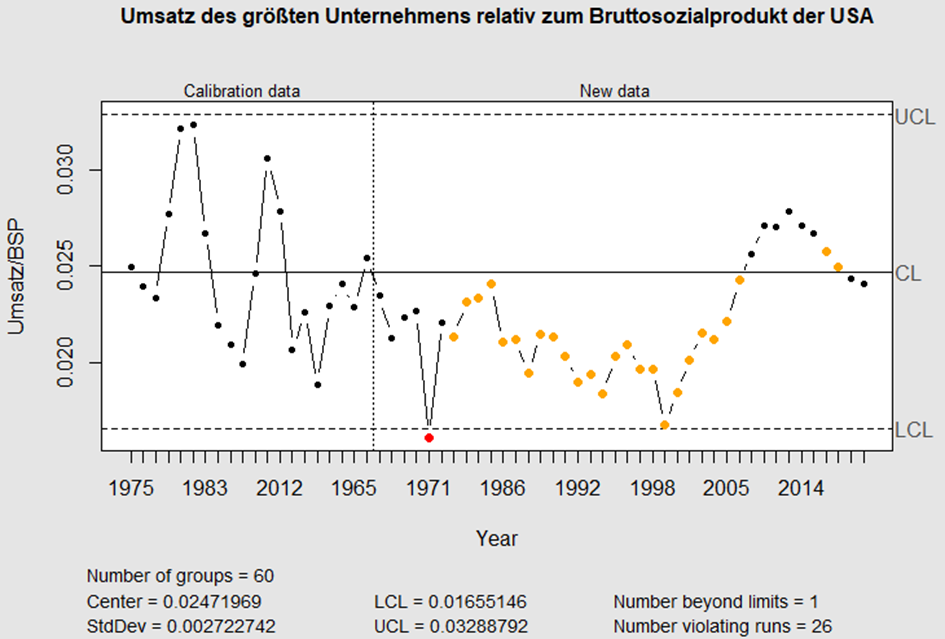
Die Entwicklung des Gewinners
folgt der des Gesamtmarktes.
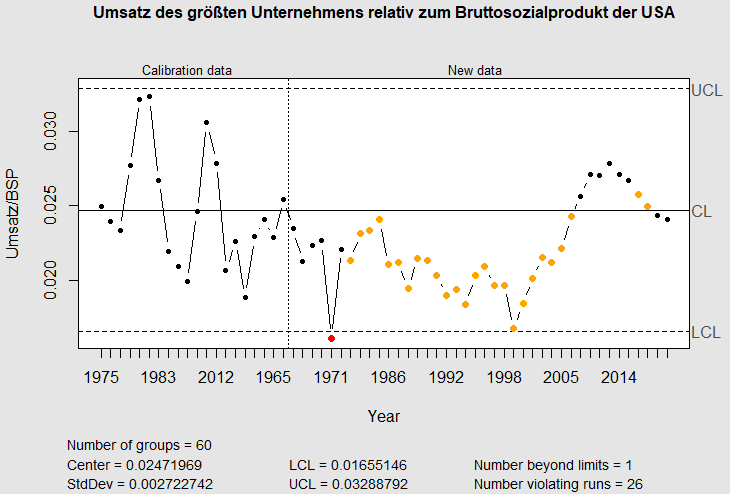{kind=link}
Der „Ohler-Index“ – eine praktische Größe mit vielen Anwendungen
Bisher haben wir lediglich die Entwicklung des jeweils größten Unternehmens betrachtet. Jetzt möchten wir untersuchen, in wie vielen Händen sich die Umsätze aller Fortune-500 Unternehmen „konzentrieren“. Ich verwende dafür den Herfindahl-Index – allerdings mit einer Abwandlung, die dieser recht abstrakte Größe eine einfache Bedeutung verleiht.
Nehmen wir an, wir hätten drei Unternehmen, die jeweils 1/3 des Marktes (gemessen an ihren Umsätzen) für sich beanspruchen. Natürlich würden wir in diesem Fall von drei Marktteilnehmern sprechen. Wie wäre es aber, wenn zwei Unternehmen je 49% erwirtschafteten und das dritte die verbleibenden 2%? Würden wir in dem Fall auch sagen, dass sich drei Unternehmen „den Markt aufteilen“?
Den Herfindahl-Hirschman Index (HHI) berücksichtigt solche Situationen wie folgt: Im ersten Fall ergibt sich HHI = (1/3)2 + (1/3)2 + (1/3)2 = 1/3 und im zweiten HHI = (0,49)2 + (0,49)2 + (0,02)2 = 1/2,08. Ich schreibe das in dieser Form, weil der Kehrwert des Herfindahl Indexes die „effektive Anzahl“ der Marktteilnehmer wiedergibt – 3 im ersten und 2,08 im zweiten Fall.
Diese Darstellung hat praktische Anwendungen, die ich in meiner Beratungstätigkeit immer wieder einsetze:
Steigt die Anzahl Eurer Lieferanten oder Kunden?
Sehr einfach: nimm die monatlichen Geldflüsse
hin zu jedem Lieferanten und von jedem Kunden.
Berechne nun die jeweiligen Anteile
und so den Kehrwert des Herfindahl Index.
Es ist erstaunlich, dass bisher sonst niemand auf diese Idee gekommen zu sein scheint. Wenn Du möchtest, dann kannst Du diesen neuen Index – zum Spaß – gerne „Ohler-Index“ nennen. 🙂
In R sieht die Rechnung wie folgt aus (die Spalte Rev.Percent habe ich schon vorher erzeugt):
# Daten aufbereiten:
herfin <- t %>%
group_by(Year) %>%
summarise(Herfindahl = sum(Rev.Percent^2)) %>%
mutate(Num.Companies = 1/Herfindahl)
# Graphik erstellen:
ggplot(data = herfin,
aes(x = Year,
y = Num.Companies)) +
geom_line()
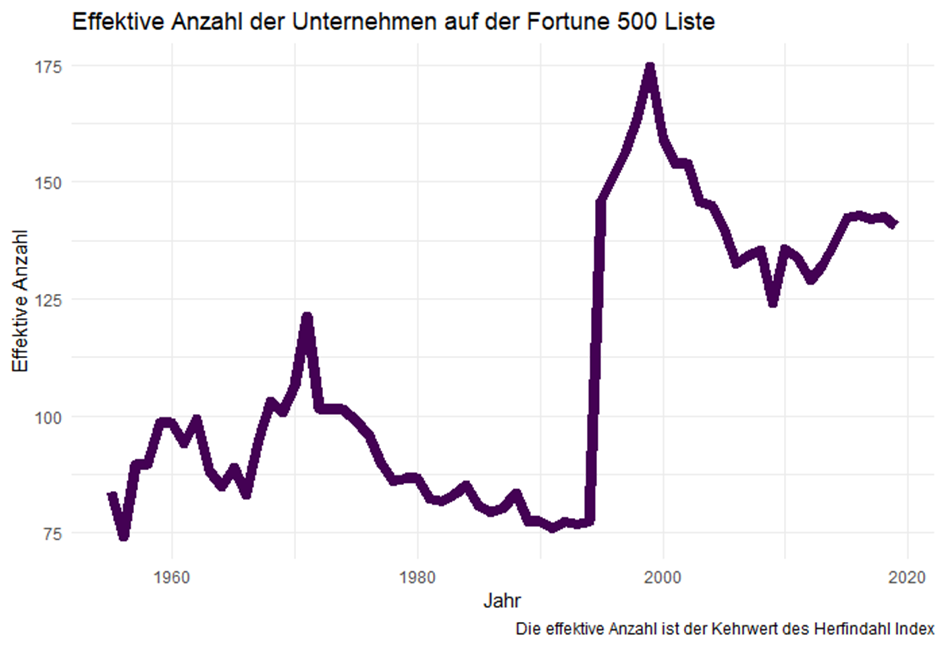
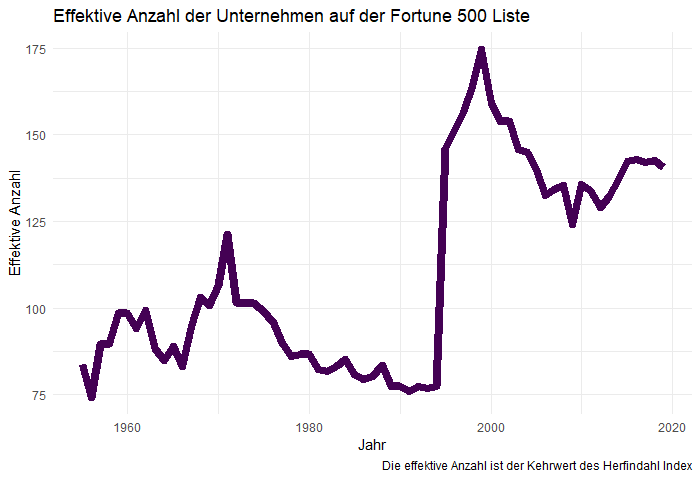{kind=link}
Diese Graphik ist nun reichlich erstaunlich: Im Jahr 1994 sind die Umsätze der 500 größten US-Unternehmen in den Händen von 76 „effektiven“ Marktteilnehmern konzentriert. Im Jahr 1995 schnellt diese Zahl auf 146 Unternehmen hoch und hat sich seither bei etwa 135 Unternehmen eingependelt.
Seit dem Jahr 1995 wird der „Kuchen“ unter etwa
doppelt so vielen Marktteilnehmern aufgeteilt wie vorher.
Die „Kleinen“ (unter den 500 Größten)
scheinen ihre Chancen genutzt zu haben.
Gemeinsam mit Thomas und vielleicht auch Christian bin ich derzeit dabei herauszufinden, was sich in der US-amerikanischen Wirtschaft – oder auch nur in der Bewertung der 500 größten Unternehmen – für diesen massiven Effekt geändert haben könnte. Wenn Du den vorherigen Blog gelesen hast: in diesem Zeitraum wurden ganze 291 Unternehmen auf der Fortune 500 Liste ausgetauscht.
Melde Dich gerne, wenn Du dabei mitmachen möchtest!